










TensorFlow的RTX 2080 Ti深度学习基准-2020年
在本文中,Lambda讨论了RTX 2080 Ti与其他GPU相比的深度学习性能。我们使用RTX 2080 Ti来训练ResNet-50,ResNet-152,Inception v3,Inception v4,VGG-16,AlexNet和SSD300。我们在训练每个网络时测量每秒处理的图像数。
一些注意事项:
- 我们使用TensorFlow 1.12 / CUDA 10.0.130 / cuDNN 7.4.1
- 单GPU基准测试在Lambda的深度学习工作站上运行
- 多GPU基准测试在Lambda刀片上运行-深度学习服务器
- V100基准在Lambda Hyperplane上运行-Tesla V100服务器
- Tensor Core已在所有具有Tensor Core的GPU上使用
RTX 2080 Ti-FP32 TensorFlow性能(1 GPU)
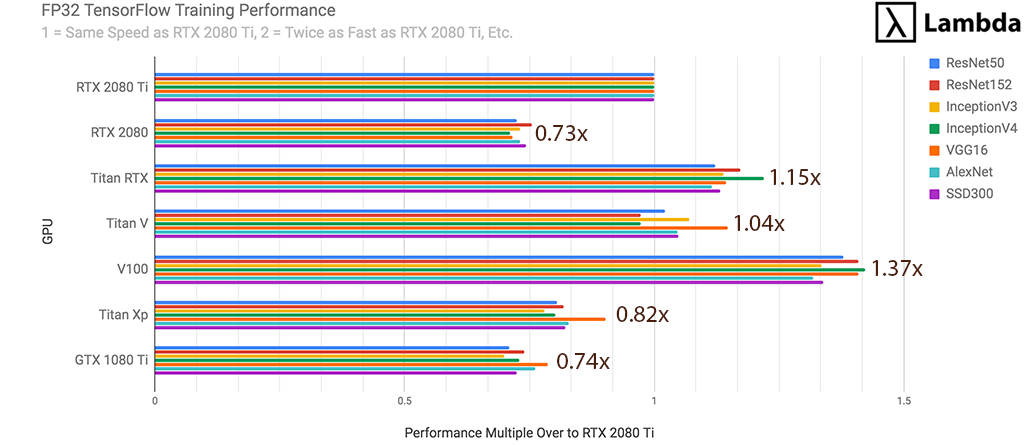
对于神经网络的FP32训练,RTX 2080 Ti是...
- 比RTX 2080快37%
- 比GTX 1080 Ti快35%
- 比Titan XP快22%
- 速度是Titan V的96%
- 相当于Titan RTX的87%
- 与Tesla V100(32 GB)一样快73%
通过训练期间每秒处理的#张图像来衡量。
RTX 2080 Ti-FP16 TensorFlow性能(1 GPU)
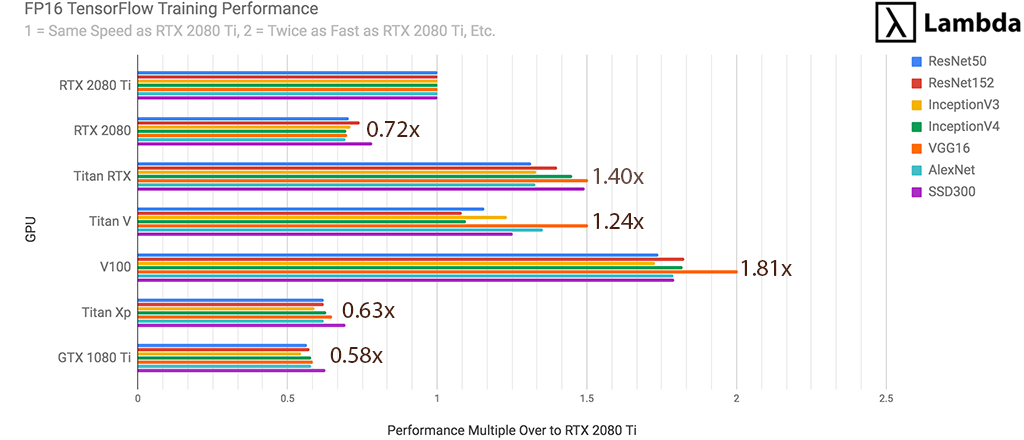
RTX 2080 Ti用于神经网络的FP16训练。
- 比GTX 1080 Ti快72%
- 比Titan XP快59%
- 比RTX 2080快32%
- 速度是Titan V的81%
- 速度是Titan RTX的71%
- 速度是Tesla V100(32 GB)的55%
通过训练期间每秒处理的#张图像来衡量。
FP32多GPU扩展性能(1、2、4、8 GPU)
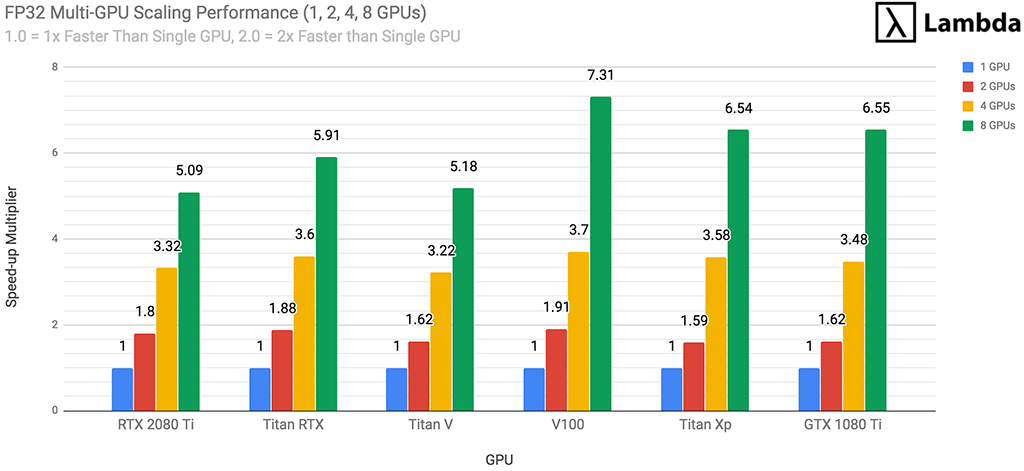
对于每种GPU类型(RTX 2080 Ti,RTX 2080等),我们在训练每个神经网络上的1、2、4和8个GPU时进行性能测试,然后取平均结果。下图提供了有关在FP32中对神经网络进行多GPU训练期间如何扩展每个GPU的指南。RTX 2080 Ti的缩放比例如下:
- 2个RTX 2080 Ti GPU的训练速度将比1个RTX 2080 Ti快1.8倍
- 4个RTX 2080 Ti GPU的训练速度将比1个RTX 2080 Ti快约3.3倍
- 8倍RTX 2080 Ti GPU的训练速度将比1倍RTX 2080 Ti快约5.1倍
RTX 2080 Ti-FP16和FP32
使用FP16可以减少训练时间并支持更大的批次大小/模型,而不会显着影响训练模型的准确性。与FP32相比,RTX 2080 Ti上的FP16培训是...
- 在ResNet-50上快59%
- 在ResNet-152上快52%
- Inception v3快47%
- 在Inception v4上快34%
- 在VGG-16上快50%
- 在AlexNet上快38%
- SSD300快31%
通过训练期间每秒处理的图像数来衡量。平均速度提高了+ 44.6%。
警告:如果您是机器学习的新手,或者只是测试代码,我们建议使用FP32。将精度降低到FP16可能会干扰收敛。
GPU价格
- RTX 2080 Ti:1,199.00美元
- RTX 2080:799.00美元
- 泰坦RTX:2,499.00美元
- 泰坦五世:$ 2,999.00
- 特斯拉V100(32 GB):〜$ 8,200.00
- GTX 1080 Ti:699.00美元
- Titan Xp:1,200.00美元
方法
- 对于每个模型,我们进行了10次训练实验,并测量了每秒处理的图像数量;然后,我们将10个实验的结果取平均值。
- 对于每个GPU /神经网络组合,我们使用了适合内存的最大批处理大小。例如,在ResNet-50上,V100的批处理大小为192;RTX 2080 Ti使用的批处理大小为64。
- 我们使用合成数据而非真实数据来最大程度地减少与GPU不相关的瓶颈
- 多GPU训练是使用模型级并行性进行的
硬件
- 单GPU培训:Lambda Quad深度学习工作站。CPU:i9-7920X / RAM:64 GB DDR4 2400 MHz
- 多GPU培训:Lambda Blade-深度学习服务器。CPU:至强E5-2650 v4 / RAM:128 GB DDR4 2400 MHz ECC
- V100基准:Lambda Hyperplane-V100服务器。CPU:至强金牌6148 / RAM:256 GB DDR4 2400 MHz ECC
软件
- Ubuntu 18.04(仿生)
- TensorFlow 1.12
- CUDA 10.0.130
- cuDNN 7.4.1
在您自己的计算机上运行基准测试
我们的基准测试代码在github上。如果您通过发送电子邮件至s@lambdalabs.com或发推文@LambdaAPI与我们共享结果,我们将非常乐意。
步骤1:克隆基准存储库
git clone https://github.com/lambdal/lambda-tensorflow-benchmark.git --recursive
步骤2:运行基准测试
- 输入正确的gpu_index(默认值为0)和num_iterations(默认值为10)
cd lambda-tensorflow-benchmark
./benchmark.sh gpu_index num_iterations
步骤3:报告结果
- 检查repo目录中的文件夹<cpu>-<gpu> .logs(由Benchmark.sh生成)
- 在基准测试和报告中使用相同的num_iterations。
./report.sh <cpu>-<gpu>.logs num_iterations
原始基准数据
FP32:在TensorFlow训练期间按每秒处理的图像数量(1个GPU)
| 型号/ GPU | RTX 2080钛 | RTX 2080 | 泰坦RTX | 泰坦五世 | V100 | 泰坦Xp | 1080钛 |
|---|---|---|---|---|---|---|---|
| ResNet-50 | 294 | 213 | 330 | 300 | 405 | 236 | 209 |
| ResNet-152 | 110 | 83 | 129 | 107 | 155 | 90 | 81 |
| 盗梦空间v3 | 194 | 142 | 221 | 208 | 259 | 151 | 136 |
| 盗梦空间v4 | 79 | 56 | 96 | 77 | 112 | 63 | 58 |
| VGG16 | 170 | 122 | 195 | 195 | 240 | 154 | 134 |
| 亚历克斯网 | 3627 | 2650 | 4046 | 3796 | 4782 | 3004 | 2762 |
| 固态硬盘300 | 149 | 111 | 169 | 156 | 200 | 123 | 108 |
FP16:在TensorFlow训练期间按每秒处理的图像数量(1个GPU)
| 型号/ GPU | RTX 2080钛 | RTX 2080 | 泰坦RTX | 泰坦五世 | V100 | 泰坦Xp | 1080钛 |
|---|---|---|---|---|---|---|---|
| ResNet-50 | 466 | 329 | 612 | 539 | 811 | 289 | 263 |
| ResNet-152 | 167 | 124 | 234 | 181 | 305 | 104 | 96 |
| 盗梦空间v3 | 286 | 203 | 381 | 353 | 494 | 169 | 156 |
| 盗梦空间v4 | 106 | 74 | 154 | 116 | 193 | 67 | 62 |
| VGG16 | 255 | 178 | 383 | 383 | 511 | 166 | 149 |
| 亚历克斯网 | 4988 | 3458 | 6627 | 6746 | 8922 | 3104 | 2891 |
| 固态硬盘300 | 195 | 153 | 292 | 245 | 350 | 136 | 123 |


















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











