







逻辑斯蒂回归与最大熵模型都属于对数线性模型。
1、二项逻辑斯蒂回归模型
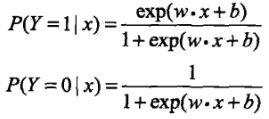
2、最大熵模型
最大熵原理认为,学习模型时,在所有可能的概率模型中,熵最大的模型就是最好的模型。

对于最大熵模型里面的特征的理解:
1、仅仅对输入抽取特征,即特征函数为
2、对输入和输出同时抽取特征,即特征函数为
下面讲解一下如何把最大熵模型推导成logistic回归模型。
最大熵模型定义了在个给定输入变量x时,输出变量y的条件分布:
此处是y所有可能取值的集合
如果我们限定y为二元变量,即,那么久可以把最大熵模型转换成logistic回归模型。我们还需要定义特征函数为
即仅在时抽取x的特征。在
时不抽取任何特征(直接返回为全0的特征向量)。
将这个特征函数代回最大熵模型,得到当时
当时
我们发现,当类标签只有两个时,最大熵模型就是logistic模型。
表面上看,logistic回归模型里面的特征函数的确只考虑x不考虑y。然而通过上面的推导,我们发现其实g抽取的特征仅仅在时被用到。另外,logistic回归模型当然有特征的概念。















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









