








介绍:
Bag-of-words model (BoW model) 最早出现在自然语言处理(Natural Language Processing)和信息检索(Information Retrieval)领域.。该模型忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的。BoW使用一组无序的单词(words)来表达一段文字或一个文档.。近年来,BoW模型被广泛应用于计算机视觉中。
步骤:
1.特征提取;
2.构建字典(所有单词的集合);
![]()
3.确定一帧中有哪些单词,形成词袋向量 (1表示具有该单词,0表示没有);
![]()
4.对比两帧词袋向量的差异,判断回环是否发生.
注:
1.特征提取有常见的提取方法,此处不做过多赘述;
2.构建字典的过程实质上是对目标进行聚类,常见的方法有K-means等;
3.对聚类得到的所有单词,按某种特征进行层层迭代聚类,直到聚类数量到达一定阈值内,得到字典树如下图;
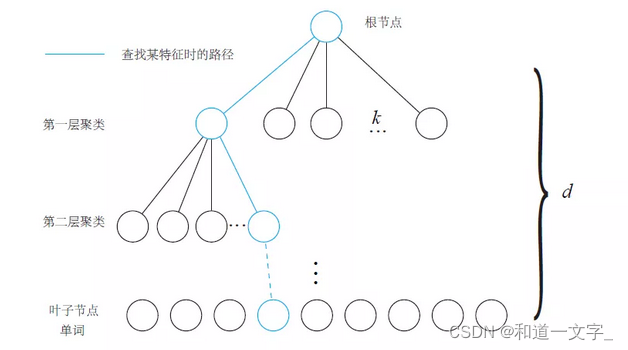
4.词袋向量则为由根节点查找到叶子节点(即单词)的路径,用向量描述;
5.每一帧中,单词出现频率高则区分度高;单词在字典树中出现次数少也代表区分度高;相乘算出每个单词对应的权重;
![]()
6.通过范式计算两帧之间的差异;
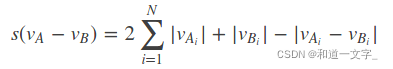
7.此外,关键帧的选取应该相隔较大或特征区别较大;否则应该对其词袋向量表示进行差异化处理.
验证回环:
1.当前帧与连续几个历史帧都发成闭环,可说明闭环发生的概率大;
2.检测到回环之后,接下来的一些帧将不再检测回环,避免计算资源的浪费;
3.将当前帧的特征放入历史特征或地图中,验证一致性差异.
参考:
https://mp.weixin.qq.com/s/I1QGaLK_JLVhA9mMaJFIoA


















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











