






Aaron van den Oord DeepMind avdnoord@google.com
Yazhe Li DeepMind yazhe@google.com
Oriol Vinyals DeepMind vinyals@google.com
摘要
尽管监督学习在许多应用中取得了巨大进展,但无监督学习尚未得到如此广泛的应用,仍然是人工智能领域一个重要的挑战。本文提出了一种通用的无监督学习方法,用于从高维数据中提取有用的表示,我们将其称为对比预测编码(Contrastive Predictive Coding)。该模型的核心思想是通过使用强大的自回归模型在潜在空间中预测未来信息来学习这些表示。我们采用概率对比损失函数,促使潜在空间捕获对未来样本预测最有用的信息。此外,通过使用负样本采样,使模型变得可行。尽管以往的大多数工作都专注于评估特定模态的表示,但我们证明,我们的方法能够在四个不同的领域(语音、图像、文本和三维环境中的强化学习)中学习有用的表示,并且表现强劲。
1 引言
通过分层可微模型以端到端的方式从标记数据中学习高级表示,是人工智能领域迄今为止最大的成功之一。这些技术使手动指定的特征变得大多多余,并在几个现实世界的应用中极大地提升了最先进的水平 [1, 2, 3]([1] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. [2] Geoffrey Hinton, Li Deng, Dong Yu, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N Sainath, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. [3] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks)。然而,仍有许多挑战存在,例如数据效率、鲁棒性或泛化能力。
改进表示学习需要那些不专门用于解决单一监督任务的特征。例如,在对模型进行图像分类的预训练时,诱导出的特征可以合理地迁移到其他图像分类领域,但也会缺少某些与分类无关但与图像描述相关的信息,例如颜色或计数能力 [4]([4] Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator)。同样,用于转录人类语音的特征可能不太适合于说话人识别或音乐类型预测。因此,无监督学习是实现鲁棒且通用的表示学习的一个重要步骤。
尽管无监督学习非常重要,但尚未实现与监督学习类似的突破:从原始观测中建模高级表示仍然是一个难以捉摸的目标。此外,理想表示并不总是清晰的,也不清楚是否可以在没有额外监督或专门针对特定数据模态的情况下学习这样的表示。
无监督学习最常用的策略之一是预测未来的、缺失的或上下文信息。预测编码的概念 [5, 6]([5] Peter Elias. Predictive coding–i. [6] Bishnu S Atal and Manfred R Schroeder. Adaptive predictive coding of speech signals)是信号处理中用于数据压缩的最古老技术之一。在神经科学中,预测编码理论表明大脑在不同抽象层次上预测观测结果 [7, 8]([7] Rajesh PN Rao and Dana H Ballard. Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. [8] Karl Friston. A theory of cortical responses)。最近在无监督学习中的工作成功地利用这些想法通过预测邻近词汇来学习词汇表示 [9]([9] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space)。对于图像,通过从灰度图像预测颜色或图像块的相对位置也被证明是有用的 [10, 11]([10] Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization. [11] Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised visual representation learning by context prediction)。我们假设这些方法之所以有效,部分是因为我们从中预测相关值的上下文通常条件依赖于相同的共享高级潜在信息。通过将这视为一个预测问题,我们自动推断出表示学习感兴趣的特征。
本文提出以下内容:首先,我们将高维数据压缩到一个更紧凑的潜在嵌入空间中,在这个空间中条件预测更容易建模。其次,我们在这个潜在空间中使用强大的自回归模型进行多步未来的预测。最后,我们依赖于噪声对比估计 [12]([12] Michael Gutmann and Aapo Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models)作为损失函数,类似于在自然语言模型中用于学习词嵌入的方式,从而允许整个模型以端到端的方式进行训练。我们将得到的模型——对比预测编码(CPC)应用于图像、语音、自然语言和强化学习等截然不同的数据模态,并证明相同的机制在这些领域中都学会了有趣的高级信息,超越了其他方法。
2 对比预测编码
本节首先阐述我们方法的动机和直觉。接下来,介绍对比预测编码(CPC)的架构。之后,解释基于噪声对比估计的损失函数。最后,讨论与 CPC 相关的工作。
2.1 动机与直觉
我们模型的主要直觉是学习编码(高维)信号不同部分之间共享的底层信息的表示。同时,它丢弃更局部的低级信息和噪声。在时间序列和高维建模中,利用信号的局部平滑性的下一步预测方法,共享信息量变得很低,模型需要推断出更多的全局结构。这些跨越多个时间步的“慢特征” [13]([13] Laurenz Wiskott and Terrence J Sejnowski. Slow feature analysis: Unsupervised learning of invariances)通常更有趣(例如,语音中的音素和语调、图像中的物体或书籍中的故事情节)。
预测高维数据的一个挑战是,均方误差和交叉熵等单模态损失函数并不十分有用,而需要重建数据中每一个细节的强大条件生成模型通常计算量很大,并且在建模数据 x 中的复杂关系时浪费容量,常常忽略了上下文 c。例如,图像可能包含数千比特的信息,而高级潜在变量(如类别标签)包含的信息要少得多(对于 1,024 个类别来说是 10 比特)。这表明直接建模 ![]() 对于提取 x 和 c 之间的共享信息的目的来说可能不是最优的。当我们预测未来信息时,我们反而将目标 x(未来)和上下文 c(现在)编码到一个紧凑的分布式向量表示中(通过非线性学习映射),以最大程度地保留原始信号 x 和 c 的互信息,定义为
对于提取 x 和 c 之间的共享信息的目的来说可能不是最优的。当我们预测未来信息时,我们反而将目标 x(未来)和上下文 c(现在)编码到一个紧凑的分布式向量表示中(通过非线性学习映射),以最大程度地保留原始信号 x 和 c 的互信息,定义为
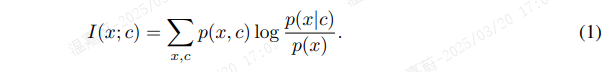
通过最大化编码表示之间的互信息(这受到输入信号之间互信息的限制),我们提取输入所共有的潜在变量。
2.2 对比预测编码
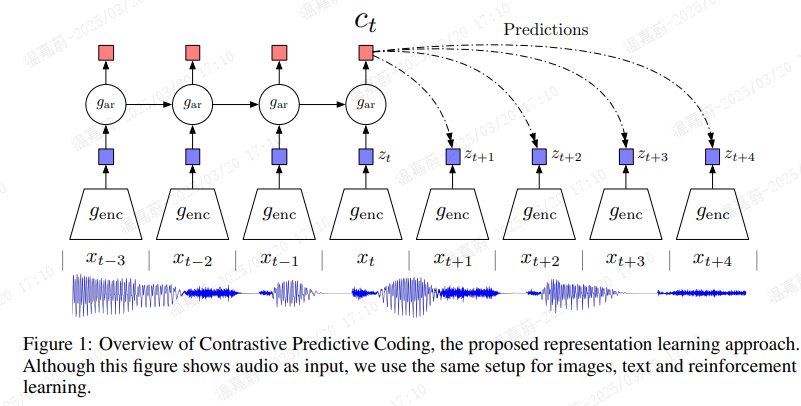
图 1 展示了对比预测编码模型的架构。首先,非线性编码器 将输入观测序列 xt 映射到潜在表示序列
![]() ,可能具有较低的时间分辨率。接下来,自回归模型
,可能具有较低的时间分辨率。接下来,自回归模型 在潜在空间中汇总所有
![]() ,并产生上下文潜在表示
,并产生上下文潜在表示 ![]() 。
。
正如前一节所讨论的,我们不直接使用生成模型 ![]() 预测未来的观测 xt+k。相反,我们建模一个密度比,以保留 xt+k 和 ct 之间的互信息(方程 1),如下(下小节提供更多细节):
预测未来的观测 xt+k。相反,我们建模一个密度比,以保留 xt+k 和 ct 之间的互信息(方程 1),如下(下小节提供更多细节):

其中,∝ 表示“与……成比例”(即,乘以一个常数)。注意,密度比 f 可以是非归一化的(不必积分到 1)。尽管这里可以使用任何正实数得分,我们采用简单的对数双线性模型:
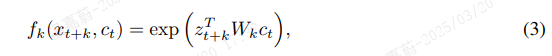
在我们的实验中,使用线性变换 ![]() 进行预测,每个步长 k 使用不同的
进行预测,每个步长 k 使用不同的 ![]() 。当然,也可以使用非线性网络或循环神经网络。
。当然,也可以使用非线性网络或循环神经网络。
通过使用密度比![]() 并用编码器推断 zt+k,我们使模型免于建模高维分布 xt+k。尽管我们不能直接评估 p(x) 或 p(x∣c),但我们可以使用这些分布的样本,从而可以使用基于将目标值与随机采样的负值进行比较的技术,例如噪声对比估计 [12, 14, 15]([12] Michael Gutmann and Aapo Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. [14] Andriy Mnih and Yee Whye Teh. A fast and simple algorithm for training neural probabilistic language models. [15] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring the limits of language modeling)和重要性采样 [16]([16] Yoshua Bengio and Jean-Sebastien Senecal. Adaptive importance sampling to accelerate training of a neural probabilistic language model)。
并用编码器推断 zt+k,我们使模型免于建模高维分布 xt+k。尽管我们不能直接评估 p(x) 或 p(x∣c),但我们可以使用这些分布的样本,从而可以使用基于将目标值与随机采样的负值进行比较的技术,例如噪声对比估计 [12, 14, 15]([12] Michael Gutmann and Aapo Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. [14] Andriy Mnih and Yee Whye Teh. A fast and simple algorithm for training neural probabilistic language models. [15] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring the limits of language modeling)和重要性采样 [16]([16] Yoshua Bengio and Jean-Sebastien Senecal. Adaptive importance sampling to accelerate training of a neural probabilistic language model)。
在所提出的模型中,zt 和 ct 均可作为下游任务的表示。如果额外的过去上下文有用,例如在语音识别中,zt 的感受野可能不足以捕捉音素内容,则可以使用自回归模型的输出 ct。在其他情况下,如果不需要额外上下文,则 zt 可能更合适。如果下游任务需要整个序列的一个表示,例如在图像分类中,可以在所有位置对 zt 或 ct 的表示进行池化。
最后,需要注意的是,在所提出的框架中可以使用任何类型的编码器和自回归模型。为简便起见,我们选择了标准架构,例如对于编码器使用带残差块的步长卷积层,对于自回归模型使用 GRU [17]([17] Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation)。诸如掩码卷积架构 [18, 19]([18] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. [19] Aaron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, and Koray Kavukcuoglu. Conditional image generation with pixelcnn decoders)或自注意力网络 [20]([20] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need)等自回归建模的最新进展,可能会进一步提升结果。
2.3 InfoNCE 损失与互信息估计
编码器和自回归模型共同优化基于 NCE 的损失,我们将其称为 InfoNCE。给定一个包含 N 个随机样本的集合 ![]() ,其中包含一个来自
,其中包含一个来自 ![]() 的正样本和 N−1 个来自“提议 proposal ” 分布
的正样本和 N−1 个来自“提议 proposal ” 分布 ![]() 的负样本,我们优化如下:
的负样本,我们优化如下:

优化该损失将使 ![]() 估计方程 2 中的密度比。可以这样证明:
估计方程 2 中的密度比。可以这样证明:
方程 4 中的损失是正确分类正样本的分类交叉熵,其中 ![]() 是模型的预测。我们用
是模型的预测。我们用 ![]() 表示该损失的最优概率,其中 [d=i] 表示样本 xi 是“正”样本的指示。样本 xi 是从条件分布
表示该损失的最优概率,其中 [d=i] 表示样本 xi 是“正”样本的指示。样本 xi 是从条件分布 ![]() 而不是提议分布
而不是提议分布 ![]() 中抽取的概率可以推导如下:
中抽取的概率可以推导如下:
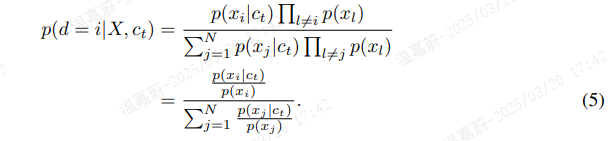
正如我们所见,方程 4 中![]() 的最优值与
的最优值与![]() 成正比,且与负样本数量 N−1 的选择无关。 尽管训练时不需要,但我们可以如下评估变量 ct 和 xt+k 之间的互信息:
成正比,且与负样本数量 N−1 的选择无关。 尽管训练时不需要,但我们可以如下评估变量 ct 和 xt+k 之间的互信息:
![]()
随着 N 的增大,该不等式变得越来越紧 tighter。同时,注意到最小化 InfoNCE 损失 ![]() 最大化了互信息的一个下界。更多细节请参阅附录。
最大化了互信息的一个下界。更多细节请参阅附录。
2.4 相关工作
CPC 是一种新方法,将预测未来观测(预测编码)与概率对比损失(方程 4)结合起来。这使我们能够提取跨越长时间范围的观测的互信息的最大化“慢特征”。对比损失函数和预测编码以往曾被单独使用过,现在我们来讨论。
过去许多作者都使用过对比损失函数。例如,[21, 22, 23]([21] Sumit Chopra, Raia Hadsell, and Yann LeCun. Learning a similarity metric discriminatively, with application to face verification. [22] Kilian Q Weinberger and Lawrence K Saul. Distance metric learning for large margin nearest neighbor classification. [23] Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering)所提出的技术基于三元组损失,采用最大间隔方法将正样本与负样本区分开来。更近期的工作包括时间对比网络 [24]([24] Pierre Sermanet, Corey Lynch, Jasmine Hsu, and Sergey Levine. Time-contrastive networks: Self-supervised learning from multi-view observation),该方法提出最小化来自同一场景多个视角的嵌入之间的距离,同时最大化来自不同时刻的嵌入之间的距离。在时间对比学习 [25]([25] Aapo Hyvarinen and Hiroshi Morioka. Unsupervised feature extraction by time-contrastive learning and nonlinear ica)中,采用对比损失函数预测多变量时间序列的段 ID,以此来提取特征并执行非线性独立成分分析。
在定义从相关观测中预测任务以提取有用表示方面,也已经开展了许多工作,其中许多已应用于语言领域。在 Word2Vec [9]([9] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space)中,使用对比损失函数预测邻近词汇。Skip-thought vectors [26]([26] Ryan Kiros, Yukun Zhu, Ruslan R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Skip-thought vectors)和 Byte mLSTM [27]([27] Alec Radford, Rafal Jozefowicz, and Ilya Sutskever. Learning to generate reviews and discovering sentiment)是替代方案,它们超越了使用循环神经网络进行词预测的范围,并对观测序列使用最大似然估计。在计算机视觉领域,[28]([28] Xiaolong Wang and Abhinav Gupta. Unsupervised learning of visual representations using videos)在跟踪的视频块上使用三元组损失,使得同一物体在不同时刻的块彼此之间的相似度高于随机块。[11, 29]([11] Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised visual representation learning by context prediction. [29] Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles)提出预测图像中块的相对位置,而在 [10]([10] Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful image colorization)中,从灰度图像预测颜色值。
3 实验
我们在四个不同的应用领域进行了基准测试:语音、图像、自然语言和强化学习。对于每个领域,我们训练 CPC 模型,并通过线性分类任务或定性评估来探究所提取的表示包含的内容,在强化学习中,我们测量辅助 CPC 损失如何加速智能体的学习。
3.1 音频
对于音频,我们使用公开可用的 LibriSpeech 数据集 [30]([30] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books)的一个 100 小时子集。尽管该数据集除了原始文本外没有提供其他标签,但我们使用 Kaldi 工具包 [31]([31] Daniel Povey, Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Yanmin Qian, Petr Schwarz, et al. The kaldi speech recognition toolkit)和预训练的 Librispeech 模型获得了强制对齐的音素序列。我们已将对齐的音素标签和我们的训练 / 测试分割在 Google Drive [2] 上提供下载。该数据集包含来自 251 位不同说话者的语音。
在我们的实验中所使用的编码器架构 genc 包含一个步长卷积神经网络,该网络直接作用于 16kHz 的 PCM 音频波形。我们使用五个卷积层,步长分别为 [5,4,2,2,2],滤波器大小分别为 [10,8,4,4,4],以及带有 ReLU 激活的 512 个隐藏单元。网络的总下采样因子为 160,因此每 10ms 的语音就有一个特征向量,这也是使用 Kaldi 获得的音素序列标签的速率。然后,我们使用带有 256 维隐藏状态的 GRU RNN [17] 作为模型的自回归部分 gar。GRU 在每个时间步的输出被用作上下文 c,从中我们使用对比损失预测未来的 12 个时间步。我们在长度为 20480 的采样音频窗口上进行训练。我们使用 Adam 优化器 [32]([32] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization),学习率为 2×10−4,并使用 8 个 GPU,每个 GPU 的小批量为 8 个样本,这些样本用于对比损失中的负样本采样。模型训练直至收敛,大约在 300,000 次更新时发生。
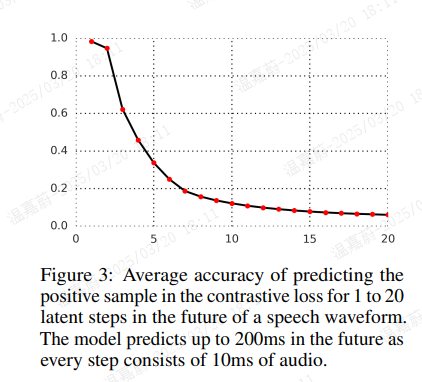
图 3 展示了模型预测未来潜在变量的准确率,从 1 到 20 个时间步。我们报告了在概率对比损失中正样本的 logit 高于负样本的平均次数。该图还表明,该目标既非微不足道,也非不可能实现,正如预期的那样,随着目标距离的增加,预测任务变得更加困难。
为了理解 CPC 提取的表示,我们使用线性分类器在这些特征之上训练,以衡量电话预测性能,这表明在这些特征下相关类别线性可分的程度。我们在模型收敛后提取整个数据集的 GRU 输出(256 维),即 ct,并训练一个多类线性逻辑回归分类器。结果如表 1(上)所示。我们将其准确性与三个基线进行比较:来自随机初始化模型的表示(即,genc 和 gar 未经过训练)、MFCC 特征以及一个端到端使用标记数据训练的模型。这两个模型具有与用于提取 CPC 表示相同的架构。完全监督的模型表明了使用该架构可以实现的水平。我们还发现,并非所有编码的信息都可以线性获取。当我们使用单隐藏层时,准确性从 64.6 提高到 72.5,更接近完全监督模型的准确性。
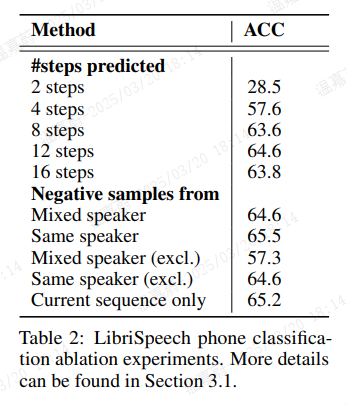
表 2 概述了针对电话分类的 CPC 的两个消融研究。在第一组中,我们改变模型预测的步数,表明预测多步对于学习有用的特征很重要。在第二组中,我们比较了不同的负样本采样策略,所有策略均预测 12 步(在第一次消融中给出了最佳结果)。在混合说话者实验中,负样本包含不同说话者的样本(第一行),与同说话者实验(第二行)形成对比。在第三和第四实验中,我们排除当前序列以采样负样本(因此,X 中只有其他样本),在最后一个实验中,我们仅在序列内采样负样本(因此,所有样本均来自同一说话者)。
除了电话分类之外,表 1(下)显示了使用相同的表示进行说话者身份识别(251 位说话者中)的准确性,使用线性分类器进行识别(我们不对时间上的发音进行平均)。
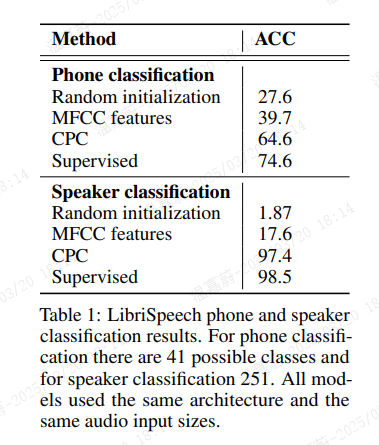
有趣的是,CPC 捕获了说话者身份和语音内容,如简单的线性分类器所获得的良好准确性所示,这也接近于完全监督网络的水平。 此外,图 2 展示了一个 t-SNE 可视化 [33]([33] Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne),表明嵌入对于说话者声音特征的区分性。需要注意的是,窗口大小(GRU 的最大上下文大小)对性能有很大影响,更长的段将给出更好的结果。我们的模型最多可以处理 20480 个时间步,这略长于一秒。

3.2 视觉
在我们的视觉表示实验中,我们使用了 ILSVRC ImageNet 竞赛数据集 [34]([34] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge)。许多作者 [28, 11, 35, 10, 29, 36]([28] Xiaolong Wang and Ab
nav Gupta. Unsupervised learning of visual representations using videos. [11] Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsupervised visual representation learning by context prediction. [35] Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. Adversarial feature learning. [36] Carl Doersch and Andrew Zisserman. Multi-task self-supervised visual learning)已使用 ImageNet 数据集来评估无监督视觉模型。我们遵循与 [36] 相同的设置,并使用 ResNet v2 101 架构 [37]([37] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks)作为图像编码器 genc 来提取 CPC 表示(请注意,此编码器未进行预训练)。我们没有使用批量归一化 [38]([38] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift) 。在无监督训练后,训练一个线性层以测量在 ImageNet 标签上的分类准确率。 训练过程如下:从 256x256 的图像中,我们提取一个 7x7 的 64x64 裁剪网格,每个裁剪之间有 32 像素的重叠。简单的数据增强在 256x256 图像和 64x64 裁剪上都证明是有帮助的。256x256 的图像从 300x300 的图像中随机裁剪,以 50% 的概率水平翻转,并转换为灰度图像。对于每个 64x64 的裁剪,我们随机取一个 60x60 的子裁剪,并将其填充回 64x64 的图像。 然后,每个裁剪通过 ResNet-v2-101 编码器进行编码。我们使用第三残差块的输出,并进行空间平均池化,以获得每个 64x64 块的单个 1024 维向量。这产生了一个 7x7x1024 的张量。接下来,我们使用类似 PixelCNN 的自回归模型 [19]([19] Aaron van den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Conditional image generation with pixelcnn decoders)(卷积行 GRU PixelRNN [39]([39] Aaron van den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks)给出了类似的结果)来预测 7x7 网格中接下来的行的潜在激活,从上到下进行预测,如图 4 所示。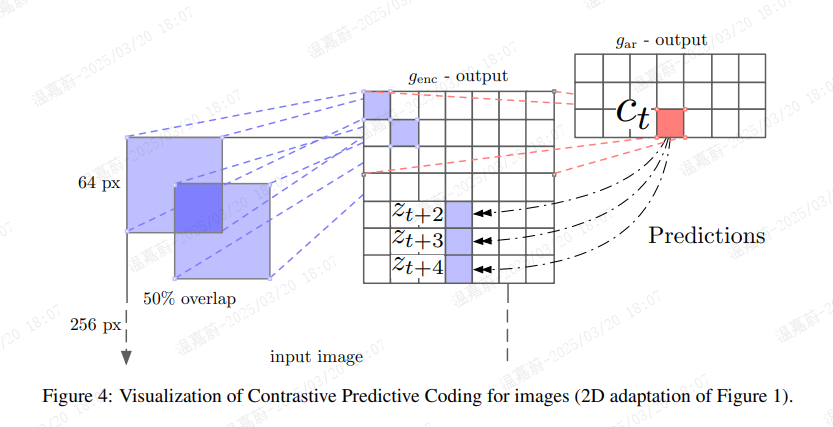
我们预测多达 5 行,并对每一行中的每个块应用对比损失。我们使用 Adam 优化器,学习率为 2×10−4,并在 32 个 GPU 上进行训练,每个 GPU 的批量大小为 16。 对于在 CPC 特征之上训练的线性分类器,我们使用动量为 0.9 的 SGD,学习率计划为 0.1、0.01 和 0.001,分别对应 50k、25k 和 10k 次更新,单个 GPU 上的批量大小为 2048。请注意,在训练线性分类器时,我们首先将 7x7x1024 的表示进行空间平均池化,得到一个 1024 维的向量。这与 [36] 略有不同,[36] 使用 3x3x1024 的表示而不进行池化,因此在监督线性映射中有更多的参数(这可能是一个优势)。
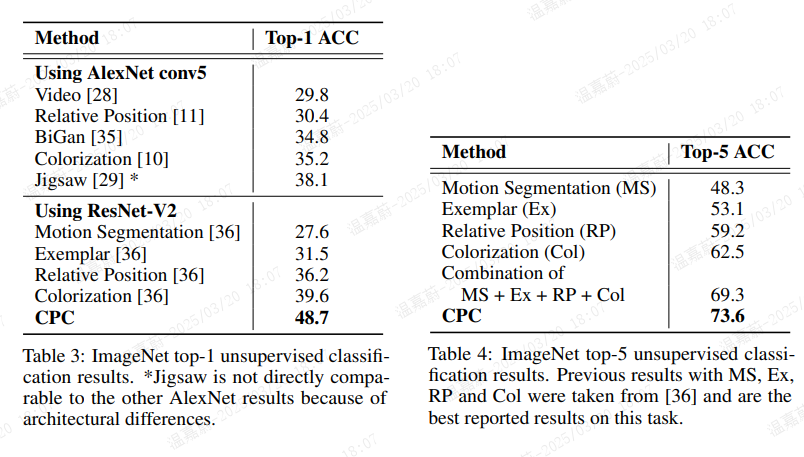
表 3 和表 4 显示了与最新技术相比的 top-1 和 top-5 分类准确率。尽管 CPC 相对通用,但在 top-1 准确率上比最新技术提高了 9% 的绝对值,在 top-5 准确率上提高了 4% 的绝对值。
3.3 自然语言
我们的自然语言实验紧密遵循 [26] 中用于 skip-thought vectors 模型的程序。我们首先在 BookCorpus 数据集 [42]([42] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books)上学习我们的无监督模型,并通过使用 CPC 表示进行一系列分类任务来评估模型作为通用特征提取器的能力。为了处理训练期间未见过的词汇,我们采用与 [26] 相同的词汇扩展方法,在 word2vec 和模型学习的词嵌入之间构建线性映射。 对于分类任务,我们使用了以下数据集:电影评论情感(MR)[43]([43] Bo Pang and Lillian Lee. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales)、客户产品评论(CR)[44]([44] Minqing Hu and Bing Liu. Mining and summarizing customer reviews)、主观性 / 客观性 [45]([45] Bo Pang and Lillian Lee. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts)、观点极性(MPQA)[46]([46] Janyce Wiebe, Theresa Wilson, and Claire Cardie. Annotating expressions of opinions and emotions in language)和问题类型分类(TREC)[47]([47] Xin Li and Dan Roth. Learning question classifiers)。与 [26] 一样,我们训练逻辑回归分类器,并对 MR、CR、Subj、MPQA 进行 10 折交叉验证评估,对 TREC 使用训练 / 测试分割。通过交叉验证选择 L2 正则化权重(因此对于前 4 个数据集进行嵌套交叉验证)。 我们的模型由一个简单的句子编码器 genc(一维卷积 + ReLU + 平均池化)组成,将整个句子嵌入到一个 2400 维向量 z 中,然后是一个 GRU(2400 个隐藏单元),它使用对比损失预测多达 3 个未来的句子嵌入以形成 c。我们使用 Adam 优化器,学习率为 2×10−4,在 8 个 GPU 上进行训练,每个 GPU 的批量大小为 64。我们发现更高级的句子编码器并没有显著提高结果,这可能是因为转移任务的简单性(例如,在 MPQA 中,大多数数据点由一个或几个词组成),以及事实证明,词袋模型在许多 NLP 任务中通常表现良好 [48]([48] Sida Wang and Christopher D. Manning. Baselines and bigrams: Simple, good sentiment and topic classification)。 表 5 显示了评估任务的结果,我们将我们的模型与其他使用相同数据集的模型进行了比较。我们的方法的性能与 skip-thought vectors 模型非常相似,但优势在于它不需要强大的 LSTM 作为词级解码器,因此训练速度要快得多。尽管这是一个标准的转移学习基准,但我们发现,在儿童书籍中学习到更好关系的模型并不一定在目标任务(如电影评论等)上表现更好。我们注意到,通过从不同的源任务进行转移学习,已经在这些目标数据集上发布了更好的结果 [49, 27]([49] Han Zhao, Zhengdong Lu, and Pascal Poupart. Self-adaptive hierarchical sentence model. [27] Alec Radford, Rafal Jozefowicz, and Ilya Sutskever. Learning to generate reviews and discovering sentiment)。
3.4 强化学习
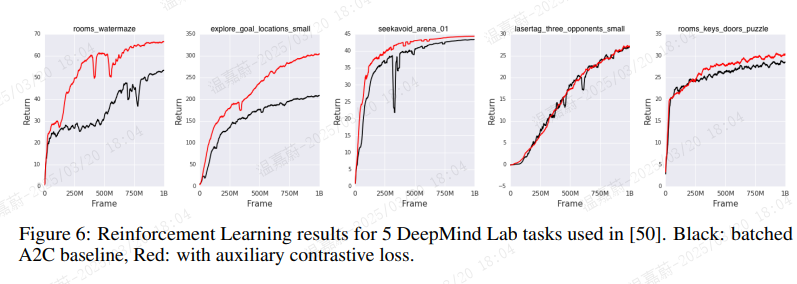
最后,我们在 DeepMind Lab [51]([51] Charles Beattie, Joel Z Leibo, Denis Teplyashin, Tom Ward, Marcus Wainwright, Heinrich Küttler, Andrew Lefrancq, Simon Green, Víctor Valdés, Amir Sadik, et al. Deepmind lab)的五个三维环境中的强化学习任务上评估了所提出的无监督学习方法:rooms_watermaze、explore_goal_locations_small、seekavoid_arena_01、lasertag_three_opponents_small 和 rooms_keys_doors_puzzle。 该设置与前三个有所不同。在这里,我们以标准的批量 A2C [52]([52] Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning)智能体作为基础模型,并在其上添加 CPC 作为辅助损失函数。我们没有使用回放缓冲区,因此预测必须适应策略行为的变化。所学到的表示编码了其未来观测的分布。 按照 [50]([50] Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Volodymir Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures)中的相同方法,我们对熵正则化权重、学习率和 RMSProp [53]([53] Geoffrey Hinton, Nitish Srivastava, and Kevin Swersky. Neural networks for machine learninglecture 6a-overview of mini-batch gradient descent)的 epsilon 超参数进行了随机搜索。A2C 的展开长度为 100 步,我们预测多达 30 步的未来以得出对比损失。基础智能体由一个卷积编码器组成,该编码器将每个输入帧映射到一个单一向量,随后是一个时间 LSTM。我们使用与基础智能体相同的编码器,仅添加用于对比损失的线性预测映射,这带来了最小的开销,也展示了在为特定任务设计和调整的现有架构上实现我们方法的简单性。有关其他超参数和实现细节,请参阅 [50]。
图 6 显示,在训练 10 亿帧后,对于 5 个游戏中的 4 个,使用对比损失的智能体性能显著提升。对于 lasertag_three_opponents_small,对比损失既没有帮助也没有损害。我们怀疑这是由于任务设计的原因,该任务不需要记忆,因此产生了一个纯粹的反应式策略。
4 结论
在本文中,我们提出了对比预测编码(CPC),这是一个用于提取紧凑潜在表示以编码对未来观测预测的框架。CPC 结合了自回归建模和噪声对比估计,并借鉴了预测编码的直觉,以无监督的方式学习抽象表示。我们在多种不同的领域(音频、图像、自然语言和强化学习)中测试了这些表示,并在用作独立特征时取得了强劲或最先进的性能。训练模型的简单性和低计算要求,以及在与主损失结合使用时在具有挑战性的强化学习领域中取得的令人鼓舞的结果,是朝着适用于更多数据模态的通用无监督学习迈出的令人兴奋的一步。


















 5483
5483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









