







作者:Tom Hardy
来源:自动驾驶综述|定位、感知、规划常见算法汇总
自驾车自动驾驶系统的体系结构一般分为感知系统和决策系统。感知系统一般分为许多子系统,负责自动驾驶汽车定位、静态障碍物测绘、移动障碍物检测与跟踪、道路测绘、交通信号检测与识别等任务。决策系统通常被划分为许多子系统,负责诸如路径规划、路径规划、行为选择、运动规划和控制等任务。
一、 自动驾驶汽车体系结构概述
这一部分概述了自动驾驶汽车自动化系统的典型体系结构,并对感知系统、决策系统及其子系统的职责进行了评述。
下图显示了自动驾驶汽车系统的典型架构框图,其中感知和决策系统显示为不同颜色的模块集合。感知系统负责使用车载传感器捕获的数据,如光探测和测距(LIDAR)、无线电探测和测距(雷达)、摄像机、全球定位系统(GPS),惯性测量单元(IMU)、里程表,以及有关传感器模型、道路网络、交通规则、汽车动力学等的先验信息的决策。
决策系统负责将汽车从初始位置导航到用户定义的最终目标,考虑到车辆状态和环境的内部表现,以及交通规则和乘客的舒适度。为了在整个环境中导航汽车,决策系统需要知道汽车在其中的位置。定位器模块负责根据环境的静态地图估计车辆状态(姿态、线速度、角速度等)。这些静态地图在自动操作之前自动计算,通常使用自动驾驶汽车本身的传感器,尽管需要手动注释(即人行横道或红绿灯的位置)或编辑(即移除传感器捕获的非静态物体)。自动驾驶汽车可以使用一个或多个不同的离线地图,如占用网格地图、缓解地图或地标地图,进行定位。
定位模块接收离线地图、传感器数据和平台里程计作为输入,并生成自动驾驶汽车的状态作为输出。需要注意的是,虽然GPS可能有助于定位控制器的处理,但由于树木、建筑物、隧道等造成的干扰,使得GPS定位不可靠,仅GPS在城市环境中进行适当的定位是不够的。映射器模块接收离线地图和状态作为输入,并生成在线地图作为输出。该在线地图通常是离线地图中的信息和使用传感器数据和当前状态在线计算的占用网格地图的合并。在线地图最好只包含环境的静态表示,因为这可能有助于决策系统的某些模块的操作。为了允许检测和移除在线地图中的移动对象,通常使用移动对象跟踪模块或MOT。
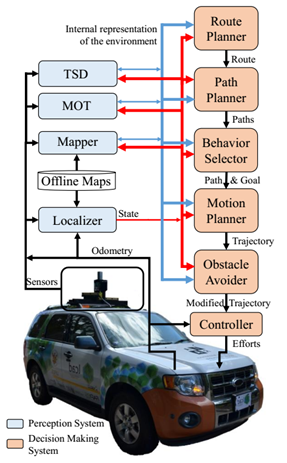
行为选择器模块负责选择当前的驾驶行为,如车道保持、交叉口处理、红绿灯处理等。行为选择器根据当前驾驶行为选择目标,并在决策时间范围内避免与环境中的静态和移动障碍物发生碰撞。运动规划模块负责计算从当前车辆状态到当前目标的轨迹,该轨迹遵循行为选择器定义的路径,满足车辆的运动学和动力学约束,并为乘客提供舒适性。
二、感知模块
在这一部分中,我们研究了文献中提出的自动驾驶汽车感知系统的重要方法,包括定位(或定位)、离线障碍物映射、道路映射、移动障碍物跟踪和交通信号检测与识别。
定位模块负责估计自动驾驶汽车相对于地图或道路的姿态(位置和方向)(例如,由路缘或道路标记表示)。大多数通用定位子系统都是基于GPS的。然而,总的来说,它们不适用于城市自动驾驶汽车,因为GPS信号不能保证在封闭区域,如树下、城市峡谷(被大型建筑物包围的道路)或隧道中。文献中提出了各种不依赖GPS的定位方法。它们主要分为三类:基于激光雷达的、基于激光雷达加相机的和基于相机的。基于激光雷达的定位方法完全依赖于激光雷达传感器,具有测量精度高、处理方便等优点。然而,尽管激光雷达行业努力降低生产成本,但与相机相比,它仍然有很高的价格。在典型的基于LIDAR+camera的定位方法中,LIDAR数据仅用于建立地图,并使用相机数据估计自动驾驶汽车相对于地图的位置,从而降低了成本。基于摄像机的定位方法是廉价和方便的,尽管通常不太精确和可靠。
1、定位
1、基于激光雷达的定位
经典方法提出了一种结合三维点配准算法的多层自适应蒙特卡罗定位(ML-AMCL)方法。为了估计汽车姿态,从三维激光雷达测量中提取水平层,并使用单独的AMCL实例将层与使用三维点注册算法构建的三维点云地图的二维投影对齐。对于每个姿态估计,对一系列的里程测量进行一致性检查。将一致的姿态估计融合到最终的姿态估计中。该方法在实际数据上进行了评估,得到相对于GPS参考的位置估计误差为0.25m。然而,地图是昂贵的存储,因为它是一个三维地图。Veronese等人提出了一种基于MCL算法的定位方法,该方法通过二维在线占有栅格地图和二维离线占有栅格地图之间的地图匹配来校正粒子的姿态,如下图所示。评估了两种地图匹配距离函数:改进了传统的两个栅格地图之间的似然场距离,以及两个高维向量之间的自适应标准余弦距离。对IARA自动驾驶汽车的实验评价表明,利用余弦距离函数,定位方法可以在100hz左右工作,横向和纵向误差分别为0.13m和0.26m。

2、激光雷达和相机方式定位
一些方法利用激光雷达数据建立地图,利用摄像机数据估计自动驾驶汽车相对于地图的位置。Xu等人提出了一种立体图像与三维点云地图匹配的定位方法。地图由一家地图公司(http://www.whatmms.com)生成,由几何数据(纬度、经度和海拔)和从里程表、RTK-GPS和2D激光雷达扫描仪获取的缓解数据组成。他们将地图的三维点从真实坐标系转换到摄像机坐标系,并从中提取深度和强度图像。采用MCL算法,通过将汽车摄像机拍摄的立体深度和强度图像与从3D点云地图中提取的深度和强度图像进行匹配来估计汽车的位置。该方法在实际数据上进行了评估,并给出了0.08 m到0.25 m之间的位置估计误差。VIS16提出了一种将地面全景图与一年中不同季节拍摄的卫星图像相匹配的自动驾驶汽车定位方法。在他们的方法中,激光雷达数据被分为地面/非地面类别。接下来,利用激光雷达数据将全景相机拍摄的自驾车地面图像分割成地面/非地面区域,然后进行扭曲以获得鸟瞰图。利用kmeans聚类将卫星图像分割成地面/非地面区域。然后利用MCL将鸟眼图像与卫星图像进行匹配,估计姿态。该方法在NavLab11自动驾驶汽车上进行了验证,获得了3m~4.8m的位置估计误差。
3、基于相机的定位方式
有些方法主要依靠摄像机数据来定位自驾车。Brubaker等人提出了一种基于视觉里程和道路地图的定位方法。他们使用OpenStreetMap,从中提取出感兴趣区域内连接他们的所有十字路口和所有可行驶道路(以分段线性段
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









