







# MapBench
你的在线高精地图真的可靠么?MapBench:全面分析所有SOTA算法(三星&悉尼大学)
驾驶系统通常依赖高精(HD)地图来获取精确的环境信息,这对于规划和导航至关重要。尽管当前的高精地图构建器在理想条件下表现良好,但它们对现实世界挑战的韧性,例如恶劣天气和传感器故障,尚不完全清楚,这引发了安全问题。MapBench是首个旨在评估高精地图构建方法对各种传感器损坏情况的鲁棒性的全面基准测试。基准测试涵盖了来自Camera和激光雷达传感器的总共29种损坏类型。对31个高精地图构建器的广泛评估揭示了现有方法在恶劣天气条件和传感器故障下性能显著下降,这凸显了关键的安全问题。对此,识别出增强鲁棒性的有效策略,包括利用多模态融合、高级数据增强和架构技术的创新方法。这些见解为开发更可靠的高精地图构建方法提供了途径,这对于自动驾驶技术的进步至关重要。
项目链接:https://mapbench.github.io/
领域背景介绍
高精地图是自动驾驶系统的基础组件,提供了交通规则、矢量拓扑和导航信息的厘米级细节。这些地图使自动驾驶车辆能够准确地定位自身在道路上的位置,并预测即将到来的特征。高精地图构建器将这项任务表述为预测以鸟瞰图(BEV)形式的一系列矢量静态地图元素,例如人行横道、车道分隔线、道路边界等。
现有的高精地图构建方法可以根据输入传感器的类型进行分类:仅基于camera、仅基于激光雷达以及camera-激光雷达融合模型。每种传感器都有其独特的功能:camera从图像中捕获丰富的语义信息,而激光雷达则从点云中提供明确的几何信息。
通常,基于camera的方法比仅基于激光雷达的方法表现更好,而基于融合的方法则产生了最满意的结果。然而,目前的模型设计和性能评估都是基于理想的驾驶条件,例如晴朗的白天天气和完全正常的传感器。
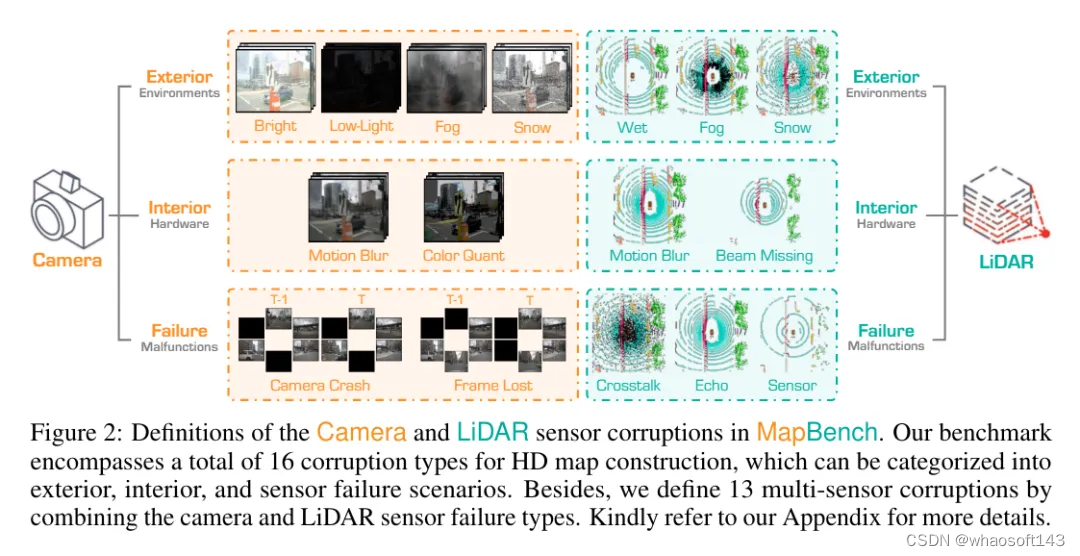
为了弥补这一差距,这里提出了MapBench,这是首个旨在评估高精地图构建方法在实际环境中对自然损坏可靠性的全面基准测试。通过研究三种流行的配置:纯视觉、仅基于激光雷达以及视觉-激光雷达融合模型,全面评估了模型在损坏情况下的鲁棒性。评估涵盖了8种camera损坏类型、8种激光雷达损坏类型以及13种视觉-激光雷达损坏组合类型,如图2和图4所示。为每种损坏类型定义了三个严重程度级别,并设计了适当的指标以进行定量鲁棒性比较。利用MapBench,对总共31种最先进的高精地图构建方法进行了广泛的实验。
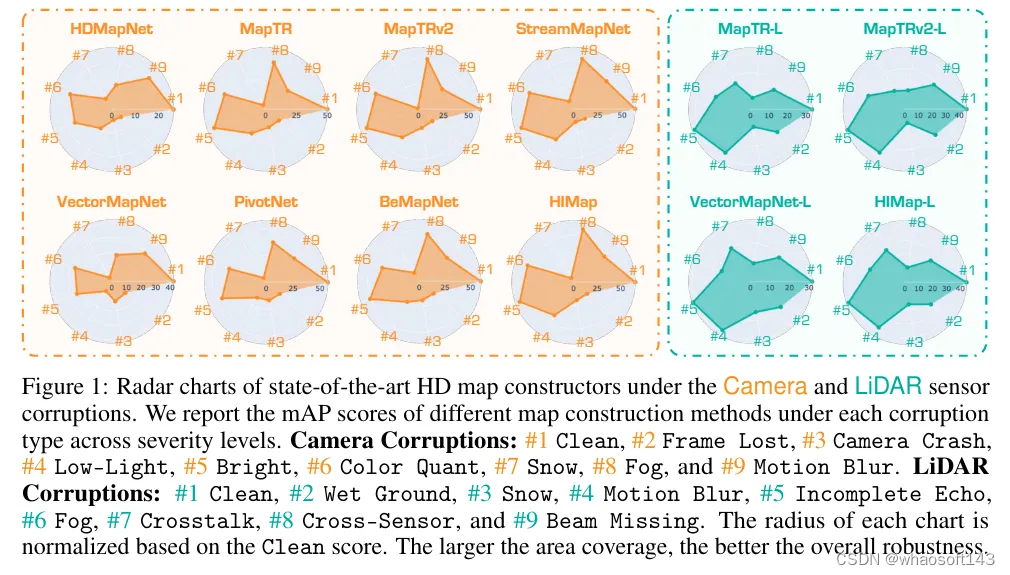
如图1所示的结果揭示了“干净”数据集和损坏数据集之间模型性能的显著差异。这些评估的关键发现包括:
-
在所有camera/激光雷达损坏情况中,雪天损坏显著降低了模型性能。它覆盖了道路,使得地图元素无法识别,对自动驾驶构成了重大威胁。此外,传感器故障损坏(例如帧丢失和回声不完整)对所有模型来说也是一个挑战,这显示了传感器故障对高精地图模型的严重威胁。
-
尽管camera-激光雷达融合方法通过结合两种模态的信息显示出了有前景的性能,但现有方法通常假设可以访问完整的传感器信息,这导致在传感器损坏或缺失时鲁棒性较差,并可能崩溃。
通过广泛的基准研究,进一步揭示了提高高精地图构建器对传感器损坏可靠性的关键因素。这项工作的主要贡献有三个方面:
-
引入了MapBench,首次尝试全面基准测试和评估高精地图构建模型对各种传感器损坏的鲁棒性。
-
在三种配置下(仅基于camera、仅基于激光雷达以及camera-激光雷达融合)广泛基准测试了总共31种最先进的高精地图构建器及其变体。这包括研究它们在8种camera损坏、8种激光雷达损坏以及每种配置下13种camera-激光雷达损坏组合下的鲁棒性。
-
确定了提高鲁棒性的有效策略,包括利用先进的数据增强和架构技术的创新方法。发现揭示了显著提高性能和鲁棒性的策略,强调了针对高精地图构建中特定挑战定制解决方案的重要性。
MapBench:高精地图构建鲁棒性基准测试
在这项工作中,研究了三种流行的配置,即仅基于camera的、仅基于激光雷达的以及基于camera-激光雷达融合的高精地图构建任务,并研究了它们对各种传感器损坏的鲁棒性。如图2所示,camera/激光雷达损坏被分为外部环境、内部传感器和传感器故障类型,涵盖了大多数真是情况。我们为每个损坏类型考虑了三个损坏严重程度级别,即容易、中等和困难。此外,对于多传感器损坏,我们使用camera/激光雷达传感器故障类型来分别或同时干扰camera和激光雷达传感器输入。MapBench是通过破坏nuScenes的验证集来构建的。选择nuScenes是因为它几乎在所有最近的高精地图构建工作中都得到了广泛应用。
1)传感器损坏
camera传感器损坏。为了探究仅基于camera的模型鲁棒性,采用了8种真实世界中的camera传感器损坏情况,这些损坏情况从三个角度进行分类:外部环境、内部传感器和传感器故障。外部环境包括各种光照和天气条件,如强光、低光、雾和雪。camera输入也可能因传感器内部因素而损坏,如运动模糊和颜色量化。最后,考虑了传感器故障的情况,即由于物理问题导致camera崩溃或某些帧丢失,分别导致camera崩溃和帧丢失。
激光雷达传感器损坏。为了探索仅基于激光雷达的模型鲁棒性,采用了中的8种激光雷达传感器损坏情况,这些损坏情况在现实世界的部署中具有很高的发生概率。这些损坏情况也分为外部、内部和传感器故障三种情况。外部环境包括雾、湿地和雪,这些条件会导致激光雷达脉冲的背散射、衰减和反射。此外,激光雷达输入可能会因不平坦的表面、灰尘或昆虫而损坏,这通常会导致干扰并导致运动模糊和光束缺失。最后,我们考虑了激光雷达内部传感器故障的情况,如串扰、可能的回声不完整和跨传感器场景。
多传感器损坏。为了探索camera-激光雷达融合模型的鲁棒性,设计了13种camera-激光雷达损坏组合,使用上述传感器故障类型分别或同时干扰camera和激光雷达输入。这些多传感器损坏被分为仅camera损坏、仅激光雷达损坏以及它们的组合,涵盖了大多数现实场景。具体来说,利用“干净”的激光雷达点数据和三种camera故障情况(如不可用camera(所有RGB图像的所有像素值都设置为零)、camera崩溃和帧丢失)设计了3种仅camera损坏情况。此外,利用“干净”的camera数据和损坏的激光雷达数据作为输入设计了4种仅激光雷达损坏情况。这包括完全激光雷达故障(由于没有任何模型可以在所有点都缺失的情况下工作,通过仅保留一个点作为输入来近似这种情况)、不完整回波、串扰和跨传感器。请注意,对完全激光雷达故障的实现接近现实情况。最后,设计了6种camera-激光雷达损坏组合,使用之前提到的图像/激光雷达传感器故障类型同时干扰两个传感器输入。
2)Evaluation Metrics
基于mAP(平均精度均值)定义了两个鲁棒性评估指标,mAP是矢量化高精地图构建中常用的准确度指标。
损坏误差(CE)。将CE定义为主要指标,用于比较模型的鲁棒性。它衡量了候选模型相对于基准模型的相对鲁棒性。给定总共N种不同的损坏类型,CE和mCE(平均损坏误差)的分数计算如下:

实验分析
候选模型。MapBench总共包含了31个高精地图构建器及其变体,即HDMapNet 、VectorMapNet 、PivotNet 、BeMapNet 、MapTR 、MapTRv2 、StreamMapNet 和HIMap 。其他一些高精地图方法的代码不是开源的,因此在本工作中不会考虑。
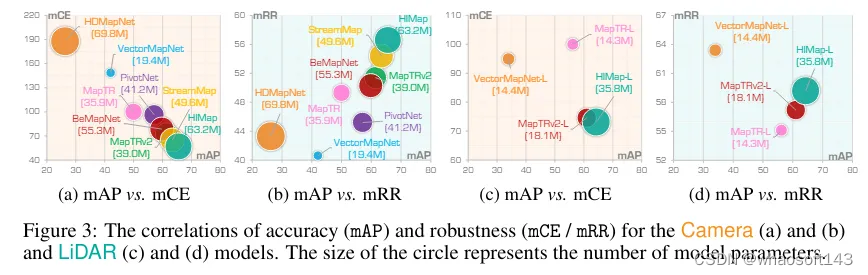
模型配置。在表1中报告了不同模型的基本信息,包括输入模态、BEV编码器、主干网络、训练周期以及它们在官方nuScenes验证集上的性能。请注意,这里的仅激光雷达模型将时间聚合的激光雷达点作为输入,因此它们在“干净”数据上的mAP远高于其他表格或图表中的值,后者使用单次扫描的激光雷达点,以便与损坏数据进行公平比较。

评估协议。为确保公平性,尽可能使用开源代码库提供的官方模型配置和public checkpoints,或者按照默认设置重新训练模型。此外,通过平均三个严重程度级别来报告每种损坏类型的指标。采用不同配置的MapTR (见表1)作为计算等式1中mCE指标的基线,因为它在最新方法中被广泛采用。
1)纯视觉基准测试结果
在图3(a)-(b)中展示了8个仅使用camera的高精地图模型在camera传感器损坏情况下的鲁棒性。发现表明,现有的高精地图模型在损坏场景下表现出不同程度的性能下降。总体来说,损坏鲁棒性与在“干净”数据上的原始准确度高度相关,因为准确度更高的模型(例如StreamMapNet 、HIMap )也表现出更好的损坏鲁棒性。我们进一步在图6中展示了仅使用camera的方法在不同损坏严重程度下的准确度比较。

基于实证评估结果,得出以下几个重要发现,可以总结如下:
1)在所有camera损坏情况中,雪对性能的影响最大,对驾驶安全构成严重威胁。主要原因是雪会覆盖道路,导致地图元素无法识别。此外,帧丢失和camera崩溃对所有模型来说也是一个挑战,这显示了camera传感器故障对仅使用camera的模型构成的严重威胁。
2)如图3(a)-(b)所示,最鲁棒的两个模型是StreamMapNet 和HIMap 。尽管它们在各种camera损坏情况下比其他研究的模型表现出更好的鲁棒性,但现有模型的整体鲁棒性仍然相对较低。具体来说,mRR的范围在40%到60%之间,而最佳模型HIMap 的mRR仅为56.6%。
2)纯激光雷达基准测试结果
在图3(c)-(d)和图6中报告了4个仅使用激光雷达的高精地图构建器的激光雷达传感器损坏鲁棒性。与仅使用camera的模型观察结果类似,在“干净”数据集上准确度更高的仅使用激光雷达的模型通常也表现出更好的损坏鲁棒性。关键要点如下:
1)在所有损坏情况中,雪和跨传感器损坏对性能的影响最大,对仅使用激光雷达的方法的鲁棒性构成严重威胁。更具体地说,雪和跨传感器损坏都导致所有仅使用激光雷达的方法性能下降超过80%。主要原因是雪会导致激光雷达数据中的激光脉冲反射。此外,跨传感器损坏表明,由不同激光雷达配置/设备引起的域差异大大降低了性能。
2)大多数模型在不完整回波损坏下的性能下降可以忽略不计。这种损坏类型主要影响来自深色车辆或物体的数据,而高精地图构建任务更关注静态地图元素。此外,尽管VectorMapNet 在mRR指标上取得了最佳性能,但与HIMap 相比,在mAP方面并不逊色。
3)Camera-激光雷达融合基准测试结果
为了系统地评估基于camera-激光雷达融合方法的可靠性,设计了13种多传感器损坏类型,这些损坏类型分别或同时干扰camera和激光雷达输入。结果如图4所示。发现表明,camera-激光雷达融合模型在不同损坏组合下表现出不同程度的性能下降。
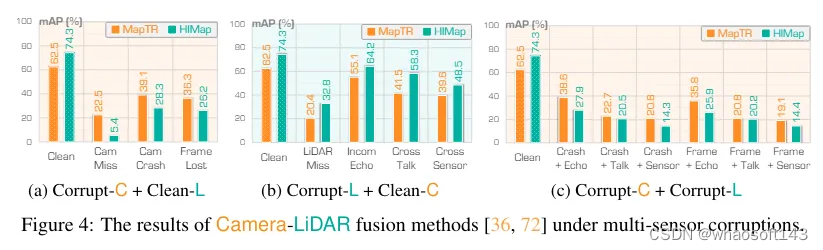
实验结果揭示了几个有趣的发现,我们提供如下详细分析:
1)在camera数据缺失的场景中,MapTR 和 HIMap 的mAP分别下降了40.0%和68.9%,对安全感知构成了严重威胁。此外,帧丢失对基于传感器融合方法的性能造成的影响比camera崩溃更为严重。这些观察结果验证了camera传感器故障对高精地图融合模型构成了重大威胁。
2)在激光雷达数据缺失的场景中,MapTR 和 HIMap 的mAP分别下降了42.1%和41.5%,这显示了激光雷达传感器的重要性。此外,激光雷达的串扰(Crosstalk)和跨传感器损坏(Cross-Sensor corruptions)对camera-激光雷达融合的性能影响最大。相比之下,激光雷达的不完整回波损坏(Incomplete Echo corruption)对模型性能的影响不大,这与仅使用激光雷达配置下的观察结果一致。
3)camera-激光雷达组合损坏导致的性能下降比其单模态对应项更糟,这凸显了camera和激光雷达传感器故障对高精地图构建任务的严重威胁。此外,无论与哪种类型的激光雷达损坏相结合,帧丢失(Frame Lost)对融合模型性能的影响都比camera崩溃(Camera Crash)更为显著,这强调了camera传感器多视角输入的重要性。在三种激光雷达损坏类型中,跨传感器损坏对融合模型性能的影响最大。即使与各种类型的camera损坏相结合,这种模式仍然保持一致,说明了跨配置或跨设备激光雷达数据输入构成的严重威胁。在图5中提供了一些在各种camera-激光雷达损坏组合下高精地图构建的定性示例,这些示例展示了在各种损坏下的性能下降。
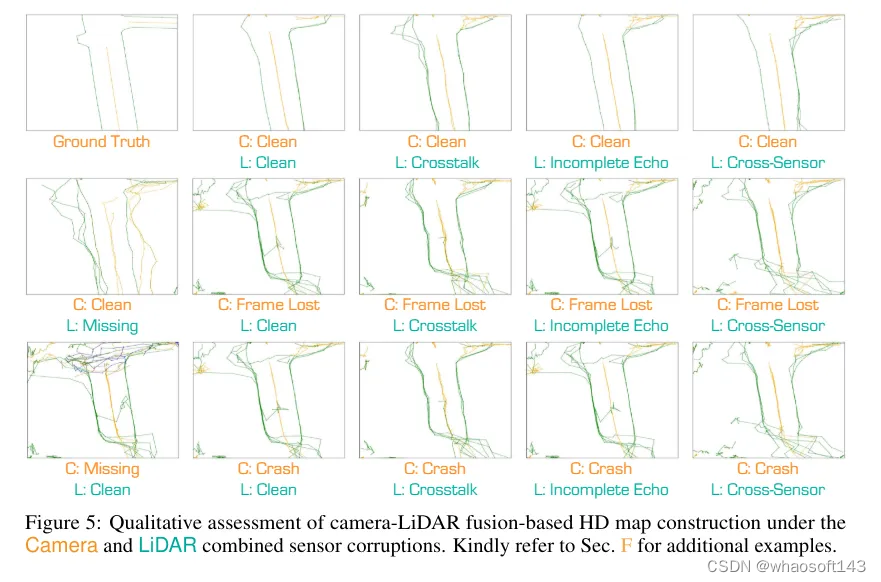 值得注意的是,尽管HIMap 在“干净”条件下的性能优于MapTR ,但在损坏情况下,其鲁棒性相对较差。这些观察结果促使我们进一步专注于增强camera-激光雷达融合方法的鲁棒性,尤其是在一种传感器模态缺失或camera和激光雷达都受损的情况下。
值得注意的是,尽管HIMap 在“干净”条件下的性能优于MapTR ,但在损坏情况下,其鲁棒性相对较差。这些观察结果促使我们进一步专注于增强camera-激光雷达融合方法的鲁棒性,尤其是在一种传感器模态缺失或camera和激光雷达都受损的情况下。
观察与讨论
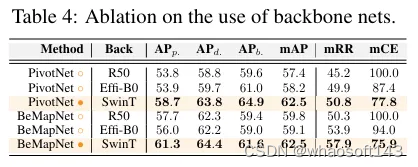
主干网络。首先全面研究了骨干网络的影响,结果如表4所示。分别在PivotNet 和BeMapNet 中使用了三种不同的骨干网络。结果显示,Swin Transformer 显著保留了模型的鲁棒性。例如,与ResNet-50 相比,Swin Transformer 骨干网络分别将PivotNet 和BeMapNet 的mCE提高了22.2%和24.1%的绝对增益。这些结果表明,较大的预训练模型往往有助于增强在域外数据下特征提取的鲁棒性。
不同的BEV编码器。研究了几种流行的2D到BEV转换方法,并在表2中展示了结果。具体来说,为仅基于camera的MapTR 模型采用了BEVFormer 、BEVPool 和GKT 。结果显示,MapTR 与各种2D到BEV方法兼容,并实现了稳定的鲁棒性性能。此外,BEVPool 的mRR结果不如BEVFormer 和GKT ,验证了基于Transformer的BEV编码器在提高高精地图模型鲁棒性方面的有效性。GKT 实现了最佳的mCE,这可能是由于它同时集成了几何和视角Transformer方法。
时间信息。研究了利用时间线索对高精地图模型鲁棒性的影响,并在表3中展示了结果。我们检查了StreamMapNet 的两个变体:一个包含时间融合模块,另一个不包含。结果显示,时间融合模块可以显著增强鲁棒性。这里的mAP结果与表1不同,因为StreamMapNet 是根据新的训练/验证集划分默认设置重新训练的,而表1中的结果则是使用旧的训练/验证集划分获得的。可以观察到,带有时间线索的模型在mRR和mCE指标上分别获得了8.4%和14.1%的绝对增益。这验证了时间融合可以在传感器损坏的情况下提供额外的互补信息,从而增强对不同传感器损坏的鲁棒性。
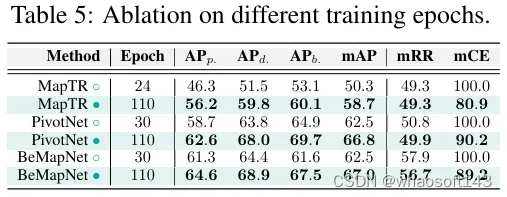
训练周期。在这个设置中,我们研究了三个使用不同训练周期训练的高精地图模型,结果如表5所示。可以观察到,更多的训练周期可以显著提高“干净”集上的性能和对损坏的鲁棒性。例如,使用更长的训练计划可以增强mCE指标的鲁棒性:MapTR (+19.1%)、PivotNet (+9.8%)和BeMapNet (+10.8%)。值得注意的是,随着训练周期的延长,这些模型在“干净”集上的性能也有所提高,这表明延长训练允许模型更好地学习数据集中的内在模式,从而在损坏的数据上实现更好的泛化性能。
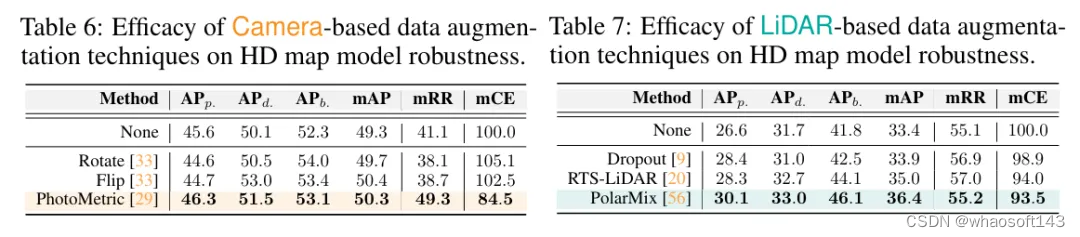
数据增强以提升损坏鲁棒性。文章研究了各种数据增强技术对高精地图模型鲁棒性的影响。由于多模态数据增强仍然是一个开放的问题,这项工作专注于研究图像和LiDAR数据增强技术的影响。这里研究了三种不同的图像数据增强方法,即Rotate 、Flip 和PhotoMetric ,以及三种不同的基于LiDAR的数据增强方法,即Dropout 、RTS-LiDAR(针对LiDAR的旋转-平移-缩放)和PolarMix 。
-
对于基于相机的数据增强,选择MapTR-R50 作为基线,并在表6中展示了结果。可以观察到,图像增强方法在“干净”集上适度提高了模型性能。然而,它们并没有一致地增强模型的鲁棒性。例如,PhotoMetric 将鲁棒性指标mRR和mCE分别提高了8.2%和15.5%,而Rotate 和Flip 则削弱了鲁棒性。这种差异可能源于PhotoMetric 对于某些类型的损坏(如亮度和低光)起到了类似于损坏增强的作用,与其他增强方法不同。
-
对于基于LiDAR的数据增强,选择MapTR-LiDAR 模型,因为它在所有仅使用LiDAR的模型中具有优越的鲁棒性。不同LiDAR增强的结果如表7所示。我们观察到,所有LiDAR增强技术都显著提高了模型在“干净”集上的性能。特别是,PolarMix 实现了3.0%的绝对性能提升。此外,所有LiDAR增强技术都有效地增强了模型的鲁棒性,使Dropout 的绝对mCE值降低了1.1%,RTS-LiDAR 降低了6.0%,PolarMix 降低了6.5%。这些结果证明了LiDAR增强方法在提高仅使用LiDAR的高精地图构建方法的损坏鲁棒性方面的有效性。
# BEVSpread
重塑路侧BEV感知!BEVSpread:全新体素化暴力涨点(浙大&百度)
基于视觉的路侧3D目标检测在自动驾驶领域引起了越来越多的关注,因其在减少盲点和扩大感知范围方面具有不可忽略的优势。而先前的工作主要集中在准确估计2D到3D映射的深度或高度,忽略了体素化过程中的位置近似误差。受此启发,我们提出了一种新的体素化策略来减少这种误差,称为BEVSpread。具体而言,BEVSpread不是将包含在截头体点中的图像特征带到单个BEV网格,而是将每个截头体点作为源,并使用自适应权重将图像特征扩展到周围的BEV网格。为了实现更好的特征传递性能,设计了一个特定的权重函数,根据距离和深度动态控制权重的衰减速度。在定制的CUDA并行加速的帮助下,BEVSpread实现了与原始体素化相当的推理时间。在两个大型路侧基准上进行的大量实验表明,作为一种插件,BEVSpread可以显著提高现有基于frustum的BEV方法。在车辆、行人和骑行人几类中,提升幅度为(1.12,5.26,3.01)AP。
开源链接:https://github.com/DaTongjie/BEVSpread
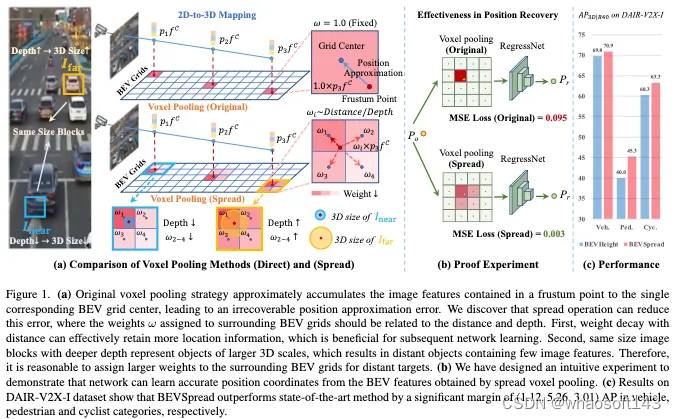
介绍
以视觉为中心的3D目标检测在自动驾驶感知中发挥着关键作用,有助于准确估计周围环境的状态,并以低成本为预测和规划提供可靠的观测结果。现有的大多数工作都集中在自车辆系统上,由于缺乏全局视角和远程感知能力的限制,该系统面临着安全挑战。近年来,路侧3D目标检测引起了越来越多的关注。由于路边摄像头安装在离地几米的电线杆上,它们在减少盲点、提高遮挡鲁棒性和扩展全局感知能力方面具有固有优势。因此,作为提高自动驾驶安全性的补充,提高道路侧感知性能是很有希望的。
最近,鸟瞰图(BEV)已成为处理3D目标检测任务的主流范式,其中基于frustum的方法是一个重要的分支,其流程如图1a所示。它首先通过估计深度或高度将图像特征映射到3D frustum,然后通过降低Z轴自由度将frustum汇集到BEV网格上。广泛的工作集中在提高深度估计或高度估计的精度,以提高2D到3D映射的性能。然而,很少考虑由体素化过程引起的近似误差。如图1a所示,预测点通常不位于BEV网格中心。为了提高计算效率,先前的工作将预测点中包含的图像特征近似累积到单个对应的BEV网格中心,导致位置近似误差,并且该误差是不可恢复的。增加BEV网格的密度可以减轻这种误差,但会显著增加计算工作量。特别是在路边场景中,由于感知范围大,计算资源有限,BEV网格只能设计得相对稀疏,以确保实时检测,这恰恰加剧了这种误差的影响。因此,我们提出了一个问题:我们如何在保持计算复杂性的同时减少这种误差?
在这项工作中,我们提出了一种新的体素化策略来减少这种位置近似误差,称为BEVSpread。BEVSpread不是将包含在截头体点中的图像特征添加到单个BEV网格,而是将每个截头体点将视为源,并使用自适应权重将图像特征扩展到周围的BEV网格。我们发现,分配给周围BEV网格的权重应该与距离和深度有关。首先,权重随着距离的衰减可以有效地保留更多的位置信息,这有利于后续的网络学习。其次,我们注意到,具有更深深度的相同大小的图像块表示较大3D尺度的目标,这导致远处的目标包含很少的图像特征。因此,为远处目标的周围BEV网格分配更大的权重是合理的。受此启发,设计了一个特定的权重函数来实现卓越的扩展性能,其中权重和距离遵循高斯分布。这种高斯分布的方差与控制衰减速度的深度信息呈正相关。特别是,BEVSpread是一个插件,可以直接部署在现有的基于截头体的BEV方法上。
为了验证BEVSpread的有效性,在两个具有挑战性的基于视觉的路边感知基准DAIR-V2X-I和Repo3D上进行了广泛的实验。在部署扩展体素化策略后,BEVHeight和BEVDepth的3D平均精度在三个主要类别中平均提高了3.1和4.0。
总结来说,本文的主要贡献如下:
-
我们指出,当前的体素化方法存在位置近似误差,严重影响了路边场景中3D目标检测的性能,而这一问题在以前的工作中被忽略了。
-
我们提出了一种新的扩展体素化方法,即BEVSpread,该方法在扩展过程中考虑了距离和深度效应,以减少位置近似误差,同时通过CUDA并行加速保持可比较的推理时间。
-
大量实验表明,作为一种插件,BEVSpread在车辆、行人和骑自行车的类别中分别以(1.12、5.26、3.01)AP的大幅度显著提高了现有基于截头体的BEV方法的性能。
相关工作回顾
近年来,鸟瞰图(BEV)为多传感器提供了统一的特征空间,清晰地呈现了目标的位置和尺度,成为自动驾驶中3D目标检测的主流范式。在本节中,我们详细介绍了BEV感知、路边BEV感知和体素化策略。
BEV感知。根据传感器类型,BEV方法主要可分为三部分,包括基于视觉的方法、基于激光雷达的方法和基于融合的方法。基于视觉的BEV方法由于其低部署成本而成为一个具有重要意义的话题,它又分为基于Transformer和基于Frustum的方案。基于Transformer的方法引入了3D目标查询或BEV网格查询来回归3D边界框。基于截头体的方法首先通过估计深度或高度将图像特征映射到3D截头体,然后通过体素化生成BEV特征。这项工作侧重于基于截头体的方法中的体素化化过程,这一过程很少被探索,但至关重要。
路测BEV感知。路测BEV感知是一个新兴领域,但尚未得到充分的探索。BEVHeight首先关注路边感知,它预测高度分布以取代深度分布。CBR侧重于设备的鲁棒性,它在没有外部校准的情况下生成BEV特征,而精度有限。CoBEV融合了以几何为中心的深度和以语义为中心的高度线索,以进一步提高性能。MonoGAE考虑地平面的先验知识。与这些方法不同的是,本文提出了一种插件来提高现有基于截头体的BEV方法的性能。
体素化策略。LSS是基于frustum的BEV方法的开创性工作,其中首次提出了体素化。大量的工作遵循这一设置。SA-BEV提出了一种新的体素化策略,即SA-BEVPool,用于过滤背景信息。而未过滤出的截头体点采用与LSS相同的体素化化方法。在这项工作中,我们重点消除LSS体素化化过程中的位置近似误差。
方法详解
网络整体框架如下图所示:
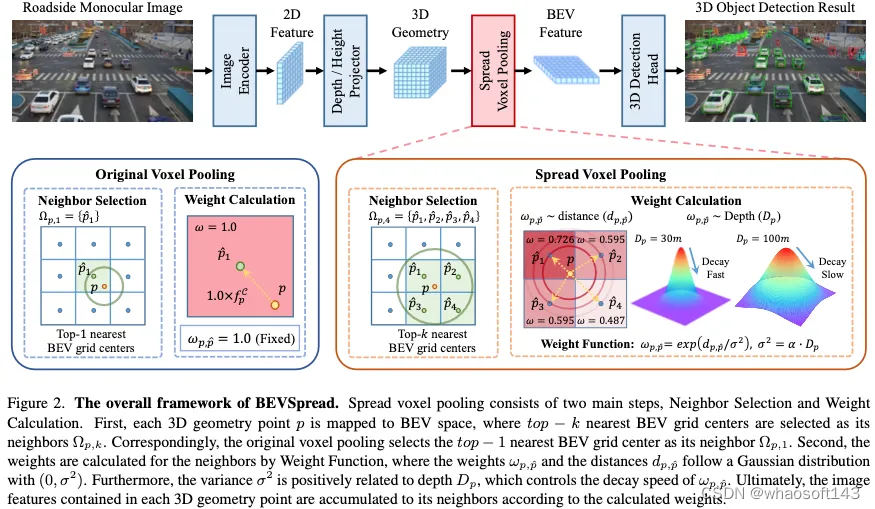

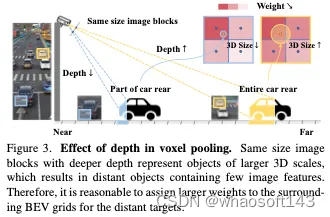
权重函数。我们发现,在传播过程中,权重应该与距离和深度有关。(a) 权重随距离衰减可以保留更多的位置信息,有利于通过后续的网络学习恢复p∈PBEV的准确位置,从而消除原始体素池化过程中的位置近似误差。此外,我们还设计了一个直观的实验来证明这一点。(b) 如图3所示,具有较深深度的相同大小的图像块表示较大3D尺度的目标,导致较远的目标包含很少的图像特征。因此,为远处目标的周围BEV网格分配更大的权重是合理的,这表明权重随着距离的推移衰减得更慢,如图2所示。
为此,我们设计了一个特定的权重函数,巧妙地使用高斯函数来整合距离和深度信息。函数定义为:
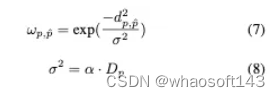
总之,扩展体素池策略的伪代码如算法1所示。

实验
本文在DAIR-V2X-I和Rope3D上展开实验。
Comparison with state-of-the-art
为了进行全面评估,我们将所提出的BEVSpread与DAIR-V2X-I和Rope3D上最先进的BEV探测器进行了比较。由于所提出的扩展体素池策略是一个插件,我们将其部署到BEVHeight,称为BEVSpread。结果描述如下。
DAIR-V2X-I的结果。表1说明了DAIR-V2X-I的性能比较。我们将我们的BEVSpread与最先进的基于视觉的方法进行了比较,包括ImVoxelNet、BEVFormer、BEVDepth和BEVHeight,以及传统的基于激光雷达的方法,包括PointPillars、SECOND和MVXNet。结果表明,BEVSpread在车辆、行人和骑自行车的类别中分别以(1.12、5.26和3.01)AP的显著优势优于最先进的方法。我们注意到,以前的方法仅在0-100m中进行训练,而DAIR-V2X-I包含0-200m的标签。为此,我们涵盖了更长范围的3D目标检测,将目标定位在0-200m内,在表1中表示为DAIR-V2X-I*。
Rope3D上的结果。我们将BEVSpread与最先进的以视觉为中心的方法进行了比较,包括在同源设置中的Rope3D验证集上的BEVDepth和BEVHeight。如表1所示,BEVSpread全面优于所有其他方法,在车辆、行人和骑自行车的情况下分别显著提高了(2.59、3.44和2.14)AP。
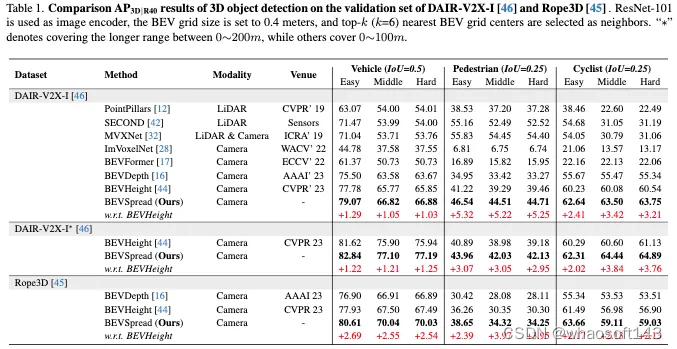
可视化结果。如图4所示,我们在图像和BEV视图中显示了BEVHeight和BEVSpread的可视化结果。在上半部分可以观察到,BEVSpread在多个场景中检测到BEVHeight未命中的目标。主要原因显示在下半部分。图像特征表明,BEVSpread将更多的注意力集中在前景区域。并且BEVSpread生成的BEV特征比BEVHeight生成的特征更平滑。BEVHeight错过了行人,因为没有相应的图像特征被投影到正确的BEV网格上。而BEV将图像特征扩展到周围的BEV网格,并准确地覆盖正确的BEV栅格,从而成功地检测到目标。

Proof Experiment for Position Recovery
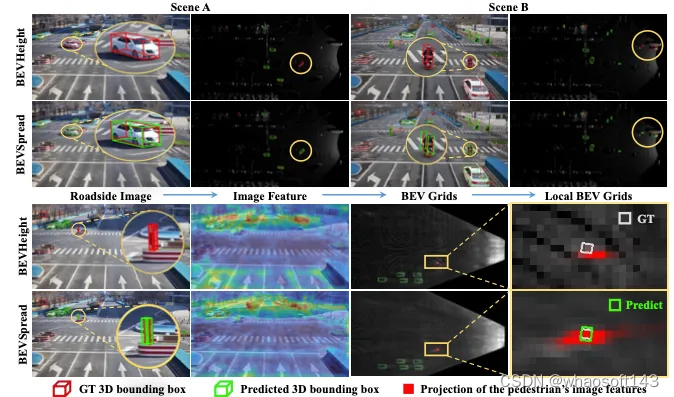
我们设计了一个直观的实验来证明所提出的扩展体素池策略可以在BEV空间中实现精确的位置恢复。最初,随机生成表示图像特征的10个C维随机矢量。然后,我们随机生成3D点,并为这10个特征进行分配。基于原始体素池和扩展体素池,将3D点投影到16×16边界元网格上,以获得边界元特征。U-Net编码器网络用于回归第一图像特征在BEV空间中的准确位置,并使用MSE损失。请注意,训练过程包含5000次迭代,并且每次迭代的批量大小设置为128。每次迭代的输入都是随机的。实验过程如图1所示。如图5所示,当邻居数量≥3时,我们的扩展体素池恢复了具有0.003 MSE损失的随机点位置,而原始体素池获得0.095 MSE损失。
消融实验
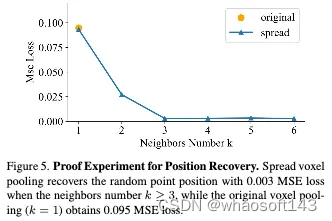
作为插件的性能。所提出的扩展体素池策略作为一种插件,可以显著提高现有基于截头体的BEV方法的性能。如表3所示,部署到BEVDepth[16]后,性能在三个类别中显著提高了(4.17、8.93和8.2)AP。在部署到BEVHeight[44]后,性能在三个类别中提高了(1.55、5.58和7.56)AP。值得注意的是,儿科医生和自行车手的识别能力有了很大提高。
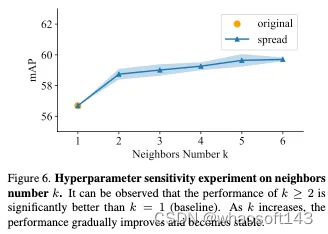
邻居选择分析。图6显示了三个类别的mAP如何随着邻居数量k而变化。对于每个超参数选择,我们重复3次,浅蓝色区域表示误差范围。可以观察到,k≥2的性能明显优于k B11(基线)。随着k的增加,性能逐渐提高并变得稳定。
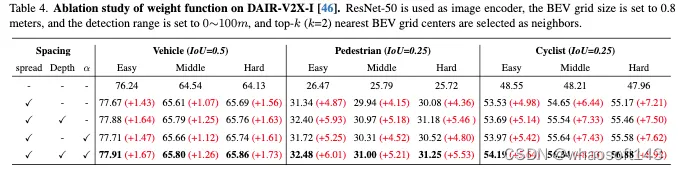
权重函数分析。我们在表4中验证了权重函数的深度和可学习参数α的有效性。在三个主要类别中的改进证明了深度和可学习参数α的应用允许更好的扩展性能。两者兼而有之时,中等难度的三个类别的综合表现分别为65.80%、31.00%和56.34%。
对不同骨干的分析。我们使用不同的主链进一步比较了BEVSpread和BEVHeight。ResuNet-50/101的结果列于表1和表3,ConvNeXt-B的实验列于表5。结果表明,更强的主干会带来更高的性能,我们的方法可以进一步提高它。

Limitations and Analysis
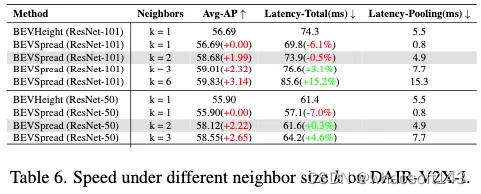
所提出的扩展体素池带来了一定的计算量,导致延迟增加。虽然我们的方法可以灵活地通过调整扩展范围来平衡精度和速度,扩展范围表示为相邻大小k。如表6所示,当k=2时,BEVSpread仍然在没有延迟增加的情况下实现了Avg AP的显著改进,这得益于我们的CUDA优化。此外,这些扩散点的坐标在本版本中是在线计算的。在实际部署阶段,BEVSpread可以使用类似于BEVPoolv2的预处理查找表来增强加速。
结论
在本文中,我们指出了当前体素池化方法中的一个近似误差。我们提出了一种称为BEVSpread的新的体素池策略来减少这种误差。BEVSpread将每个截头体点视为一个源,并使用自适应权重将图像特征扩展到周围的BEV网格。此外,还设计了一个特定的权重函数,用于根据距离和深度动态控制衰减速度。在DAIR-V2X-I和Rope3D中的实验表明,BEVSpread显著提高了现有基于截头体的BEV方法的性能。
# 自动驾驶挑战赛Mapless Driving
CVPR 2024 Autonomous Grand Challenge Track Mapless Driving无图智驾赛道的任务是检测车道线和交通元素(红绿灯、道路标牌等),并且推理车道之间、车道与交通要素之间的拓扑关系。在线建立局部高精度地图,从而摆脱自动驾驶对高精地图(HD)的依赖。比赛基于OpenLaneV2数据集进行。
无图自动驾驶和扩城,是2023年各大厂商主要卷的方向。在CVPR 2023自动驾驶挑战赛中,无图自动驾驶包含两个赛道:OpenLane Topology和Online HD Map Construction。今年的比赛相比去年的比赛相比,数据增加了标清地图(SD Map)。因此,今年的方案相比去年方案主要的改进就是将SD Map信息输入模型。
今年比赛的前三名被中国的队伍包揽。
论文解读
#1 LGmap: Local-to-Global Mapping Network for Online Long-Range Vectorized HD Map Construction
今年的冠军LGmap提出三个创新点:首先,提出了对称视图变换(symmetric view transformation, SVT)。克服了前向稀疏特征表示的局限性,利用深度感知和SD Map先验信息的。其次,提出了层级时序融合(hierarchical temporal fusion, HTF)。它利用局部和全局的时序信息,有利于为构建具有高稳定性的远距离的HD Map。最后,提出了一种新的人行横道重采样方法。简化的人行道表示方法加快模型收敛性能。
Diagram
论文的框架图如下图:
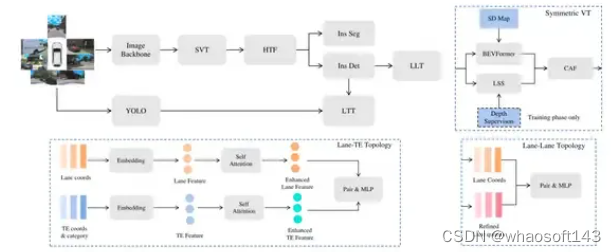
LGmap流程图
Encoder
输入图片首先经过Image Backbone,提取特征,得到PV(perspective view)特征。经过论文提出的SVT,转为BEV特征。所谓SVT,就是同时使用前向投影方法Lift-Splat-Shoot(LSS)和反向投影方法BEVFormer进行特征转换。LSS部分,使用激光雷达点云提供的深度作为监督。在BEVFormer部分,在SD map的polyline采样固定数量的点,编码成sinusoidal embedding,与图像特征进行cross attention,应该是跟SMERF方法一致。LSS和BEVFormer得到的BEV特征用channel attention模块进行融合。
Decoder
有两个并行的decoder,分别是instance-wise detection decoder和segmentation decoder。instance-wise detection decoder负责输出待检测的目标。segmentation decoder起辅助作用,加快收敛。
Temporal fusion
论文考虑时序信息,提升远距离建图的准确性。提出HTF,实际是将streaming和stacking结合的方式。所谓streaming是指RNN的范式,将信息通过memory进行传递;而stacking就是直接将信息拼接。作者提出了streaming-streaming和streaming-stacking两种方式供选择。
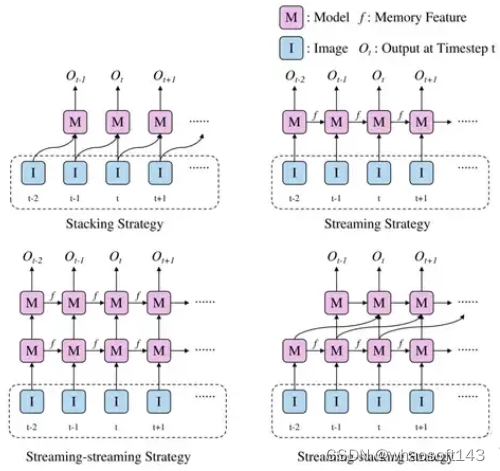
Streaming和stacking组合的hierarchical temporal fusion模块
Loss
总共考虑了4个loss。第一,跟随MapTR,point2point loss和edge direction loss;第二,跟随MapTRv2,segmentation loss和depth prediction loss;第三,BEV instance segmentation loss;第四,跟随GeMap,geometric 3D loss。
Area
针对人行横道,MapTR是是采用20个点均匀间隔采样。本文则是受到Machmap的启发,首先用采样4个顶点,然后再用每条边都为6个点的均匀采样。这样本文比MapTR的采样点简单很多,以20个点为例,MapTR有40种等效排列,而本文只有8中等效排列。这样可以加速收敛速度。

MapTR, MachMap和本文LGmap的人行横道建模方式对比
Traffic elements
采用YOLOv8和YOLOv9,检测交通元素,在OpenLaneV2,就包括红绿灯和道路标牌。
Lane-Lane topology
跟随TopoMLP,将已经输出的centerline坐标经过MLP再变成embedding,与经过训练的refined query结合,再经过MLP,输出车道线之间连接关系的二分类结果。
Lane-Traffic topology
本文的这部分是和检测模型分离的。Lane-Traffic topology模型是用lane segments的和traffic elements的真值训的。lane segments和traffic elements过embedding层得到特征,再经过self attention,得到加强特征,再过MLP进行二分类。
Ablation Study
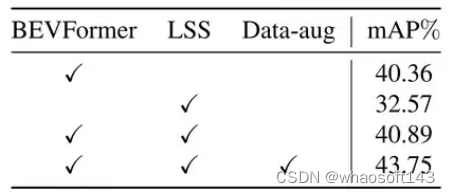
Encoder部分,增加LSS仅提高了0.5%,作用不大。BEVFormer是主力。
时序融合模块,使用Streaming-Stacking模块,比Streaming高0.5%。Streaming比baseline高3%,主力是Streaming。
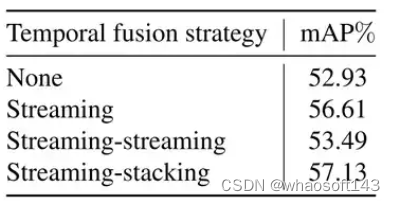
用新的人行横道编码方式,可有提高约1%。

#2 Leveraging SD Map to Assist the OpenLane Topology
本文设计了一种紧凑的transformer-based结构,用于SD map encoding and integration,充分利用SD map已经包含的基础道路拓扑结构。此外,提出一种动态位置编码(dynamic positional embedding)机制,提升decoding performance。
Model Architecture
论文没有给出总体框架图。总体框架属于常规的套路。
首先,经过图像backbone得到PV feature,再经过BEVFormer得到BEV feature。其次,基于BEV feature,建立一个SD map encoder来提取SD map的特征。接下来,过lane decoder以及,得到lane的检测结果。最后,接上 topology模型,topology模型是decoupled的。
SD Map Encoder
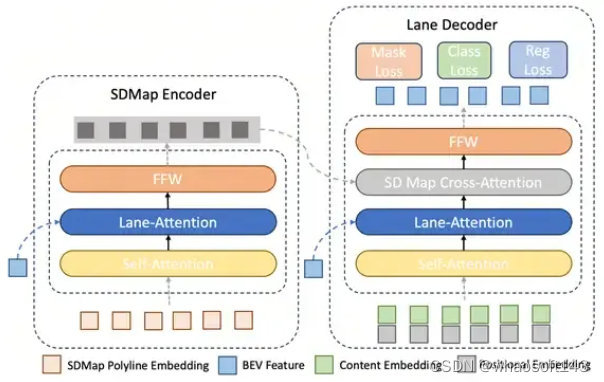
SD map Encoder和Lane Decoder的示意图
首先对SD map进行编码,方法跟LGmap基本上一致。针对SD map里面的M条polylines,每条polyline均匀取N个点。对这些点进行sinusoidal embeddings:

在SDMap Encoder里,先做一次self attention,再做一次cross attention,k, v是BEV features。这里选择用LaneSegNet提出的Lane Attention操作。
Lane Decoder
Content embedding和positional embedding作为query输入Lane Decoder,先进行一个self attention,再接一个Lane Attention与BEV features进行交互,再接一个cross attention跟SD map embedding进行交互。
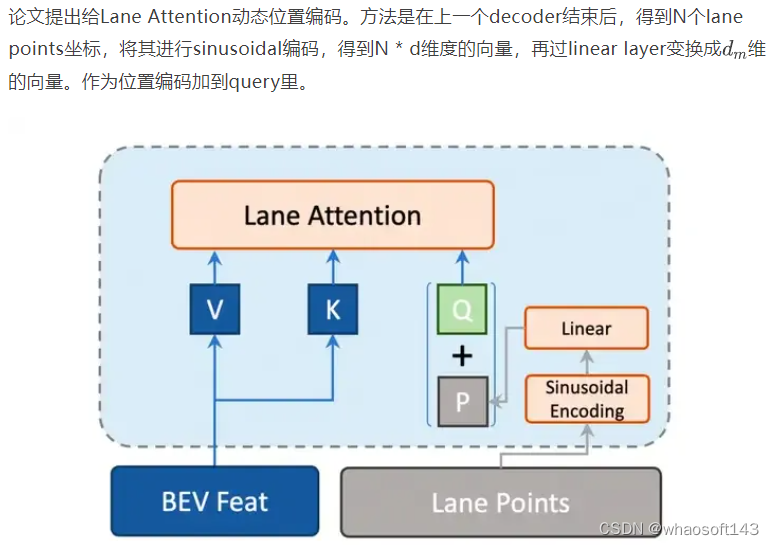
Lane Decoder中动态位置编码示意图
Topology Prediction
与LGmap类似,论文也将topology prediction和detection任务分离了。论文说的原因是因为样本不平衡,positive(associated elements)和negative(non-associated elements)极度不平衡。
将detection模型输出的结果,输入MLP,进行二分类预测。在lane-lane topology中,考虑lane的起点和终点的距离。在lane-traffic topology,用traffic element的bbox和front view摄像机外参进行编码。
#3 UniHDMap: Unified Lane Elements Detection for Topology HD Map Construction
第三名是去年的冠军团队,也就是TopoMLP的作者团队。今年提出了一套unified detection framework,检测车道线,人行横道和道路边界,其中融入了SD map信息。和去年一样,traffic elements还是用YOLOv8检测,topology prediction还是用MLP。
Diagram
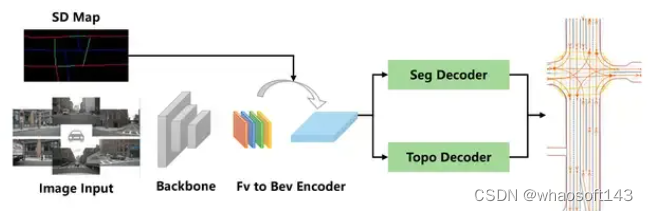
UniHDMap流程图
BEV Feature Extraction
跟第二名的方案基本一样,都是SMERF的特征提取框架,把SD map的信息融入。
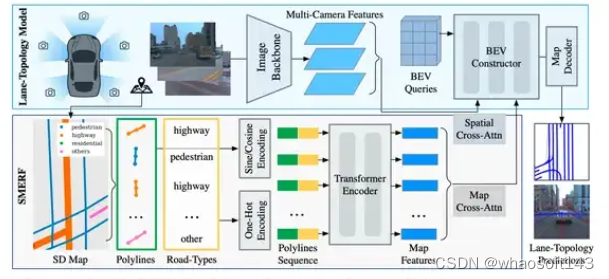
SMERF算法流程图
Lane and Area Detection
直接采用了LaneSegNet的detection部分。
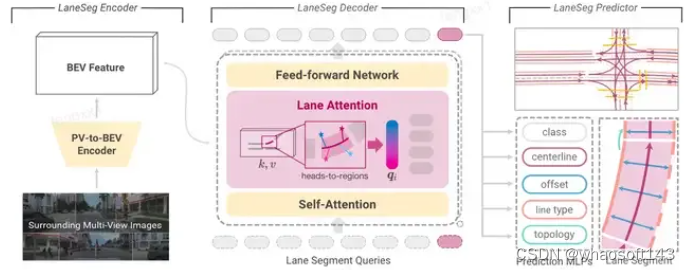
aneSegNet算法流程图
Traffic Detection和Topology Prediction都跟去年的TopoMLP方法一样。之后会专门写一篇TopoMLP的解读文章。
#6 MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
论文引入了SD map encoder的pre-training,提高模型的几何编码能力。利用YOLOX来提高traffic element detection。另外,对area detection,引入LDTR和辅助任务,提高精度。
Diagram
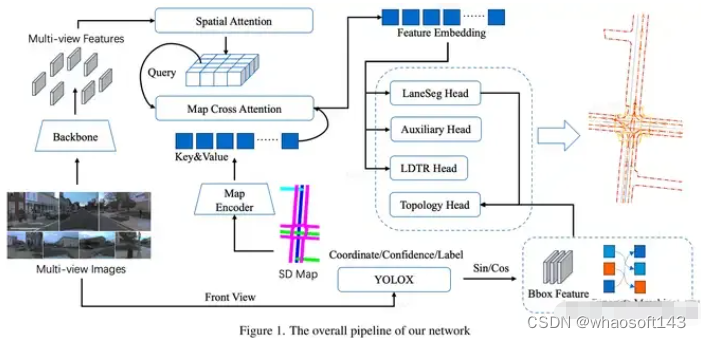
MapVision算法流程图
SD Map Encoding
Encoder的框架跟随SMERF。为了增强SD Map Encoder几何结构的编码能力,论文提出了对其进行预训练。使用AutoEncoder进行预训练,将feature sinusoidal embedding作为ground truth。在encoder后加一个轻量化的decoder,进行预测。用L2 loss进行监督。涨点大概在2%左右。

Area Detection
跟随MapTR得方式进行检测。但是,论文认为MapTR采用keypoint的方式进行编码,降低了instance的整体性。因此,受到LDTR得启发,采用anchor-chain的编码方式。
Traffic Detection和Topology Prediction跟前面的论文基本一致。
总结
CVPR 2024无图智驾赛道榜单前几名的模型框架基本一致。相比去年,也没有颠覆性的创新,主要改进在于以下几点:
-
引入了SD Map作为信息输入,采用SMERF提出的框架将其融入到transformer encoding里;
-
引入时序信息,预测提高远处的建图精度,提出采用streaming-stacking的方式;
-
对Area Detection的编码方式,提出了一些改进,更好地适应Area这个instance的特性;
-------
Taobao 天皓智联 whaosoft aiot http://143ai.com
















 3906
3906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









