






最近做笔试题考了一道这样的选择题:
用CPU和GPU分别跑以下网络,如果时间分别为X和Y,以下哪个网络的X/Y最大?
A、AlextNet B、VGG19 C、ResNet101 D、MobileNet
仔细一想,其实就是考察哪个网络的参数最多,需要的计算量最大,其实这些网络差别还是比较大的,特别是ResNet,网络非常深,所以不需要具体的计算参数量,只需要大体的计算一个深度就可以(个人理解,可能有错误)。但是对MobileNet不是很熟悉,所以第一时间要读一下,另外就是MobileNet V2、V3版本似乎是自动学出来的?也还是蛮有兴趣。
这个名字的由来,就是因为这个网络使得CNN部署在移动端、嵌入式等设备成为了可能,因此取名“Mobile” Net。那么这篇论文是怎么减少网络参数,降低了训练的复杂度的呢?这还要从神经网络FLOPS的计算说起:
对于一个神经网络,最主要的计算来自于乘法,像是卷积层的卷积操作,和全连接层的全连接操作等,一般来说,计算神经网络的FLOPS,是忽略掉池化、激活函数和偏置这些操作的,因为其实这些操作并不会占很大的比例。(其实全连接层也没有占很大,主要来自于卷积操作)。对于一个卷积层,我们假设这一层的输入特征大小是
(
D
F
,
D
F
,
M
)
(D_{F},D_{F},M)
(DF,DF,M),输出的特征大小是
(
D
G
,
D
G
,
N
)
(D_{G},D_{G},N)
(DG,DG,N),这其中有一个维度变化,因此需要一个卷积核来执行升维(降维),卷积核大小为
(
D
K
,
D
K
,
M
,
N
)
(D_{K},D_{K},M,N)
(DK,DK,M,N),一般来说,输入输出的特征、卷积核的长和宽都是相等的。那么这层卷积的FLOPS为:
D
G
∗
D
G
∗
D
K
∗
D
K
∗
M
∗
N
(
1
)
D_{G}\ast D_{G}\ast D_{K}\ast D_{K}\ast M\ast N(1)
DG∗DG∗DK∗DK∗M∗N(1)
怎么来的呢,首先,输入图像的像素点,需要与卷积核进行卷积操作,一个像素点的卷积操作,需要的FLOPS数量为
D
K
∗
D
K
D_{K}\ast D_{K}
DK∗DK,那么一共有多少个点需要做卷积操作呢,一共有
D
G
∗
D
G
∗
N
D_{G}\ast D_{G}\ast N
DG∗DG∗N个像素点,也就是输出的每一个像素值,都是经过一次卷积操作得到的,所以最终需要
D
G
∗
D
G
∗
D
K
∗
D
K
∗
M
∗
N
D_{G}\ast D_{G}\ast D_{K}\ast D_{K}\ast M\ast N
DG∗DG∗DK∗DK∗M∗N的FLOPS,如果加上偏置,那么就需要
D
G
∗
D
G
∗
D
K
∗
D
K
∗
M
∗
N
+
D
G
∗
D
G
∗
N
D_{G}\ast D_{G}\ast D_{K}\ast D_{K}\ast M\ast N+D_{G}\ast D_{G}\ast N
DG∗DG∗DK∗DK∗M∗N+DG∗DG∗N。
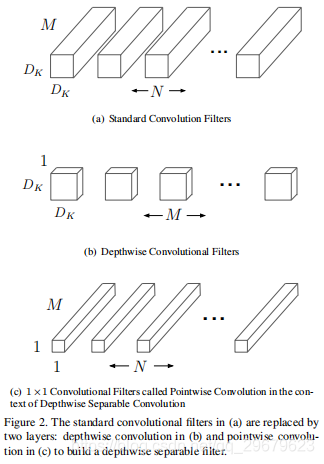
为什么要详细算一下这个公式呢,因为MobileNet是从这个公式出发,用两个超参数对这个公式进行了处理优化,使得总的公式不变的条件下,计算量大大降低。MobileNet使用了叫做Depthwise separable convolution的模块,这个模块包括两个卷积操作:一个叫做depthwise convolution,使用的卷积核大小为
(
D
K
,
D
K
,
M
)
(D_{K},D_{K},M)
(DK,DK,M),这个卷积核的作用是,输出一个与输入特征维度相同,与目标输出长宽相同的中间特征
(
D
G
,
D
G
,
M
)
(D_{G},D_{G},M)
(DG,DG,M),也就是输入特征的每一个channel(1~M),与对应的卷积核的每一个channel做卷积,计算量为
D
G
∗
D
G
∗
D
K
∗
D
K
∗
M
D_{G}\ast D_{G}\ast D_{K}\ast D_{K}\ast M
DG∗DG∗DK∗DK∗M;另一个卷积操作叫做pointwise convolution,作用是升维(降维),卷积核大小为
(
1
,
1
,
M
,
N
)
(1,1,M,N)
(1,1,M,N),计算量为
D
G
∗
D
G
∗
M
∗
N
D_{G}\ast D_{G}\ast M\ast N
DG∗DG∗M∗N(
1
∗
1
1\ast1
1∗1的卷积核常常用来做升维、降维)。那么总的FLOPS,就是两部分相加:
D
G
∗
D
G
∗
D
K
∗
D
K
∗
M
+
D
G
∗
D
G
∗
M
∗
N
(
2
)
D_{G}\ast D_{G}\ast D_{K}\ast D_{K}\ast M+D_{G}\ast D_{G}\ast M\ast N(2)
DG∗DG∗DK∗DK∗M+DG∗DG∗M∗N(2)
比较一下式(1)和式(2),
D
G
∗
D
G
∗
D
K
∗
D
K
∗
M
+
D
G
∗
D
G
∗
M
∗
N
D
G
∗
D
G
∗
D
K
∗
D
K
∗
M
∗
N
=
1
N
+
1
D
K
∗
D
K
\frac{D_{G}\ast D_{G}\ast D_{K}\ast D_{K}\ast M+D_{G}\ast D_{G}\ast M\ast N}{D_{G}\ast D_{G}\ast D_{K}\ast D_{K}\ast M\ast N}=\frac{1}{N}+\frac{1}{D_{K}\ast D_{K}}
DG∗DG∗DK∗DK∗M∗NDG∗DG∗DK∗DK∗M+DG∗DG∗M∗N=N1+DK∗DK1,可以看出完全是成倍的降低了运算量,同时卷积的输出并没有什么改变。文章提到,在第一部分使用
3
∗
3
3\ast3
3∗3的卷积核,可以降低8~9倍的计算量,同时精度只会有略微的降低。
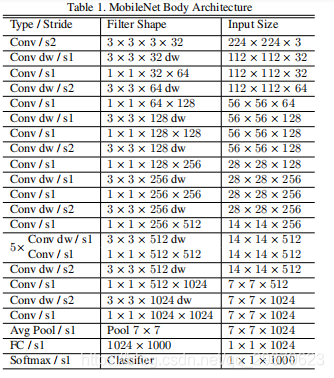
具体网络架构:
MobileNet包括了一层的传统卷积层(第一层),和一个全连接层(最后一层),这个与ResNet是一样的。剩余的都是包括两层卷积操作的Depthwise separable convolution模块,这两层卷积每一层后面都加了一个BN和Relu(第一层传统卷积层也是有BN和Relu的,但是全连接层没有,全连接层加的是softmax)。

如果一个Depthwise separable conbolution模块计算为两层卷积,那么MobileNet网络一共有28层。
有了这些之后,作者还是不满意,表示还有很多应用环境之下,要求模型需要更快,计算量更少,于是引入了第一个超参(width multiplier)
α
\alpha
α。这个
α
\alpha
α作用在channel上,是一个0~1之间的系数,每一层都使用同样的
α
\alpha
α,添加之后计算量的公式为:
D
G
∗
D
G
∗
D
K
∗
D
K
∗
α
M
+
D
G
∗
D
G
∗
α
M
∗
α
N
D_{G}\ast D_{G}\ast D_{K}\ast D_{K}\ast\alpha M+D_{G}\ast D_{G}\ast\alpha\ M\ast\alpha N
DG∗DG∗DK∗DK∗αM+DG∗DG∗α M∗αN
也就是每一层中的每一个channel,M和N之前都乘一个系数
α
\alpha
α,这个系数可以看作与剪枝、dropout相似,是为了降低模型的复杂性,抛弃一部分维度,做速度和精度的折衷。引入
α
\alpha
α后,计算量减少
α
2
\alpha^{2}
α2。
有了第一个超参,用同样的思想,很自然的就能想到去降低分辨率,也就是特征图的大小,来降低计算量。于是文章引入了第二个超参(resolution multiplier)
ρ
\rho
ρ,作用在特征图上,引入第二个超参之后,计算量:
ρ
D
G
∗
ρ
D
G
∗
D
K
∗
D
K
∗
α
M
+
ρ
D
G
∗
ρ
D
G
∗
α
M
∗
α
N
\rho D_{G}\ast\rho D_{G}\ast D_{K}\ast D_{K}\ast\alpha M+\rho D_{G}\ast\rho D_{G}\ast\alpha\ M\ast\alpha N
ρDG∗ρDG∗DK∗DK∗αM+ρDG∗ρDG∗α M∗αN
具体实现来说,就是直接把输入特征大小限制一下就可以了,比如原本输入是224×224(
ρ
=
1
\rho=1
ρ=1),我们把输入改为112*112(
ρ
=
0.5
\rho=0.5
ρ=0.5),当然后面的特征大小也都要改变。同样的,引入第二个超参可以降低模型计算量
ρ
2
\rho^{2}
ρ2。















03-01
 3071
3071
3071
03-06
1331
1331
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









