






日期
2023.11.04
论文标题
Ghost-free High Dynamic Range Imaging with Context-aware Transformer
摘要
多帧高动态范围成像(High Dynamic Range Imaging, HDR)旨在通过合并多幅不同曝光程度下的低动态范围图像,生成具有更宽动态范围和更逼真细节的图像。如果这些低动态范围图像完全对齐,则可以很好地融合为HDR图像,但是,实际拍摄到的图像容易受到相机、物体运动的干扰,三张低动态范围图像往往不能很好地得到对齐,直接对三图像做融合的话,所生成的图像容易产生伪影、重影。,本文提出了一种新的上下文感知视觉转换器(CA-VIT)用于高动态范围成像。 CA-VIT被设计为一个双分支体系结构,可以联合捕获全局和局部依赖关系。 具体来说,全局分支采用基于窗口的变压器编码器来模拟远距离物体运动和强度变化,以解决重影问题。 对于局部分支,我们设计了一个局部上下文提取器(LCE)来捕获图像的短程特征,并利用通道关注机制在提取的特征中选择信息丰富的局部细节来补充全局分支。 通过将CA-VIT作为基本组件,我们进一步构建了HDR-Transformer这一层次化网络来重建高质量的无鬼影HDR图像。 在三个基准数据集上进行的大量实验表明,我们的方法在定性和定量方面都优于现有的方法,并大大减少了计算预算。
引用信息(BibTeX格式)
@inproceedings{liu2022ghost,
title={Ghost-free High Dynamic Range Imaging with Context-aware Transformer},
author={Liu, Zhen and Wang, Yinglong and Zeng, Bing and Liu, Shuaicheng},
booktitle={European Conference on Computer Vision},
pages={344–360},
year={2022},
organization={Springer}
}
本论文解决什么问题
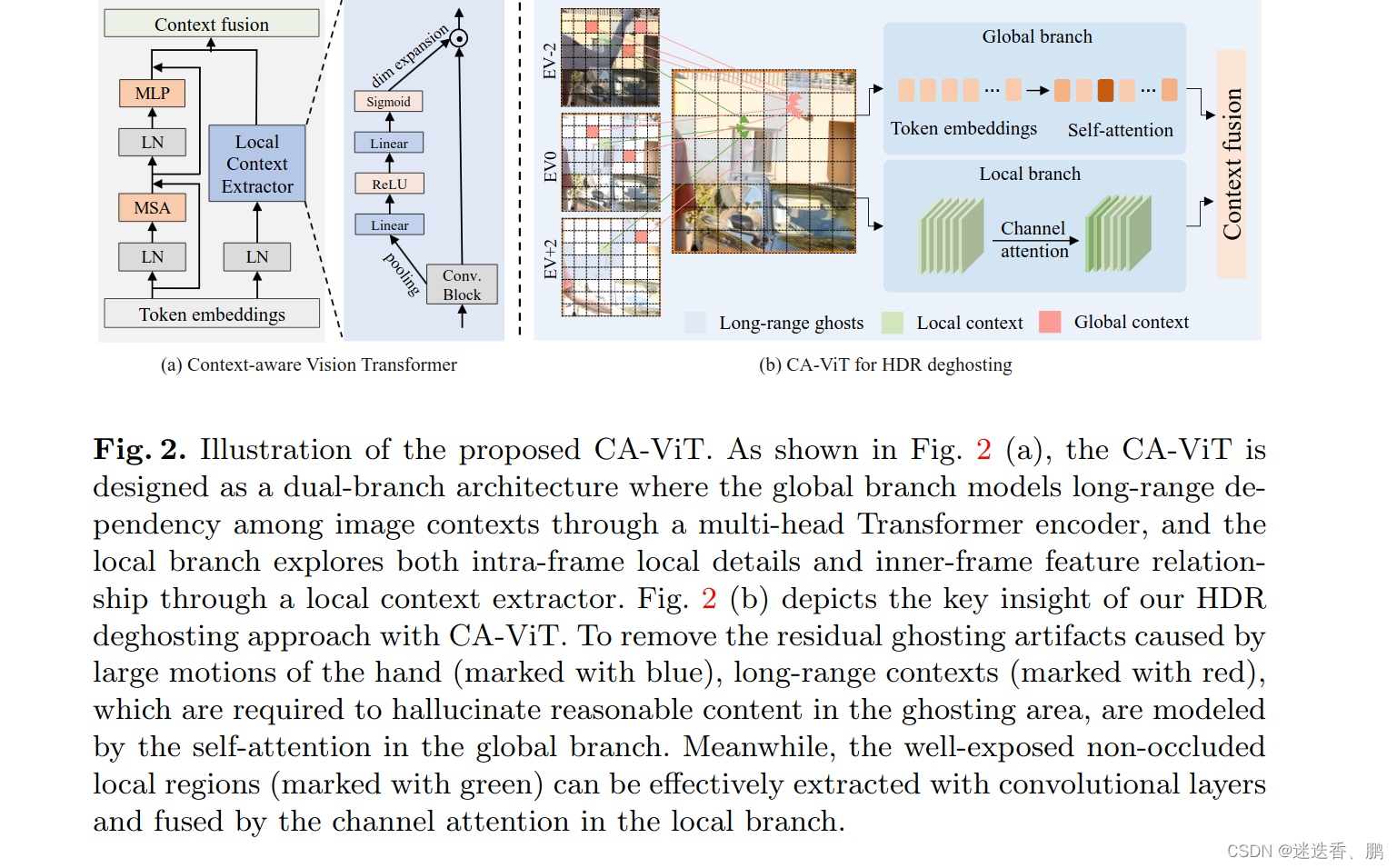
对于模型的长距离建模能力,一个很好地策略就是利用transformer结构,例如ViT算法。然而,本文作者发现transformer结构并不能直接应用于HDR任务中,主要有两个原因:①transformer缺乏CNN中归纳偏差的能力(inductive biases),因此在数据量不足的情况下训练时泛化能力较差,模型性能不高;②帧内和帧间相邻像素之间的关系也对恢复图像的局部细节至关重要,而纯transformer结构难以提取局部上下文之前的关系。对此,本文作者提出了一种上下文感知的ViT(Context-Aware Vision Transformer, CA-ViT),通过双分支架构来同时捕获全局和局部的依赖关系,也就是同时实现全局和局部的建模。
已有方法的优缺点
实际拍摄到的图像容易受到相机、物体运动的干扰,三张低动态范围图像往往不能很好地得到对齐,直接对三图像做融合的话,所生成的图像容易产生伪影、重影,为了解决这一现象,传统的算法通常分为两类:在图像融合前对齐(align)图像或者拒绝(reject)不对齐的像素来去除重影,但精确地对齐图像或者精确地定位不对齐的像素往往难以实现,所生成的HDR图像效果并不好,因此现在常常以数据驱动的方法来训练CNN,利用CNN来实现图像的融合。
对于模型的长距离建模能力,一个很好地策略就是利用transformer结构,例如ViT算法。然而,本文作者发现transformer结构并不能直接应用于HDR任务中,主要有两个原因:①transformer缺乏CNN中归纳偏差的能力(inductive biases),因此在数据量不足的情况下训练时泛化能力较差,模型性能不高;②帧内和帧间相邻像素之间的关系也对恢复图像的局部细节至关重要,而纯transformer结构难以提取局部上下文之前的关系。
本文采用什么方法及其优缺点
本文作者提出了一种上下文感知的ViT(Context-Aware Vision Transformer, CA-ViT),通过双分支架构来同时捕获全局和局部的依赖关系,也就是同时实现全局和局部的建模。对于全局分支,作者使用基于窗口的多头transformer编码器来捕远程上下文关系(即Swin transformer);对于局部分支,作者设计了局部上下文提取器(local context extractor, LCE),通过卷积块来提取局部特征映射,并且通过通道注意力机制在多个帧特征之间选择有用的特征,抑制无用的特征,因此,CA-ViT结构可以使全局和局部以互补的方式发挥作用。基于CA-ViT结构,作者提出了用于HDR成像的transformer结构(HDR-Transformer)。
对于HDR-Transformer,主要包括两个模块:特征提取网络和HDR恢复网络,特征提取网络利用卷积运算和空间注意力模块来提取浅层特征,并且进行粗融合,有助于稳定transformer的训练和抑制图像中不对齐的像素。HDR重建模块以CA-ViT为基本组件,从全局和局部两个角度对图像建模,有助于重建高质量的HDR图像,同时无需堆叠非常深的卷积块。
CA-ViT
与现有的视觉转换器采用纯转换器编码器不同,我们提出了一种双分支上下文感知视觉转换器(CA-VIT),它可以同时挖掘全局和局部图像信息。 CA-VIT由全局变压器编码器分支和局部上下文提取分支构成。
Local Feature Extractor && Global Transformer Encoder
对于全局分支,我们采用基于窗口的多头变压器编码器[6]来捕获远程信息。 变压器编码器由多头自关注(MSA)模块和带残差连接的多层感知器(MLP)组成。公式如下

对于局部特征提取我们设计了一个局部特征提取的提取器,公式如下
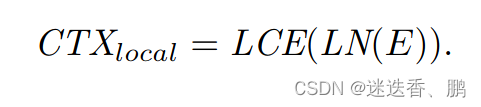
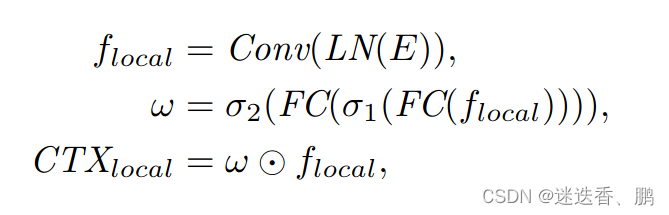
最后,采用上下文融合层将全局上下文和局部上下文结合起来。 虽然可以使用其他变换函数(如线性层或卷积层)来实现上下文融合层,但在本文中,我们简单地通过元素添加来合并上下文,以减少附加参数的影响。
HDR Deghosting
HDR成像的任务是通过深度神经网络重建无鬼影的HDR图像。在之前的大部分作品中,我们以3张LDR图像作为输入,并以中间的帧作为参考图像。为了更好地利用输入数据,首先将LDR图像通过gamma校正映射到HDR域,生成gamma校正后的图像
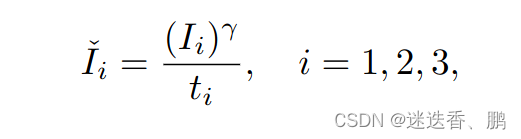
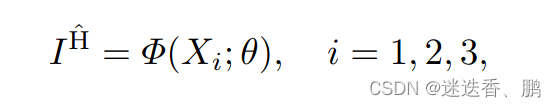
Overall Architecture of HDR-Transformer
我们提出的HDR-Transformer的总体结构主要由两部分组成,即特征提取网络和HDR重构网络。 给定三幅输入图像,首先通过空间注意力模块提取空间特征。 然后将提取的粗特征嵌入到基于变压器的HDR重建网络中,生成重建后的无重影HDR图像。

Loss Function
由于HDR图像通常是在色调映射后查看的,因此在这里使用μ-law函数计算色调映射域中的损失。

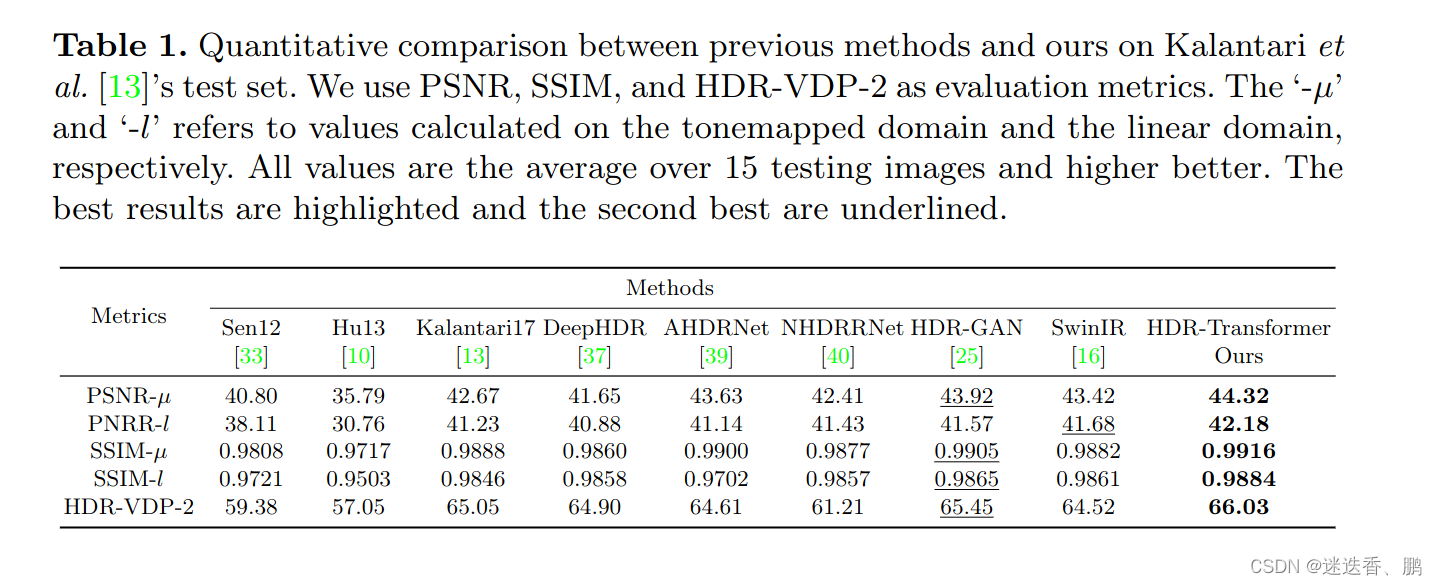
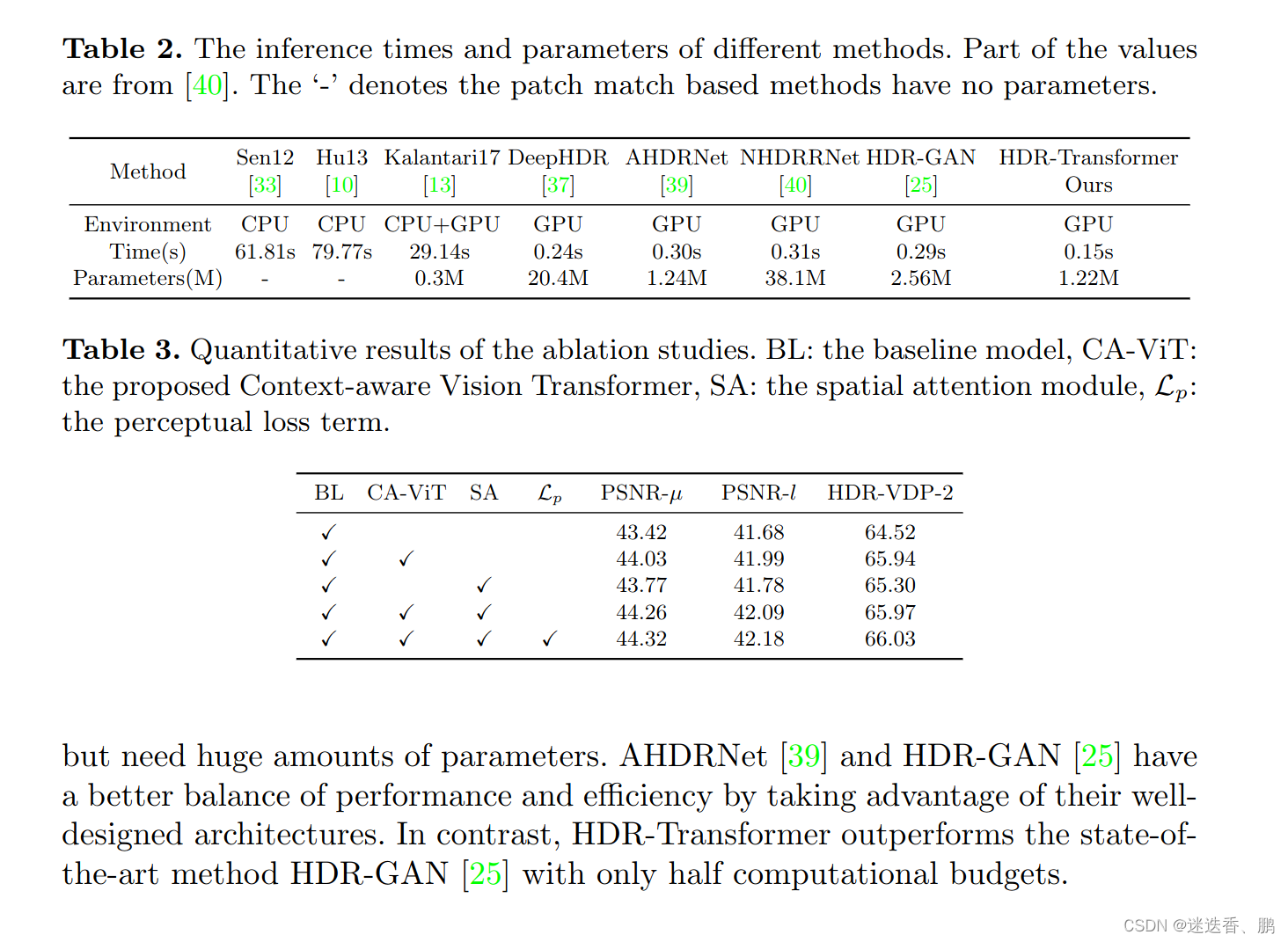
使用的数据集和性能度量
数据集:Kalantari
















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









