






URL
https://arxiv.org/pdf/2307.01952
TD;DR

Stability AI 7 月份发表,是一篇报告性的文章,对 SDXL 做了详细的介绍。创新点:
- 通过增加 attention 层数、引入第二个 text encoder 增加 cross attention 上下文规模,将 SD 模型的 Unet 规模扩大了 3 倍
- 提出一种后处理的 refine model 提升图片质量
- 提出多种 conditioning schemes,解决已有方法的一些问题,如输出分辨率 ratio 限制、输出 crop 问题等。
花了一大段篇幅喷 MJ ,hahhh
Model & Method
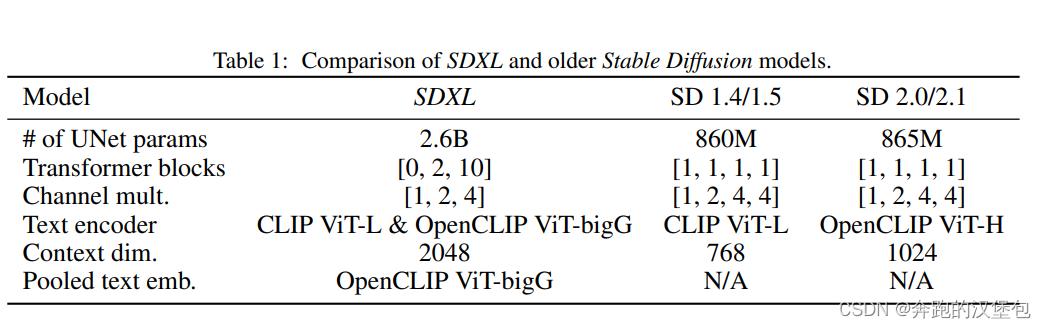
SD-XL 大幅提升了 SD 系列模型的能力,核心提升点如下:
- 提升模型参数量:主要提升在 Unet,大概有 3x 以上的参数量提升。另外 text-encoder 和 transformer block 都有扩容。
- 用一些训练策略优化了模型分辨率输出限制:
- SD 训练的时候受限于 latent space 下采样和 Unet 下采样,所以有最小分辨率的限制。已有方法要么直接丢掉小分辨率的训练图,要么对小分辨率图直接上采样,缺点见文章最末尾。作者通过把分辨率信息通过 embedding 和 text embedding concat 到一起送给模型训练,保留了分辨率信息。(这里还有一个问题,模型生成的还是原分辨率图片,知识看上去模糊了,还是说可以直接生成低分辨率图片?)
- 训练策略里的 random crop 会导致模型输出的图片带有 crop 效果。本文的做法是把 crop 左上角的坐标信息,作为 embedding 也送到网络中,这里要把整数的坐标归一化。

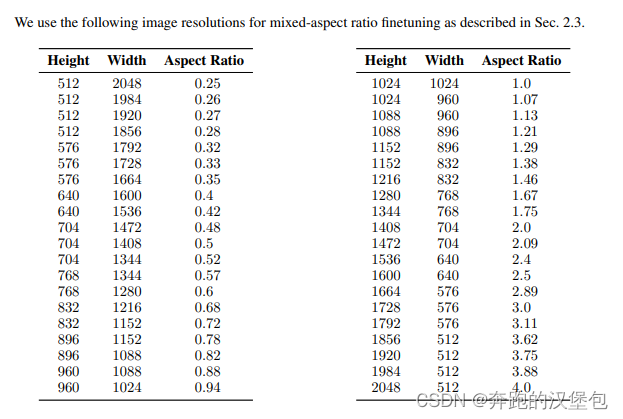
- 一个可变 ratio 的 finetune 阶段:文章表示大部分文生图模型都只对 512x512 或者 1024x1024 这种方形图片效果比较好,虽然支持其他比例但是效果并不佳。于是加入了一个变 ratio 的 finetune 阶段,但是总像素数量尽可能接近 1024x1024。
- 更好的 img encoder:使用更大 batch size 训练了一个更好的 vae
Dataset & Results
因为是一个简单的技术报告,就只给出了少量的图示。可以详见论文。
Thought
- LDM 训练通常有最小分辨率限制,因此训练的时候通常会丢弃掉一定分辨率以下的图,或者把最小分辨率 resize 到特定分辨率。前者可能会导致比较多比例的数据被丢弃,后者 upscale 的图片可能会出现不真实的纹理。
- 对 crop 的左上角坐标做 embedding 后送进网络,也只是让模型知道这个是做过 crop 的。但是 crio 以外的图还是 outpainting 来脑补的。
- SDXL 里 Unet 的第一层是没有 attn 的,导致和 sd1.5 等小模型的行为差异比较大。















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









