






——什么是神经网络
ReLU——rectified linear unit 修正线性单元
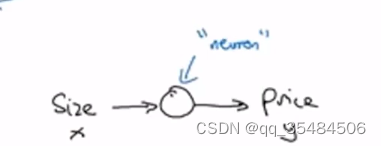
神经网络就是由这些单独完成将输入转化为输出的神经元组成的,下图是由不同的房价自变量预测房价的图示,神经网络的神奇之处在于只需要输入一个X(特征)就能让程序自发的完成中间步骤从而导出price
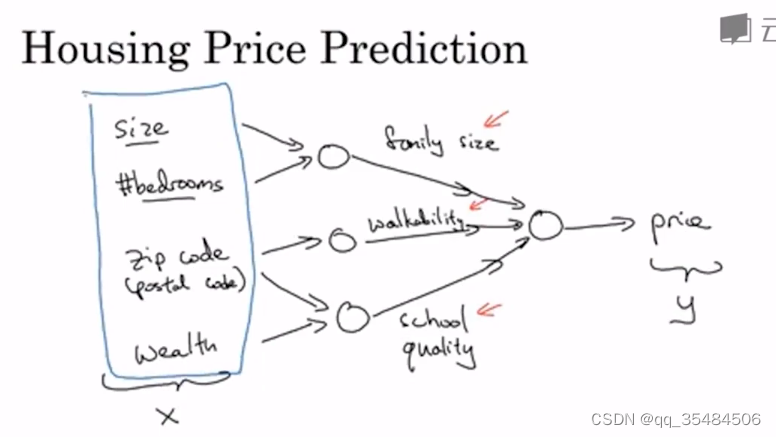
每个内部的节点叫做隐藏节点,输入特征的层叫输入层
监督学习(supervised learning):使用标记
数据集来训练算法,以便对数据进行分类或准确预测结果。
CNN:卷积神经网络 通常用于图像领域,自动驾驶领域
RNN:循环神经网络 通常用语序列数据的处理 比如音频,语言
同时监督学习也可用于结构化数据(有固定格式的数据,比如表格)和非结构化数据(图片,音频,文字)处理
——为什么深度学习会兴起
- DATA:数据量巨大,数据收集能力飞速发展,规模一直在推动深度学习的进步(Scale has been driving deep learning progress),不仅指神经网络的规模,也指数据的规模。 * m表示训练规模,只有在训练规模非常大时,深度学习的能力才比其他方法领先
- Computation:CPU,GPU的发展有助于加快迭代速度,使得研究人员的模型迭代速度更快,从而使他们产生更多想法。
- Algorithms:算法方面的创新都是为了让神经网络运行更快。
——二分分类(binary classification)
目标:
训练出一个训练器,它以图片的特征向量x输入,预测输出的结果为y——只能是1或者0,来表示是或者否。
分类算法是有监督的,事先知道样本所属的真是类别,用某种算法挖掘样本类别划分的内在规律,实现对新样本的类别划分。
符号约定:
表示一个单独的样本,x是n维的向量,y表示二分类的结果。如
表示样本2。
小写字母m表示训练样本的个数,m_train表示训练集个数,m_test表示测试集的个数。
定义一个矩阵
表示训练集,其中训练样本
是该训练集的列向量。矩阵的列数就是样本个数
,矩阵的行数记为
。Python中输出该矩阵的维度的命令是X.shape = (nx, m)。这就是如何将输入用矩阵表示。
定义一个矩阵
,将输出
作为矩阵的列向量按行优先排列,列数代表样本个数
。Python中输出该矩阵的维度的命令是Y.shape = (1, m)。

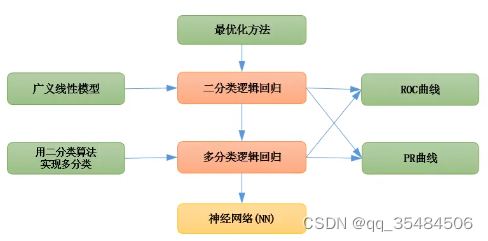
Logistic Regression 逻辑回归
用在监督学习,输出y标签是0或者1这类二分问题中,是一种广义的线性回归分析模型。
sigmoid函数(逻辑分布的概率函数)
sigmoid函数的来源:
将0-1分布中x的概率函数化为指数族分布型再进行同构
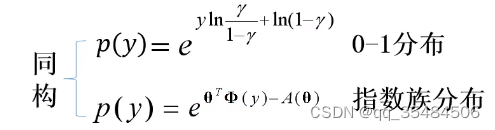
得到以下等式:
然后解出,其中
,即是0-1分布中y输出为1的数学期望,这也就是二分分类的结果,非正即负,也即sigmoid函数。
然后取反函数可以得出, 此为对数几率函数
sigmoid函数的性质:
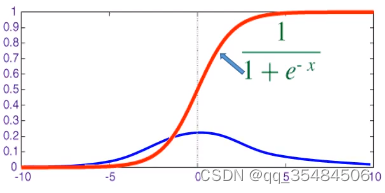
- 当x趋向于正无穷,y趋向于1,反之趋向于0
- sigmoid(x)+sigmoid(-x)=1
- 函数图像关于点(0,1/2)中心对称
- Sigmoid函数的导数为:
sigmoid函数在逻辑回归中的作用
因为普通的线性回归会导致概率P大于1或者小于0,因此需要找到一个上界为1下界为0的函数来表示概率。所以有
其中W为样本权重,因此,以此类推可以求得
——即样本为正的概率的列向量集合
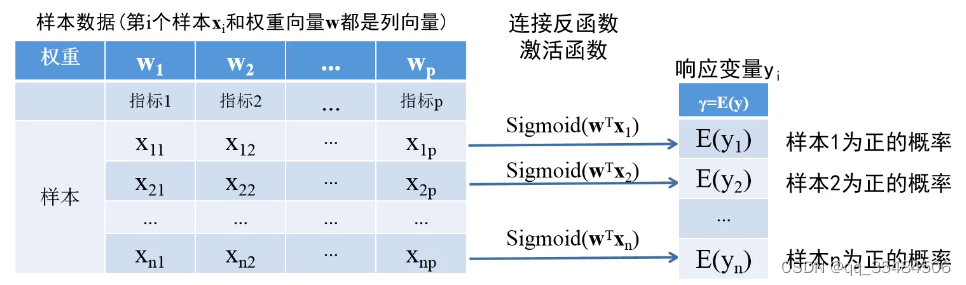
在中需要在自变量中加入未知参数偏置量b,使得概率
.
因此在这个样本数据集中未知参数有N+1个:,这些未知参数是共享的。
总体的流程图就是:
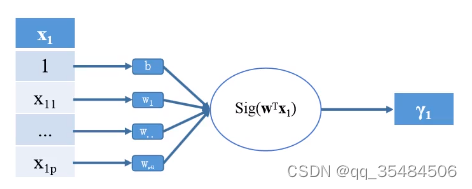
和我们的神经元是类似的,其中Sigmoid函数被称为激活函数。
















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











