







目录
4.1 神经元
4.1.1 净活性值
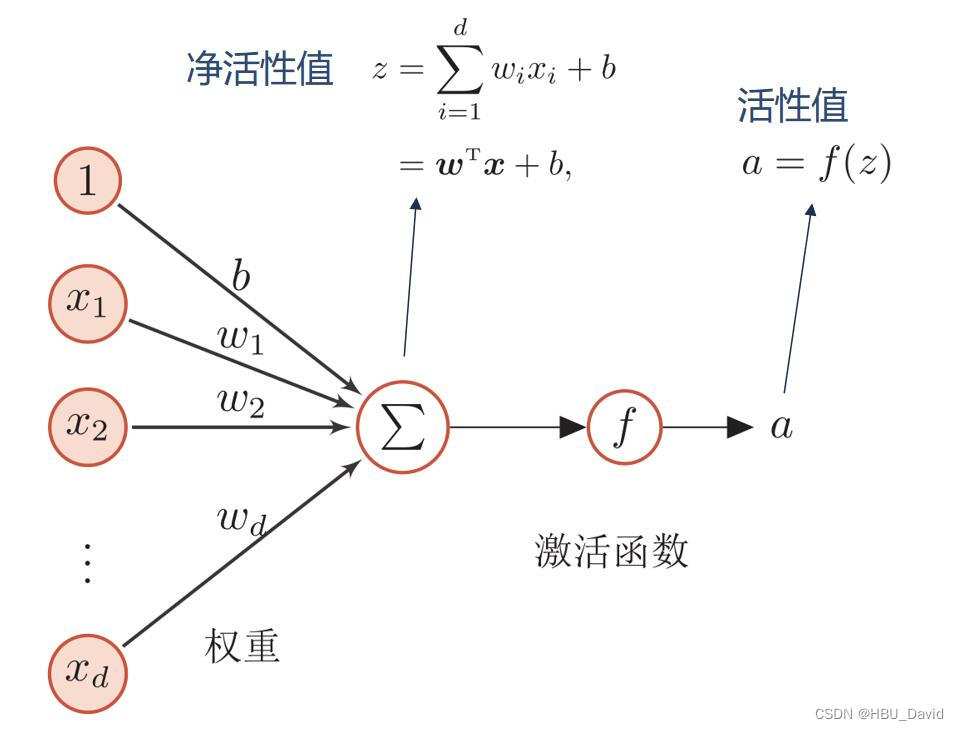
使用pytorch计算一组输入的净活性值z
代码参考paddle例题:
import paddle
# 2个特征数为5的样本
X = paddle.rand(shape=[2, 5])
# 含有5个参数的权重向量
w = paddle.rand(shape=[5, 1])
# 偏置项
b = paddle.rand(shape=[1, 1])
# 使用'paddle.matmul'实现矩阵相乘
z = paddle.matmul(X, w) + b
print("input X:", X)
print("weight w:", w, "\nbias b:", b)
print("output z:", z)在飞桨中,可以使用nn.Linear完成输入张量的上述变换。
在pytorch中学习相应函数torch.nn.Linear(features_in, features_out, bias=False)。
实现上面的例子,完成代码,进一步深入研究torch.nn.Linear()的使用。
import torch
# 2个特征数为5的样本
X = torch.rand(size=[2, 5])
# 含有5个参数的权重向量
w = torch.rand(size=[5, 1])
# 偏置项
b = torch.rand(size=[1, 1])
# 使用'paddle.matmul'实现矩阵相乘
z = torch.matmul(X, w) + b
print("input X:", X)
print("weight w:", w, "\nbias b:", b)
print("output z:", z)
fc = torch.nn.Linear(5,1)
z = fc(X)
print('m.weight.shape:\n ', fc.weight)
print('m.bias.shape:\n', fc.bias)
print('output.shape:\n', z.shape)
print('output:\n', z)
得到以下结果:
input X: tensor([[0.8348, 0.0965, 0.5675, 0.6866, 0.0386],
[0.6098, 0.8196, 0.6592, 0.1052, 0.0593]])
weight w: tensor([[0.2700],
[0.4832],
[0.9904],
[0.6179],
[0.5249]])
bias b: tensor([[0.6089]])
output z: tensor([[1.8875],
[1.9185]])
m.weight.shape:
Parameter containing:
tensor([[-0.1820, 0.2593, -0.1644, -0.2548, -0.0099]], requires_grad=True)
m.bias.shape:
Parameter containing:
tensor([-0.2644], requires_grad=True)
output.shape:
torch.Size([2, 1])
output:
tensor([[-0.6599],
[-0.2985]], grad_fn=<AddmmBackward0>)
进程已结束,退出代码为 0
torch.nn.Linear(in_features, out_features, bias=True) 函数是一个线性变换函数。
其中,in_features为输入样本的大小,out_features为输出样本的大小,bias默认为true。如果设置bias = false那么该层将不会学习一个加性偏差。
Linear()函数通常用于设置网络中的全连接层。
in_features为上一层神经元的个数,out_features为这一层的神经元个数。
输入Linear(input,output)的时候权重w的形状是[output,input]运算的时候会将w进行torch.t转置,所以这里的输入跟自己手打的w是一样的。
下面测试一下bias=False的时候是什么情况
import torch
# 2个特征数为5的样本
X = torch.rand(size=[2, 5])
fc = torch.nn.Linear(5,1,bias=False)
z = fc(X)
print('m.weight:\n ', fc.weight)
print('m.bias:\n', fc.bias)
print('output.shape:\n', z.shape)
print('output:\n', z)得到以下结果:
m.weight:
Parameter containing:
tensor([[ 0.0152, 0.2062, -0.3861, -0.4295, 0.3877]], requires_grad=True)
m.bias:
None
output.shape:
torch.Size([2, 1])
output:
tensor([[-0.2071],
[-0.2182]], grad_fn=<MmBackward>)可以发现bias=False的时候是没有偏置项的,也就是b的值是0。
【思考题】加权求和与仿射变换之间有什么区别和联系?


加权和其实就是对一组输入进行线性变换。
一个任意的仿射变换都能表示为 乘以一个矩阵 (线性变换) 接着再 加上一个向量 (平移).
仿射变换有两个特点:变换前是直线,变换后依然是直线;直线比例保持不变
线性变换有三个特点:变换前是直线,变换后依然是直线;直线比例保持不变;变换前是原点,变换后依然是原点
仿射变换与线性变换相比少了原点保持不变这一条。例如平移不是线性变换而是仿射变换。
设v、w是两个线性空间.一个v至w的线性映射T,就称为v至w的线性变换.
线性变换必须满足任意的x,y∈v 及任意实数a,b,有 T(ax+by)=aT(x)+bT(y)
如恒等变换 I .v→v,对任意的x∈v,有 I(x)=x
因为 I(ax+by)=ax+by= a I(x)+b I(y) 满足 T(ax+by)=aT(x)+bT(y)所以 I 是线性变换.
几何上恒等变换不改变图形的大小和位置.其在常用基下对应的矩阵为单位矩阵E.
是不是线性变换就通过看是否满足T(ax+by)=aT(x)+bT(y)来验证.
同理 旋转变换、伸缩变换(几何上表现为扩大缩小图形 X=kx;Y=ky)、切变变换(几何上表现为X=x+ky;Y=y+kx)、投影变换(投影在x或y轴上)、反射变换(几何上表现为关于某条直线对称)、零变换(O)等都是线性变换.
若一个变换是由几个线性变换复合而成,该变换也为线性变换.
映射 f : V∪A → V∪A 满足
①若p∈A, 则f( p)∈A
②若v∈V, 则f(v)∈V
且 任意的x、y∈V a∈域F: f(x+y)=f(x)+f(y), f(ax)=af(x)
③p∈A, v∈V, f(p+v) = f( p) + f(v) 即 q,p∈A, f(q)-f( p)=f(q-p)
f 就是仿射变换。
即 f 把向量变换成向量,把点变换成点,对向量的变换是线性变换,
对点和向量的加法也有合适的体现。
可见 仿射变换 包含 线性变换。
这里参考文献线性变换和仿射变换_caimouse的博客-CSDN博客_线性变换和仿射变换
(36条消息) 线性变换与仿射变换 点和向量的代数定义_SpaceKitt的博客-CSDN博客_线性变换与仿射变换
4.1.2 激活函数
净活性值z经过一个非线性函数f(·)后,得到神经元的活性值a。
激活函数通常为非线性函数,可以增强神经网络的表示能力和学习能力。
常用的激活函数有S型函数和ReLU函数。
4.1.2.1 Sigmoid 型函数
常用的 Sigmoid 型函数有 Logistic 函数和 Tanh 函数。
使用python实现并可视化“Logistic函数、Tanh函数”
import torch
import matplotlib.pyplot as plt
# Logistic函数
def logistic(z):
return 1.0 / (1.0 + torch.exp(-z))
# Tanh函数
def tanh(z):
return (torch.exp(z) - torch.exp(-z)) / (torch.exp(z) + torch.exp(-z))
# 在[-10,10]的范围内生成10000个输入值,用于绘制函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), logistic(z).tolist(), color='#e4007f', label="Logistic Function")
plt.plot(z.tolist(), tanh(z).tolist(), color='#f19ec2', linestyle ='--', label="Tanh Function")
ax = plt.gca() # 获取轴,默认有4个
# 隐藏两个轴,通过把颜色设置成none
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 调整坐标轴位置
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='lower right', fontsize='large')
plt.savefig('fw-logistic-tanh.pdf')
plt.show()
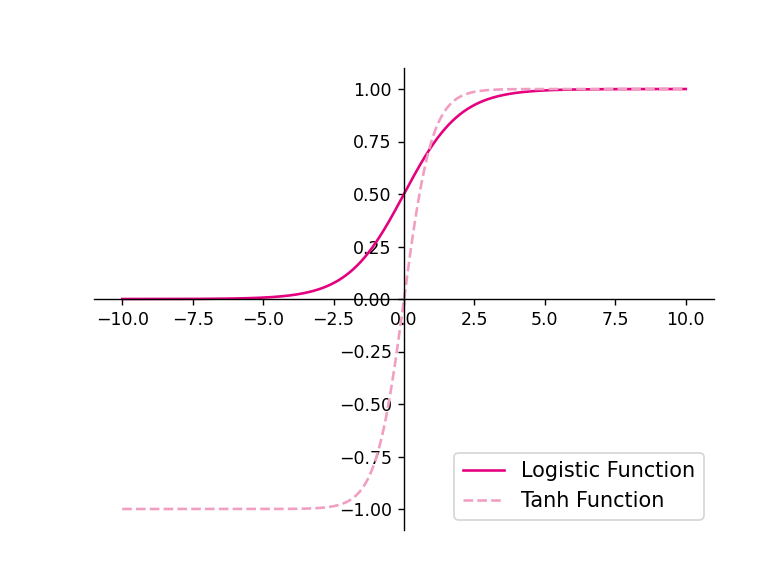
在飞桨中,可以通过调用paddle.nn.functional.sigmoid和paddle.nn.functional.tanh实现对张量的Logistic和Tanh计算。在pytorch中找到相应函数并测试。
import torch
import matplotlib.pyplot as plt
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), torch.nn.functional.sigmoid(z).tolist(), color='#e4007f', label="Logistic Function")
plt.plot(z.tolist(), torch.nn.functional.tanh(z).tolist(), color='#f19ec2', linestyle ='--', label="Tanh Function")
ax = plt.gca() # 获取轴,默认有4个
# 隐藏两个轴,通过把颜色设置成none
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 调整坐标轴位置
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='lower right', fontsize='large')
plt.savefig('fw-logistic-tanh.pdf')
plt.show()
得到以下结果:
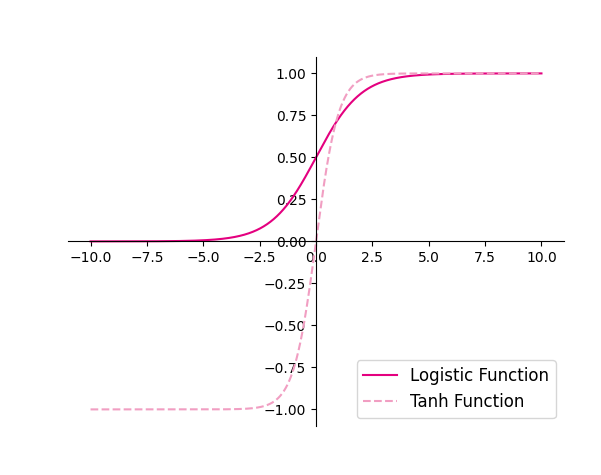
发现结果是一样的,也可以直接用
torch.sigmoid(z)
torch.tanh(z)实现对张量Logistic和Tanh的计算。
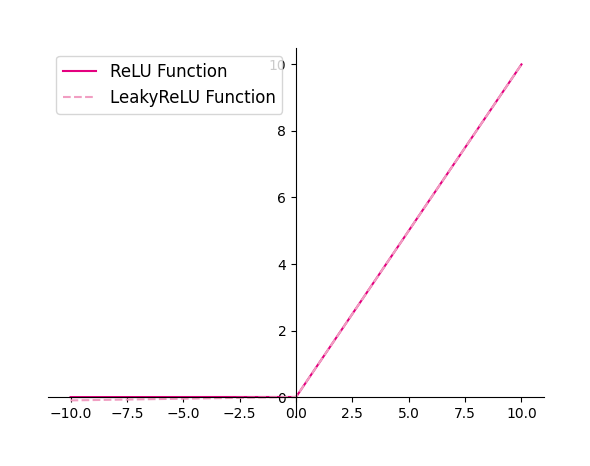
4.1.2.2 ReLU型函数
常见的ReLU函数有ReLU和带泄露的ReLU(Leaky ReLU)

1、使用python实现并可视化可视化“ReLU、带泄露的ReLU的函数”
import torch
import matplotlib.pyplot as plt
# ReLU
def relu(z):
return torch.maximum(z, torch.tensor(0.))
# 带泄露的ReLU
def leaky_relu(z, negative_slope=0.1):
# 当前版本paddle暂不支持直接将bool类型转成int类型,因此调用了paddle的cast函数来进行显式转换
a1 = (torch.as_tensor((z > 0), dtype=torch.float32) * z)
a2 = (torch.as_tensor((z <= 0), dtype=torch.float32) * (negative_slope * z))
return a1 + a2
# 在[-10,10]的范围内生成一系列的输入值,用于绘制relu、leaky_relu的函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), relu(z).tolist(), color="#e4007f", label="ReLU Function")
plt.plot(z.tolist(), leaky_relu(z).tolist(), color="#f19ec2", linestyle="--", label="LeakyReLU Function")
ax = plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='upper left', fontsize='large')
plt.savefig('fw-relu-leakyrelu.pdf')
plt.show()
得到以下结果:
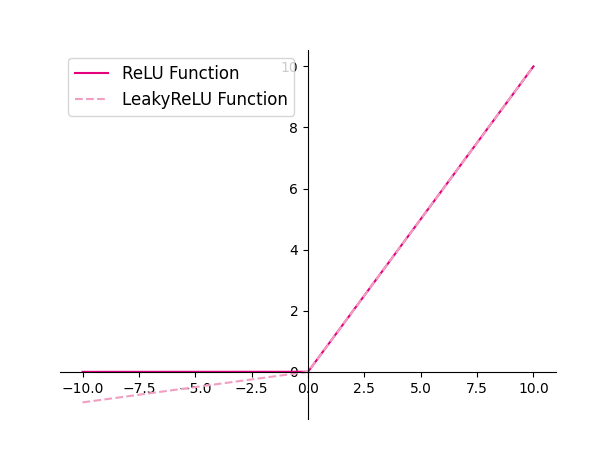
2、在飞桨中,可以通过调用paddle.nn.functional.relu和paddle.nn.functional.leaky_relu完成ReLU与带泄露的ReLU的计算。在pytorch中找到相应函数并测试。
import torch
import matplotlib.pyplot as plt
# 在[-10,10]的范围内生成一系列的输入值,用于绘制relu、leaky_relu的函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), torch.nn.functional.relu(z).tolist(), color="#e4007f", label="ReLU Function")
plt.plot(z.tolist(), torch.nn.functional.leaky_relu(z).tolist(), color="#f19ec2", linestyle="--", label="LeakyReLU Function")
ax = plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='upper left', fontsize='large')
plt.savefig('fw-relu-leakyrelu.pdf')
plt.show()
4.2 基于前馈神经网络的二分类任务
4.2.1 数据集构建
使用第3.1.1节中构建的二分类数据集:Moon1000数据集,其中训练集640条、验证集160条、测试集200条。该数据集的数据是从两个带噪音的弯月形状数据分布中采样得到,每个样本包含2个特征。
这里把Moon1000数据集再写一遍,方便大家看
import math
import copy
import torch
def make_moons(n_samples=1000, shuffle=True, noise=None):
"""
生成带噪音的弯月形状数据
输入:
- n_samples:数据量大小,数据类型为int
- shuffle:是否打乱数据,数据类型为bool
- noise:以多大的程度增加噪声,数据类型为None或float,noise为None时表示不增加噪声
输出:
- X:特征数据,shape=[n_samples,2]
- y:标签数据, shape=[n_samples]
"""
n_samples_out = n_samples // 2
n_samples_in = n_samples - n_samples_out
# 采集第1类数据,特征为(x,y)
# 使用'paddle.linspace'在0到pi上均匀取n_samples_out个值
# 使用'paddle.cos'计算上述取值的余弦值作为特征1,使用'paddle.sin'计算上述取值的正弦值作为特征2
outer_circ_x = torch.cos(torch.linspace(0, math.pi, n_samples_out))
outer_circ_y = torch.sin(torch.linspace(0, math.pi, n_samples_out))
inner_circ_x = 1 - torch.cos(torch.linspace(0, math.pi, n_samples_in))
inner_circ_y = 0.5 - torch.sin(torch.linspace(0, math.pi, n_samples_in))
print('outer_circ_x.shape:', outer_circ_x.shape, 'outer_circ_y.shape:', outer_circ_y.shape)
print('inner_circ_x.shape:', inner_circ_x.shape, 'inner_circ_y.shape:', inner_circ_y.shape)
# 使用'paddle.concat'将两类数据的特征1和特征2分别延维度0拼接在一起,得到全部特征1和特征2
# 使用'paddle.stack'将两类特征延维度1堆叠在一起
X = torch.stack(
[torch.cat([outer_circ_x, inner_circ_x]),
torch.cat([outer_circ_y, inner_circ_y])],
dim=1
)
print('after concat shape:', torch.cat([outer_circ_x, inner_circ_x]).shape)
print('X shape:', X.shape)
# 使用'paddle. zeros'将第一类数据的标签全部设置为0
# 使用'paddle. ones'将第一类数据的标签全部设置为1
y = torch.cat(
[torch.zeros(size=[n_samples_out]), torch.ones(size=[n_samples_in])]
)
print('y shape:', y.shape)
# 如果shuffle为True,将所有数据打乱
if shuffle:
# 使用'paddle.randperm'生成一个数值在0到X.shape[0],随机排列的一维Tensor做索引值,用于打乱数据
idx = torch.randperm(X.shape[0])
X = X[idx]
y = y[idx]
# 如果noise不为None,则给特征值加入噪声
if noise is not None:
# 使用'paddle.normal'生成符合正态分布的随机Tensor作为噪声,并加到原始特征上
X += torch.normal(mean=0.0, std=noise, size=X.shape)
return X, y然后构建数据集
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.5)
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
y_train = y_train.reshape([-1,1])
y_dev = y_dev.reshape([-1,1])
y_test = y_test.reshape([-1,1])得到以下结果:
outer_circ_x.shape: torch.Size([500]) outer_circ_y.shape: torch.Size([500])
inner_circ_x.shape: torch.Size([500]) inner_circ_y.shape: torch.Size([500])
after concat shape: torch.Size([1000])
X shape: torch.Size([1000, 2])
y shape: torch.Size([1000])4.2.2 模型构建
为了更高效的构建前馈神经网络,我们先定义每一层的算子,然后再通过算子组合构建整个前馈神经网络。

4.2.2.1 线性层算子
公式(4.8)对应一个线性层算子,权重参数采用默认的随机初始化,偏置采用默认的零初始化。代码实现如下:
from op import Op
class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=torch.randn, bias_init=torch.zeros):
"""
输入:
- input_size:输入数据维度
- output_size:输出数据维度
- name:算子名称
- weight_init:权重初始化方式,默认使用'torch.randn'进行标准正态分布初始化
- bias_init:偏置初始化方式,默认使用全0初始化
"""
self.params = {}
# 初始化权重
self.params['W'] = weight_init(size=[input_size, output_size])
# 初始化偏置
self.params['b'] = bias_init(size=[1, output_size])
self.inputs = None
self.name = name
def forward(self, inputs):
"""
输入:
- inputs:shape=[N,input_size], N是样本数量
输出:
- outputs:预测值,shape=[N,output_size]
"""
self.inputs = inputs.to(torch.float32)
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs
4.2.2.2 Logistic算子(激活函数)
本节我们采用Logistic函数来作为公式(4.9)中的激活函数。这里也将Logistic函数实现一个算子,代码实现如下:
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
def forward(self, inputs):
"""
输入:
- inputs: shape=[N,D]
输出:
- outputs:shape=[N,D]
"""
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs
4.2.2.3 层的串行组合
实现一个两层的用于二分类任务的前馈神经网络,选用Logistic作为激活函数,可以利用上面实现的线性层和激活函数算子来组装
class Model_MLP_L2(Op):
def __init__(self, input_size, hidden_size, output_size):
"""
输入:
- input_size:输入维度
- hidden_size:隐藏层神经元数量
- output_size:输出维度
"""
self.fc1 = Linear(input_size, hidden_size, name="fc1")
self.act_fn1 = Logistic()
self.fc2 = Linear(hidden_size, output_size, name="fc2")
self.act_fn2 = Logistic()
def __call__(self, X):
return self.forward(X)
def forward(self, X):
"""
输入:
- X:shape=[N,input_size], N是样本数量
输出:
- a2:预测值,shape=[N,output_size]
"""
z1 = self.fc1(X)
a1 = self.act_fn1(z1)
z2 = self.fc2(a1)
a2 = self.act_fn2(z2)
return a2实例化一个两层的前馈网络,令其输入层维度为5,隐藏层维度为10,输出层维度为1。
并随机生成一条长度为5的数据输入两层神经网络,观察输出结果。
model = Model_MLP_L2(input_size=5, hidden_size=10, output_size=1)
# 随机生成1条长度为5的数据
X = torch.rand(size=[1, 5])
result = model(X)
print ("result: ", result)得到以下结果:
result: tensor([[0.1737]])4.2.3 损失函数
二分类交叉熵损失函数见第三章,这里我再赘述一下。
import op
class BinaryCrossEntropyLoss(op.Op):
def __init__(self):
self.predicts = None
self.labels = None
self.num = None
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
"""
输入:
- predicts:预测值,shape=[N, 1],N为样本数量
- labels:真实标签,shape=[N, 1]
输出:
- 损失值:shape=[1]
"""
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts)) + torch.matmul((1-self.labels.t()), torch.log(1-self.predicts)))
loss = torch.squeeze(loss, dim=1)
return loss
# 测试一下
# 生成一组长度为3,值为1的标签数据
labels = torch.ones(size=[3,1])
# 计算风险函数
bce_loss = BinaryCrossEntropyLoss()
print(bce_loss(outputs, labels))得到以下结果:
tensor([0.6931])4.2.4 模型优化
神经网络的层数通常比较深,其梯度计算和上一章中的线性分类模型的不同的点在于:
线性模型通常比较简单可以直接计算梯度,而神经网络相当于一个复合函数,需要利用链式法则进行反向传播来计算梯度。
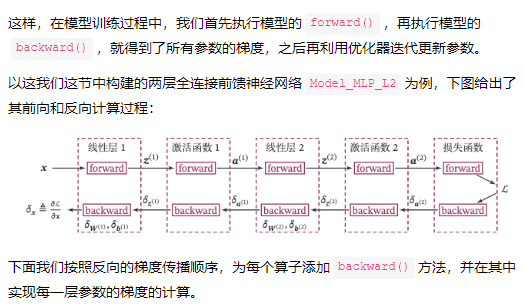
4.2.4.1 反向传播算法
 第1步是前向计算,可以利用算子的forward()方法来实现;
第1步是前向计算,可以利用算子的forward()方法来实现;
第2步是反向计算梯度,可以利用算子的backward()方法来实现;
第3步中的计算参数梯度也放到backward()中实现,更新参数放到另外的优化器中专门进行。
4.2.4.2 损失函数
二分类交叉熵损失函数

实现损失函数的backward()
class BinaryCrossEntropyLoss(Op):
def __init__(self, model):
self.predicts = None
self.labels = None
self.num = None
self.model = model
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
"""
输入:
- predicts:预测值,shape=[N, 1],N为样本数量
- labels:真实标签,shape=[N, 1]
输出:
- 损失值:shape=[1]
"""
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts))
+ torch.matmul((1 - self.labels.t()), torch.log(1 - self.predicts)))
loss = torch.squeeze(loss, dim=1)
return loss
def backward(self):
# 计算损失函数对模型预测的导数
loss_grad_predicts = -1.0 * (self.labels / self.predicts -
(1 - self.labels) / (1 - self.predicts)) / self.num
# 梯度反向传播
self.model.backward(loss_grad_predicts)4.2.4.3 Logistic算子
 由于Logistic函数中没有参数,这里不需要在
由于Logistic函数中没有参数,这里不需要在backward()方法中计算该算子参数的梯度
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
self.params = None
def forward(self, inputs):
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs
def backward(self, grads):
# 计算Logistic激活函数对输入的导数
outputs_grad_inputs = torch.multiply(self.outputs, (1.0 - self.outputs))
return torch.multiply(grads,outputs_grad_inputs)
4.2.4.4 线性层


class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=torch.randn, bias_init=torch.zeros):
self.params = {}
self.params['W'] = weight_init(size=[input_size, output_size])
self.params['b'] = bias_init(size=[1, output_size])
self.inputs = None
self.grads = {}
self.name = name
def forward(self, inputs):
self.inputs = inputs
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs
def backward(self, grads):
"""
输入:
- grads:损失函数对当前层输出的导数
输出:
- 损失函数对当前层输入的导数
"""
self.grads['W'] = torch.matmul(self.inputs.T, grads)
self.grads['b'] = torch.sum(grads, axis=0)
# 线性层输入的梯度
return torch.matmul(grads, self.params['W'].T)
4.2.4.5 整个网络
实现完整的两层神经网络的前向和反向计算
class Model_MLP_L2(Op):
def __init__(self, input_size, hidden_size, output_size):
# 线性层
self.fc1 = Linear(input_size, hidden_size, name="fc1")
# Logistic激活函数层
self.act_fn1 = Logistic()
self.fc2 = Linear(hidden_size, output_size, name="fc2")
self.act_fn2 = Logistic()
self.layers = [self.fc1, self.act_fn1, self.fc2, self.act_fn2]
def __call__(self, X):
return self.forward(X)
# 前向计算
def forward(self, X):
z1 = self.fc1(X)
a1 = self.act_fn1(z1)
z2 = self.fc2(a1)
a2 = self.act_fn2(z2)
return a2
# 反向计算
def backward(self, loss_grad_a2):
loss_grad_z2 = self.act_fn2.backward(loss_grad_a2)
loss_grad_a1 = self.fc2.backward(loss_grad_z2)
loss_grad_z1 = self.act_fn1.backward(loss_grad_a1)
loss_grad_inputs = self.fc1.backward(loss_grad_z1)
4.2.4.6 优化器
在计算好神经网络参数的梯度之后,我们将梯度下降法中参数的更新过程实现在优化器中。
与第3章中实现的梯度下降优化器SimpleBatchGD不同的是,此处的优化器需要遍历每层,对每层的参数分别做更新。
from opitimizer import Optimizer
class BatchGD(Optimizer):
def __init__(self, init_lr, model):
super(BatchGD, self).__init__(init_lr=init_lr, model=model)
def step(self):
# 参数更新
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
for key in layer.params.keys():
layer.params[key] = layer.params[key] - self.init_lr * layer.grads[key]
4.2.5 完善Runner类:RunnerV2_1
支持自定义算子的梯度计算,在训练过程中调用self.loss_fn.backward()从损失函数开始反向计算梯度;
每层的模型保存和加载,将每一层的参数分别进行保存和加载。
import os
class RunnerV2_1(object):
def __init__(self, model, optimizer, metric, loss_fn, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
# 记录训练过程中的评估指标变化情况
self.train_scores = []
self.dev_scores = []
# 记录训练过程中的评价指标变化情况
self.train_loss = []
self.dev_loss = []
def train(self, train_set, dev_set, **kwargs):
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_epochs = kwargs.get("log_epochs", 100)
# 传入模型保存路径
save_dir = kwargs.get("save_dir", None)
# 记录全局最优指标
best_score = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
X, y = train_set
# 获取模型预测
logits = self.model(X)
# 计算交叉熵损失
trn_loss = self.loss_fn(logits, y) # return a tensor
self.train_loss.append(trn_loss.item())
# 计算评估指标
trn_score = self.metric(logits, y).item()
self.train_scores.append(trn_score)
self.loss_fn.backward()
# 参数更新
self.optimizer.step()
dev_score, dev_loss = self.evaluate(dev_set)
# 如果当前指标为最优指标,保存该模型
if dev_score > best_score:
print(f"[Evaluate] best accuracy performence has been updated: {best_score:.5f} --> {dev_score:.5f}")
best_score = dev_score
if save_dir:
self.save_model(save_dir)
if log_epochs and epoch % log_epochs == 0:
print(f"[Train] epoch: {epoch}/{num_epochs}, loss: {trn_loss.item()}")
def evaluate(self, data_set):
X, y = data_set
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
self.dev_loss.append(loss)
# 计算评估指标
score = self.metric(logits, y).item()
self.dev_scores.append(score)
return score, loss
def predict(self, X):
return self.model(X)
def save_model(self, save_dir):
# 对模型每层参数分别进行保存,保存文件名称与该层名称相同
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
torch.save(layer.params, os.path.join(save_dir, layer.name + ".pdparams"))
def load_model(self, model_dir):
# 获取所有层参数名称和保存路径之间的对应关系
model_file_names = os.listdir(model_dir)
name_file_dict = {}
for file_name in model_file_names:
name = file_name.replace(".pdparams", "")
name_file_dict[name] = os.path.join(model_dir, file_name)
# 加载每层参数
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
name = layer.name
file_path = name_file_dict[name]
layer.params = torch.load(file_path)
4.2.6 模型训练
使用训练集和验证集进行模型训练,共训练2000个epoch。评价指标为accuracy。
from metric import accuracy
torch.manual_seed(123)
epoch_num = 1000
model_saved_dir = "r"C:\Users\DELL\PycharmProjects\pythonProject\CSDN""
# 输入层维度为2
input_size = 2
# 隐藏层维度为5
hidden_size = 5
# 输出层维度为1
output_size = 1
# 定义网络
model = Model_MLP_L2(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# 损失函数
loss_fn = BinaryCrossEntropyLoss(model)
# 优化器
learning_rate = 0.2
optimizer = BatchGD(learning_rate, model)
# 评价方法
metric = accuracy
# 实例化RunnerV2_1类,并传入训练配置
runner = RunnerV2_1(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=epoch_num, log_epochs=50, save_dir=model_saved_dir)
得到以下结果:
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.16875
[Train] epoch: 0/1000, loss: 0.7350932955741882
[Evaluate] best accuracy performence has been updated: 0.16875 --> 0.17500
[Evaluate] best accuracy performence has been updated: 0.17500 --> 0.18750
[Evaluate] best accuracy performence has been updated: 0.18750 --> 0.20000
[Evaluate] best accuracy performence has been updated: 0.20000 --> 0.21250
[Evaluate] best accuracy performence has been updated: 0.21250 --> 0.22500
[Evaluate] best accuracy performence has been updated: 0.22500 --> 0.25000
[Evaluate] best accuracy performence has been updated: 0.25000 --> 0.31250
[Evaluate] best accuracy performence has been updated: 0.31250 --> 0.37500
[Evaluate] best accuracy performence has been updated: 0.37500 --> 0.43750
[Evaluate] best accuracy performence has been updated: 0.43750 --> 0.46250
[Evaluate] best accuracy performence has been updated: 0.46250 --> 0.48125
[Evaluate] best accuracy performence has been updated: 0.48125 --> 0.49375
[Evaluate] best accuracy performence has been updated: 0.49375 --> 0.51250
[Evaluate] best accuracy performence has been updated: 0.51250 --> 0.55625
[Evaluate] best accuracy performence has been updated: 0.55625 --> 0.60625
[Evaluate] best accuracy performence has been updated: 0.60625 --> 0.61875
[Evaluate] best accuracy performence has been updated: 0.61875 --> 0.63750
[Evaluate] best accuracy performence has been updated: 0.63750 --> 0.65000
[Evaluate] best accuracy performence has been updated: 0.65000 --> 0.66250
[Evaluate] best accuracy performence has been updated: 0.66250 --> 0.66875
[Evaluate] best accuracy performence has been updated: 0.66875 --> 0.67500
[Evaluate] best accuracy performence has been updated: 0.67500 --> 0.68125
[Evaluate] best accuracy performence has been updated: 0.68125 --> 0.68750
[Evaluate] best accuracy performence has been updated: 0.68750 --> 0.69375
[Evaluate] best accuracy performence has been updated: 0.69375 --> 0.70000
[Evaluate] best accuracy performence has been updated: 0.70000 --> 0.71250
[Evaluate] best accuracy performence has been updated: 0.71250 --> 0.71875
[Train] epoch: 50/1000, loss: 0.664116382598877
[Evaluate] best accuracy performence has been updated: 0.71875 --> 0.72500
[Evaluate] best accuracy performence has been updated: 0.72500 --> 0.73750
[Evaluate] best accuracy performence has been updated: 0.73750 --> 0.74375
[Evaluate] best accuracy performence has been updated: 0.74375 --> 0.75000
[Evaluate] best accuracy performence has been updated: 0.75000 --> 0.76250
[Evaluate] best accuracy performence has been updated: 0.76250 --> 0.76875
[Evaluate] best accuracy performence has been updated: 0.76875 --> 0.78125
[Evaluate] best accuracy performence has been updated: 0.78125 --> 0.79375
[Evaluate] best accuracy performence has been updated: 0.79375 --> 0.80625
[Evaluate] best accuracy performence has been updated: 0.80625 --> 0.81250
[Train] epoch: 100/1000, loss: 0.5949881076812744
[Evaluate] best accuracy performence has been updated: 0.81250 --> 0.81875
[Evaluate] best accuracy performence has been updated: 0.81875 --> 0.82500
[Evaluate] best accuracy performence has been updated: 0.82500 --> 0.83125
[Evaluate] best accuracy performence has been updated: 0.83125 --> 0.83750
[Train] epoch: 150/1000, loss: 0.5277273058891296
[Train] epoch: 200/1000, loss: 0.485870361328125
[Train] epoch: 250/1000, loss: 0.46499910950660706
[Train] epoch: 300/1000, loss: 0.4550503194332123
[Train] epoch: 350/1000, loss: 0.45022842288017273
[Train] epoch: 400/1000, loss: 0.44782382249832153
[Train] epoch: 450/1000, loss: 0.44659096002578735
[Evaluate] best accuracy performence has been updated: 0.83750 --> 0.84375
[Train] epoch: 500/1000, loss: 0.44594064354896545
[Evaluate] best accuracy performence has been updated: 0.84375 --> 0.85000
[Evaluate] best accuracy performence has been updated: 0.85000 --> 0.85625
[Train] epoch: 550/1000, loss: 0.44558531045913696
[Train] epoch: 600/1000, loss: 0.4453815519809723
[Evaluate] best accuracy performence has been updated: 0.85625 --> 0.86250
[Train] epoch: 650/1000, loss: 0.44525671005249023
[Train] epoch: 700/1000, loss: 0.4451737403869629
[Train] epoch: 750/1000, loss: 0.4451136589050293
[Train] epoch: 800/1000, loss: 0.4450666606426239
[Train] epoch: 850/1000, loss: 0.4450274407863617
[Train] epoch: 900/1000, loss: 0.4449935853481293
[Train] epoch: 950/1000, loss: 0.44496336579322815当我把训练变成2000次后得到结果:
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.21250
[Train] epoch: 0/2000, loss: 0.738420844078064
[Evaluate] best accuracy performence has been updated: 0.21250 --> 0.21875
[Evaluate] best accuracy performence has been updated: 0.21875 --> 0.23750
[Evaluate] best accuracy performence has been updated: 0.23750 --> 0.24375
[Evaluate] best accuracy performence has been updated: 0.24375 --> 0.26875
[Evaluate] best accuracy performence has been updated: 0.26875 --> 0.27500
[Evaluate] best accuracy performence has been updated: 0.27500 --> 0.28750
[Evaluate] best accuracy performence has been updated: 0.28750 --> 0.30000
[Evaluate] best accuracy performence has been updated: 0.30000 --> 0.31875
[Evaluate] best accuracy performence has been updated: 0.31875 --> 0.35625
[Evaluate] best accuracy performence has been updated: 0.35625 --> 0.37500
[Evaluate] best accuracy performence has been updated: 0.37500 --> 0.41250
[Evaluate] best accuracy performence has been updated: 0.41250 --> 0.43125
[Evaluate] best accuracy performence has been updated: 0.43125 --> 0.45000
[Evaluate] best accuracy performence has been updated: 0.45000 --> 0.46875
[Evaluate] best accuracy performence has been updated: 0.46875 --> 0.47500
[Evaluate] best accuracy performence has been updated: 0.47500 --> 0.49375
[Evaluate] best accuracy performence has been updated: 0.49375 --> 0.52500
[Evaluate] best accuracy performence has been updated: 0.52500 --> 0.58125
[Evaluate] best accuracy performence has been updated: 0.58125 --> 0.61875
[Evaluate] best accuracy performence has been updated: 0.61875 --> 0.66250
[Evaluate] best accuracy performence has been updated: 0.66250 --> 0.66875
[Evaluate] best accuracy performence has been updated: 0.66875 --> 0.70000
[Evaluate] best accuracy performence has been updated: 0.70000 --> 0.71875
[Evaluate] best accuracy performence has been updated: 0.71875 --> 0.73125
[Evaluate] best accuracy performence has been updated: 0.73125 --> 0.73750
[Evaluate] best accuracy performence has been updated: 0.73750 --> 0.74375
[Evaluate] best accuracy performence has been updated: 0.74375 --> 0.75000
[Evaluate] best accuracy performence has been updated: 0.75000 --> 0.76875
[Train] epoch: 50/2000, loss: 0.6566254496574402
[Evaluate] best accuracy performence has been updated: 0.76875 --> 0.77500
[Evaluate] best accuracy performence has been updated: 0.77500 --> 0.78125
[Evaluate] best accuracy performence has been updated: 0.78125 --> 0.78750
[Evaluate] best accuracy performence has been updated: 0.78750 --> 0.79375
[Train] epoch: 100/2000, loss: 0.5740222334861755
[Train] epoch: 150/2000, loss: 0.49713021516799927
[Evaluate] best accuracy performence has been updated: 0.79375 --> 0.80000
[Train] epoch: 200/2000, loss: 0.4507133662700653
[Train] epoch: 250/2000, loss: 0.426734060049057
[Train] epoch: 300/2000, loss: 0.41436272859573364
[Train] epoch: 350/2000, loss: 0.4077704846858978
[Train] epoch: 400/2000, loss: 0.4041588008403778
[Train] epoch: 450/2000, loss: 0.40213823318481445
[Train] epoch: 500/2000, loss: 0.40098461508750916
[Train] epoch: 550/2000, loss: 0.400308221578598
[Train] epoch: 600/2000, loss: 0.39989611506462097
[Train] epoch: 650/2000, loss: 0.39963141083717346
[Train] epoch: 700/2000, loss: 0.39944973587989807
[Train] epoch: 750/2000, loss: 0.39931559562683105
[Train] epoch: 800/2000, loss: 0.39920955896377563
[Train] epoch: 850/2000, loss: 0.39912062883377075
[Train] epoch: 900/2000, loss: 0.3990428149700165
[Train] epoch: 950/2000, loss: 0.3989725708961487
[Train] epoch: 1000/2000, loss: 0.3989078998565674
[Train] epoch: 1050/2000, loss: 0.39884766936302185
[Train] epoch: 1100/2000, loss: 0.39879104495048523
[Train] epoch: 1150/2000, loss: 0.39873751997947693
[Train] epoch: 1200/2000, loss: 0.39868679642677307
[Train] epoch: 1250/2000, loss: 0.39863845705986023
[Train] epoch: 1300/2000, loss: 0.39859244227409363
[Train] epoch: 1350/2000, loss: 0.3985483944416046
[Train] epoch: 1400/2000, loss: 0.398506224155426
[Train] epoch: 1450/2000, loss: 0.3984657824039459
[Train] epoch: 1500/2000, loss: 0.39842694997787476
[Train] epoch: 1550/2000, loss: 0.3983895480632782
[Train] epoch: 1600/2000, loss: 0.3983535170555115
[Train] epoch: 1650/2000, loss: 0.39831873774528503
[Train] epoch: 1700/2000, loss: 0.39828506112098694
[Train] epoch: 1750/2000, loss: 0.3982524871826172
[Train] epoch: 1800/2000, loss: 0.39822086691856384
[Train] epoch: 1850/2000, loss: 0.3981901705265045
[Train] epoch: 1900/2000, loss: 0.39816027879714966
[Train] epoch: 1950/2000, loss: 0.39813119173049927发现结果更好了,损失降低。
可视化观察训练集与验证集的损失函数变化情况。
plt.figure()
plt.plot(range(epoch_num), runner.train_loss, color="#e4007f", label="Train loss")
plt.plot(range(epoch_num), runner.dev_loss, color="#f19ec2", linestyle='--', label="Dev loss")
plt.xlabel("epoch", fontsize='large')
plt.ylabel("loss", fontsize='large')
plt.legend(fontsize='x-large')
plt.savefig('fw-loss2.pdf')
plt.show()

4.2.7 性能评价
使用测试集对训练中的最优模型进行评价,观察模型的评价指标。
# 加载训练好的模型
runner.load_model(model_saved_dir)
# 在测试集上对模型进行评价
score, loss = runner.evaluate([X_test, y_test])
print("[Test] score/loss: {:.4f}/{:.4f}".format(score, loss))
[Test] score/loss: 0.7750/0.4362可视化:
import math
# 均匀生成40000个数据点
x1, x2 = torch.meshgrid(torch.linspace(-math.pi, math.pi, 200), torch.linspace(-math.pi, math.pi, 200))
x = torch.stack([torch.flatten(x1), torch.flatten(x2)], dim=1)
# 预测对应类别
y = runner.predict(x)
y = torch.squeeze(torch.as_tensor((y>=0.5),dtype=torch.float32),dim=-1)
# 绘制类别区域
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(x[:,0].tolist(), x[:,1].tolist(), c=y.tolist(), cmap=plt.cm.Spectral)
plt.scatter(X_train[:, 0].tolist(), X_train[:, 1].tolist(), marker='*', c=torch.squeeze(y_train,dim=-1).tolist())
plt.scatter(X_dev[:, 0].tolist(), X_dev[:, 1].tolist(), marker='*', c=torch.squeeze(y_dev,dim=-1).tolist())
plt.scatter(X_test[:, 0].tolist(), X_test[:, 1].tolist(), marker='*', c=torch.squeeze(y_test,dim=-1).tolist())

【思考题】对比
3.1 基于Logistic回归的二分类任务 4.2 基于前馈神经网络的二分类任务
谈谈自己的看法
在这两次的实验中Logistic回归和前馈神经网络的二分类任务感觉效果差不多,但是在做实验的过程中总是隐约的感到逻辑回归的存在,所以我认为神经网络可以看做是多个逻辑回归模型组成,可以说神经网络出于逻辑回归,但胜于逻辑回归。而且逻辑回归也可以看成是只有输入层和输出层,输出层只有一个神经元的神经网络。逻辑回归模型最后计算输出的只有1个,而神经网络可以有多个。
虽然说这两次二分类任务中前馈神经网络和Logistic回归的效果差不多,但是在多分类任务和数据量比较大的任务的时候Logistic回归肯定是不如神经网络的。逻辑回归所有参数的更新是基于相同的式子,也就是所有参数的更新是基于相同的规则。 相比之下,神经网络每两个神经元之间参数的更新都基于不同式子,也就是每个参数的更新都是用不同的规则。显而易见,神经网络模型能模拟和挖掘出更多复杂的关系,也具有更好的预测效果。
实验总结:
这次实验搭建了一个简单的两层前馈神经网络,写的时候还是比较熟悉的,毕竟上学期也做过类似实验,这次实验中也有个小问题就是在保存模型的时候发现总是不对,后来跟同学交流的时候发现是因为这次保存的是一个文件夹而不是文件,但是在对路径改完后发现又有个错误就是
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape这是因为window 读取文件可以用\,但是在字符串中\是被当作转义字符来使用,经过转义之后可能就找不到路径的资源了,例如\t会转义为tab键。这里有三种方法来解决。
一:更换为绝对路径的写法\\
二:显式声明字符串不用转义(加r)
三:使用Linux的路径/
最后做思考题的时候发现二分类的神经网络和逻辑回归差不多,但是对比一下发现神经网络要比逻辑回归好很多。这里参考文献每天十分钟机器学习之二十二:神经网络为什么比逻辑回归厉害 - 腾讯云开发者社区-腾讯云
(36条消息) 机器学习/CNN系列小问题(1):逻辑回归和神经网络之间有什么关系?_tina_ttl的博客-CSDN博客_logistic回归和神经网络
















 4976
4976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











