






RAG介绍
1.什么是RAG
检索增强生成(RAG)是一种复杂的自然语言处理方法,它包括两个不同的步骤:信息检索和生成语言建模。这种方法旨在为语言模型提供访问外部数据源,来提高其在生成响应时的准确性和相关性,从而增强语言模型的能力。
1)检索:用收到的query去库里查到最相关的文档或者上下文
2)生成:把以上得到的内容输入给LLM,LLM通过理解和结合,整理回答出问题的答案。

参考 https://mp.weixin.qq.com/s/mn0MilYoyV0Df_7SXnuY2g
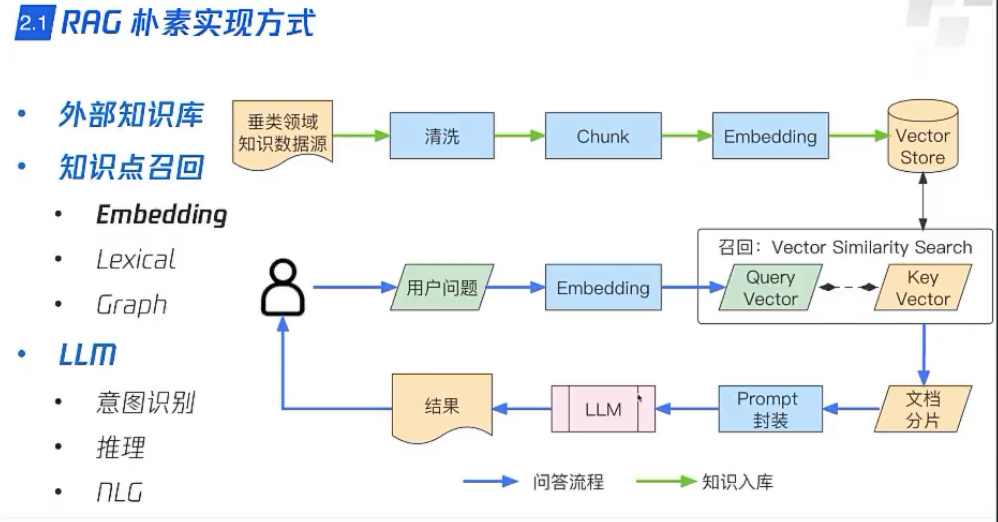
2.什么是高级RAG
高级检索增强生成(Advanced RAG):对传统RAG增加复杂的 检索前 和检索后 过程。
检索后:增加ReRank”,对检索到的文档重新排序,来考虑最相关的信息。排序方式基于 文档多样性 或者 查询相关性。
RAG的优化方法
从RAG步骤来,每个步骤都考虑可能的优化
1,提取模块
优化内容的提取包括pdf提取,图片内容(OCR识别),表格内容的提取
2.切割分片模块
.优化chunking。固定长度切分发,按句子切分,使用spacy分词等
3.embedding模块
embedding模型的选择
4.向量存储模块
一些prompt的优化,元数据存储等
5.召回模块
ReRank:很有效的优化
方法:增加top-k的大小,从原来的10个,增加到30个。再使用精确的算法来做rerank。使用计算打分的方式,做好排序
6.混合检索
步骤1:BM25快速获取带有搜索关键词的文档。
步骤2:VectorDB更深入地寻找与上下文有关的文档。
步骤3:集合检索器(Ensemble Retriever)运行两个系统,结合它们的发现,并重新排序结果,向用户展示一个细致全面的文档集。
参考:https://www.atyun.com/58079.html
https://github.com/gkamradt/langchain-tutorials/blob/697c4de4f6c655ea3aa16ea0de324da157398557/data_generation/Advanced%20Retrieval%20With%20LangChain.ipynb#L999
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever],
weights=[0.5, 0.5])
docs = ensemble_retriever.get_relevant_documents("A green fruit")
Chunk的常用方式
参考https://mp.weixin.qq.com/s/mn0MilYoyV0Df_7SXnuY2g
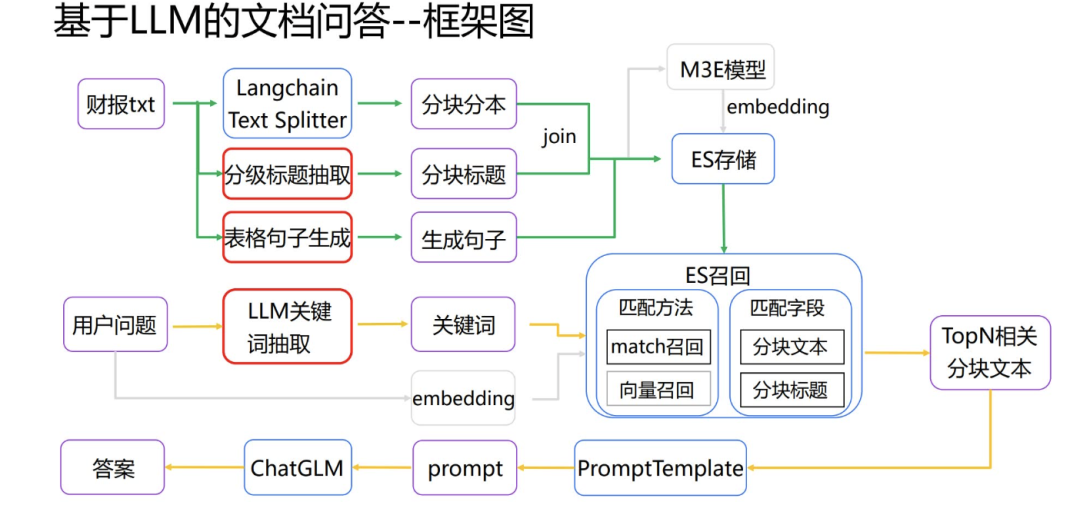
具体参考 :https://www.luxiangdong.com/2023/09/20/chunk/
要点: 分割后的文本块要尽量是语义独立的,没有对上下文很强的依赖。
embedding的不同方式以及对结果的影响
当嵌入一个句子时,生成的向量集中在句子的特定含义上。当与其他句子Embedding进行比较时,自然会在这个层次上进行比较。这也意味着Embedding可能会错过在段落或文档中找到的更广泛的上下文信息。
当嵌入一个完整的段落或文档时,Embedding过程既要考虑整个上下文,也要考虑文本中句子和短语之间的关系。这可以产生更全面的向量表示,从而捕获文本的更广泛的含义和主题。然而,较大的输入文本大小可能会引入噪声或淡化单个句子或短语的重要性,从而在查询索引时更难以找到精确的匹配。
使用的时候技巧: 较短的查询,如单个句子或短语,将专注于细节,可能更适合与句子级Embedding进行匹配。跨越多个句子或段落的较长的查询可能更适合段落或文档级别的Embedding,因为它可能会寻找更广泛的上下文或主题。
固定大小的分块方式: 设置固定块的大小,并给出一定重叠,是最计算方便的分块方式
代码如下:
text = "..." # your text
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n", 分隔符
chunk_size = 256, 块大小
chunk_overlap = 20 块的overlap
)
docs = text_splitter.create_documents([text])
基于spacy的方块方式
它能提供复杂的句子分割功能, 可以将spacy和langchain结合使用
text = "..." # 你的文本
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpaCyTextSplitter()
docs = text_splitter.split_text(text)
递归分割
使用分层和迭代的方式分块
text = "..." # 你的文本
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# 设置一个非常小的块大小。
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
RAG的常见痛点和调优思路
https://zhuanlan.zhihu.com/p/671067214
https://www.zhihu.com/question/628651389/answer/3382588936
CRAG: https://mp.weixin.qq.com/s/91F_sxXNL1_h9Wg_aZDP2w
https://mp.weixin.qq.com/s?__biz=MzIzMzYwNzY2NQ==&mid=2247489357&idx=1&sn=4193a9e92c7749e4ecdacbce7cf6b9db&chksm=e8824fd3dff5c6c5b6c04be81624bf075c96fef23fc40f8cd165a600ecaa02d434a5fd21da41&scene=21#wechat_redirect
selfrag: https://mp.weixin.qq.com/s?__biz=MzIzMzYwNzY2NQ==&mid=2247489393&idx=1&sn=1917808697d84cfd17e628d58b3bfd89&chksm=e8824fefdff5c6f93a322772245c5d4c5c1b22f0f05a45f60d096a99b07bfdb12f54042d5aaf&scene=21#wechat_redirect
调优方案: https://mp.weixin.qq.com/s?__biz=MzIzMzYwNzY2NQ==&mid=2247489349&idx=1&sn=e68ad131621a0cf94d5532f5da2d0199&chksm=e8824fdbdff5c6cdcb8e683b67b07d996af3cf51107099529e4c12b859e8192be7d05d07f479&scene=21#wechat_redirect
RAG的综述
https://zhuanlan.zhihu.com/p/683171274
https://zhuanlan.zhihu.com/p/681421145

















 4308
4308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









