






 本文介绍了一种名为对比预测编码(CPC)的非监督学习通用算法,它在高维数据中提取有用表示,通过自回归模型预测未来隐变量,使用对比损失最大化样本信息。
本文介绍了一种名为对比预测编码(CPC)的非监督学习通用算法,它在高维数据中提取有用表示,通过自回归模型预测未来隐变量,使用对比损失最大化样本信息。
论文:https://arxiv.org/pdf/1807.03748.pdf
摘要:
监督学习在很多应用方面有了巨大的进步,但是非监督学习却没有如此广的应用,非监督学习是人工智能方面非常重要也非常具有挑战性的领域。这篇论文提出了 constrative predictive coding,一个非监督的通用的算法用于在高维度数据中提取有用的表示信息。算法的核心是通过强大的自回归(autoregressive)模型来学习未来的(预测的)隐变量表示。论文使用对比损失概率(probabilistic contrastive loss)来引入最大化预测样本的信息的隐变量。大多数其他研究的工作都集中在使用一个特殊的修正(公式)评估表示,论文(CPC)所使用的方法在学习有用信息表示的时候表现非常优异。
介绍:
迄今为止,在标注数据上通过端对端的方式学习高级表示是人工智能的巨大成功之处。但是,仍然存在数据使用效率,鲁棒性和泛化能力不足的缺点。非监督学习通常使用的策略常被用于预测未来、丢失或者上下文相关的信息。 Prodictive coding 是数据压缩的一个传统方式。神经科学认为大脑预测状态是多层的,有重点的,现阶段在预测上下文词语上的表示学习非常成功。论文假设上述的方法(指的是表示学习的一些方法)成功的部分原因是我们使用同样的高层隐变量信息来预测相关变量。
论文主要工作:①将高位数据压缩到更简洁的隐变量空间,该空间使用条件概率建造。②在隐变量中使用强大的自回归模型来预测未来可能的步骤。③使用对抗噪声估计(noise-contrastive estimation)
启发:
在时间序列和高维度建模中,使用下一步预测来开采信号的平滑度。当预测的更远,公用信息变得更少,模型需要更全局结构的推断。预测高维数据的挑战众多:①单峰的损失函数,如均方差,交叉熵不适用。②强大的生成模型需要重建数据的每个特征。
直接通过条件概率方程![]() 来探索数据 x 和内容 c之间的信息不是最有效的解决方案。论文在预测未来信息时,将目标x(未来的)和内容 c(现在的)通过非线性映射压缩成一个向量表示的分布,替代成互信息表示方式,如下公式所示:
来探索数据 x 和内容 c之间的信息不是最有效的解决方案。论文在预测未来信息时,将目标x(未来的)和内容 c(现在的)通过非线性映射压缩成一个向量表示的分布,替代成互信息表示方式,如下公式所示:
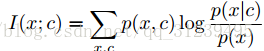
对比预测编码:
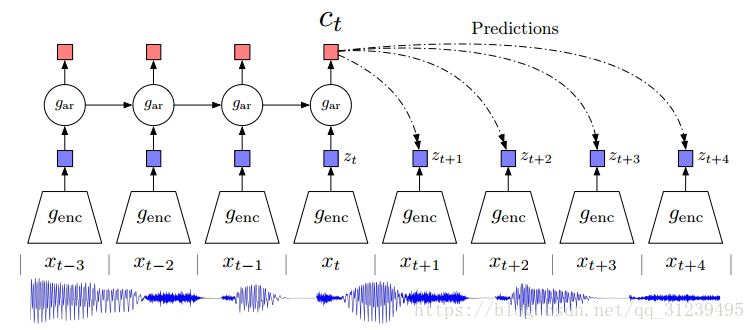
如图所示,![]() 是非线性编码器,用于映射输入序列
是非线性编码器,用于映射输入序列![]() ,到隐变量表示序列
,到隐变量表示序列![]() ,自回归模型
,自回归模型![]() 总结所有t时刻之前的隐变量空间和生成内容隐变量表示
总结所有t时刻之前的隐变量空间和生成内容隐变量表示![]()
论文构造了一个密度概率函数,用于保存探索序列![]() 和内容隐变量表示
和内容隐变量表示![]() 之间的互信息,公式如下:
之间的互信息,公式如下:

论文使用log双线性模型:其中![]() 表示预测每一个步骤k的不同于
表示预测每一个步骤k的不同于![]() 线性转化。同时,如果使用非线性网络结构或者循环神经网络结构也是可以的。
线性转化。同时,如果使用非线性网络结构或者循环神经网络结构也是可以的。
![]()
论文使用了重要性采样(importance sampling)和noise-contrastive estimation等技巧,使用resnet作为编码器,GRUs作为自回归模型。如果使用现在最新的研究,比如masked convolutional architectures 或者 self-attention,可能会更大的提升实验结果。
NCE相对噪声估计:
编码器和自回归模型基于NCE(noise contrastive estimator)联合优化损失函数,给定一个序列![]() ,其中有一个正样本,从
,其中有一个正样本,从![]() 中采样获得,N-1个负样本,从
中采样获得,N-1个负样本,从![]() 中获得,提出损失函数:
中获得,提出损失函数:
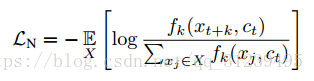
将公式进一步优化,以概率形式写出:
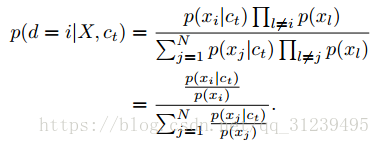
最终,得到的互信息公式如下:
![]()
实验结果:
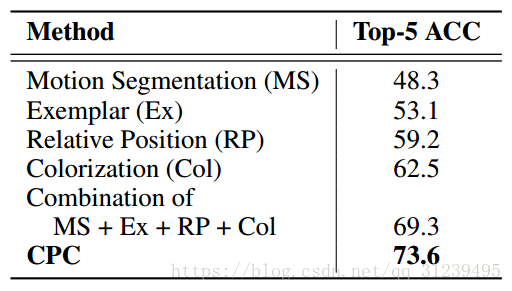
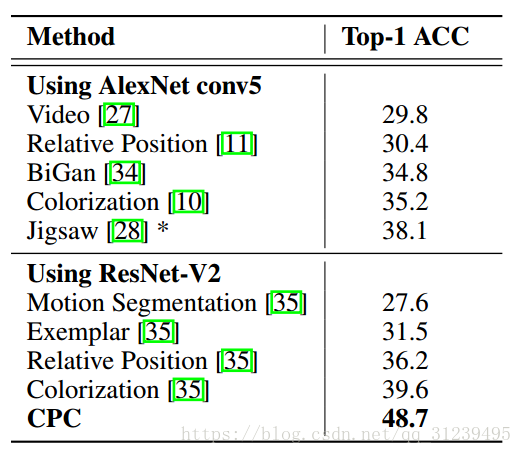
在强化学习模型中,表现如下,红色部分是添加CPC的算法:
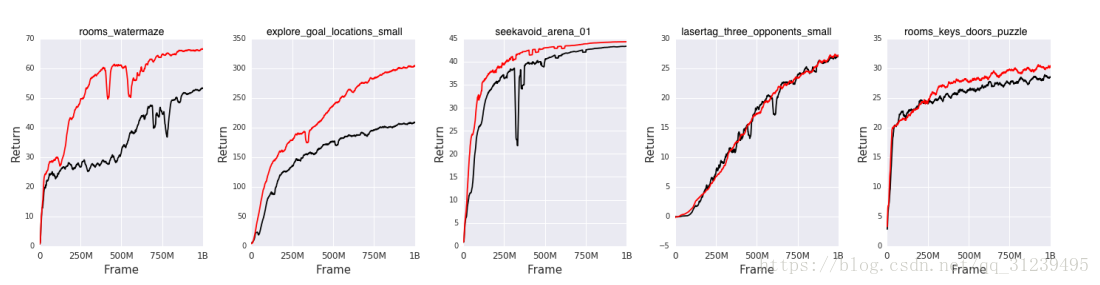
思考:
① 什么是negtive sampling,其特点是什么?
negative sampling表示负采样,其中一个是正样本,其他均为负样本。作用是提高训练速度,改善所得词向量的质量,采用了负采样,每次更新权重的时候,只更新一小部分,而不是更新全部权重。
参考链接:https://blog.csdn.net/itplus/article/details/37998797
② 论文核心思想是什么?
使用自回归模型和编码从高维信息中学习到可表示信息,使用对比预测编码预测未来的隐变量信息。
③ 论文提到如下函数的怎样一个函数,并且其实际物理意义是什么?
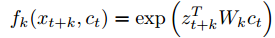
该函数是一个指数函数,在机器学习范畴是一个连接函数,用于表示x与c之间的关系,论文在前面使用负采样和此f函数是为在后面论证最大化互信息的公式做依据,最终得到一个关于互信息的不等式,最大化互信息就是最小化损失函数,最小化该损失函数需要最大化(负的)f 函数,也就是经过论证的成正比的负采样。
④ 论文是怎么同时使用编码和自回归模型的?如此使用的意义何在?
由上述的原理图(即对比预测编码原理图)可知,genc即为一个映射,用于编码输入x,得到隐变量z,而gar作为自回归模型,用于汇总之前的隐变量和当前隐变量得到一个新的表示c,通过c来预测未来的隐变量。
使用编码是为了将数据映射为隐变量,使用自回归模型是为了将之前与当前的隐变量汇总。

















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









