







Fine-Grained Features
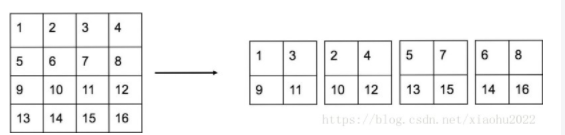
YOLOv2的输入图片大小为416×416416×416,经过5次maxpooling之后得到13×1313×13大小的特征图,并以此特征图采用卷积做预测。13×1313×13大小的特征图对检测大物体是足够了,但是对于小物体还需要更精细的特征图(Fine-Grained Features)。因此SSD使用了多尺度的特征图来分别检测不同大小的物体,前面更精细的特征图可以用来预测小物体。YOLOv2提出了一种passthrough层来利用更精细的特征图。YOLOv2所利用的Fine-Grained Features是26×2626×26大小的特征图(最后一个maxpooling层的输入),对于Darknet-19模型来说就是大小为26×26×51226×26×512的特征图。passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个2×22×2的局部区域,然后将其转化为channel维度,对于26×26×51226×26×512的特征图,经passthrough层处理之后就变成了13×13×204813×13×2048的新特征图(特征图大小降低4倍,而channles增加4倍,图6为一个实例),这样就可以与后面的13×13×102413×13×1024特征图连接在一起形成13×13×307213×13×3072大小的特征图,
v2

v3
loss
YOLOv3重要改变之一:No more softmaxing the classes。
YOLO v3现在对图像中检测到的对象执行多标签分类。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。
如果模板框不是最佳的即使它超过我们设定的阈值,我们还是不会对它进行predict。
不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模。
首先,yolov3要先build target,因为我们知道正样本是label与anchor box iou大于0.5的组成,所以我们根据label找到对应的anchor box。如何找?label中存放着[image,class,x(归一化),y,w(归一化),h],我们可以用这些坐标在对应13×13 Or 26×26 or 52×52的map中分别于9个anchor算出iou,找到符合要求的,把索引与位置记录好。用记录好的索引位置找到predict的anchor box。
xywh是由均方差来计算loss的,其中预测的xy进行sigmoid来与lable xy求差,label xy是grid cell中心点坐标,其值在0-1之间,所以predict出的xy要sigmoid。
分类用的多类别交叉熵,置信度用的二分类交叉熵。只有正样本才参与class,xywh的loss计算,负样本只参与置信度loss。
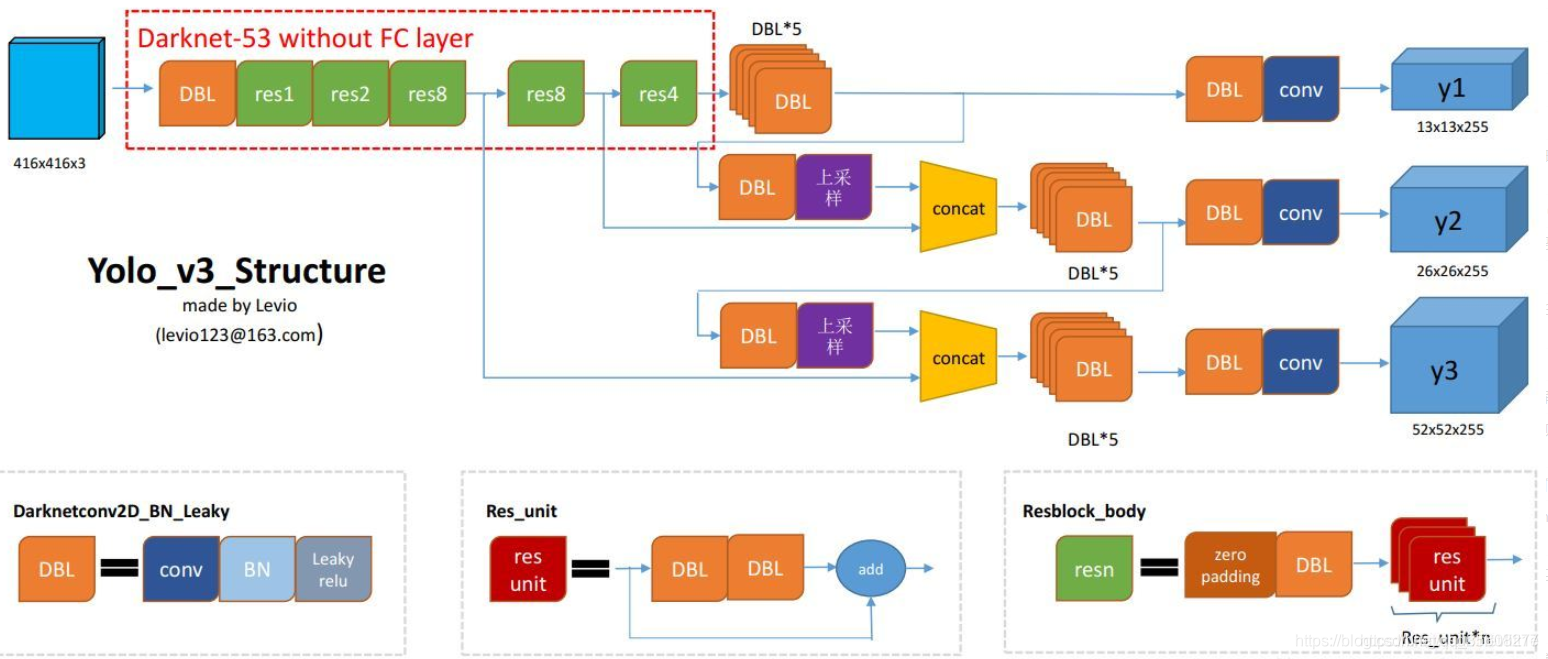
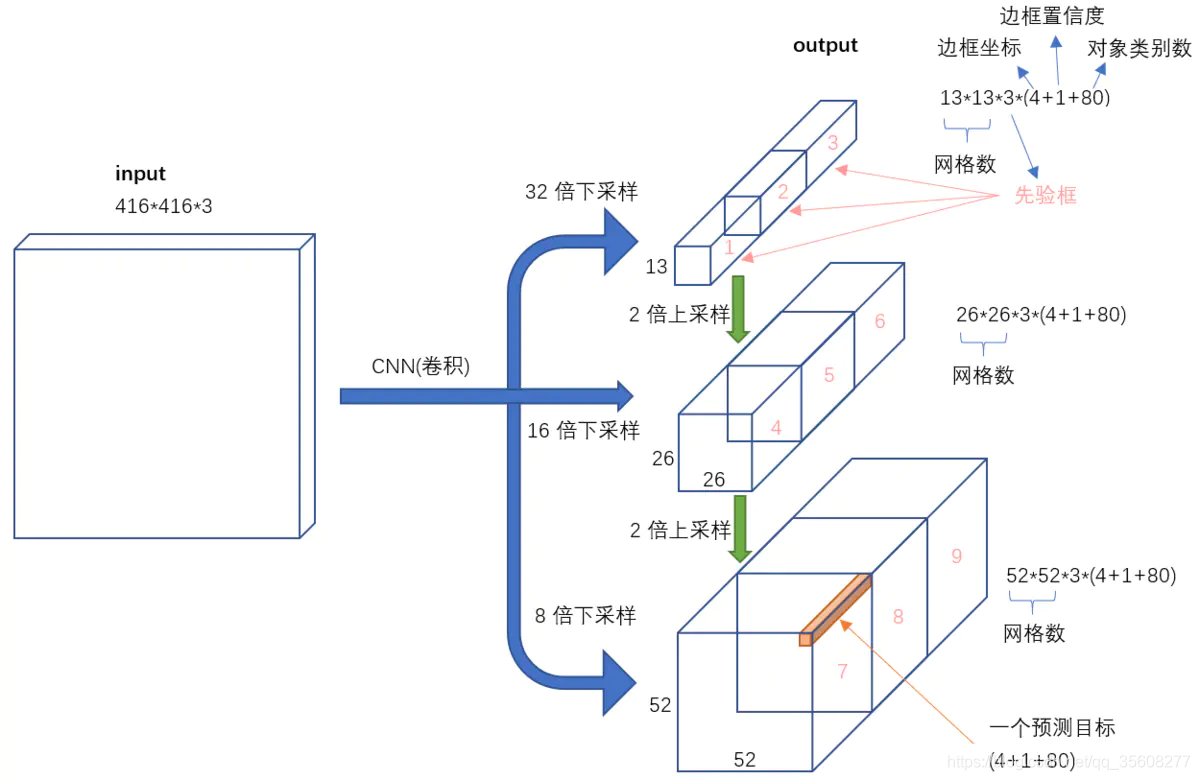
yolov3
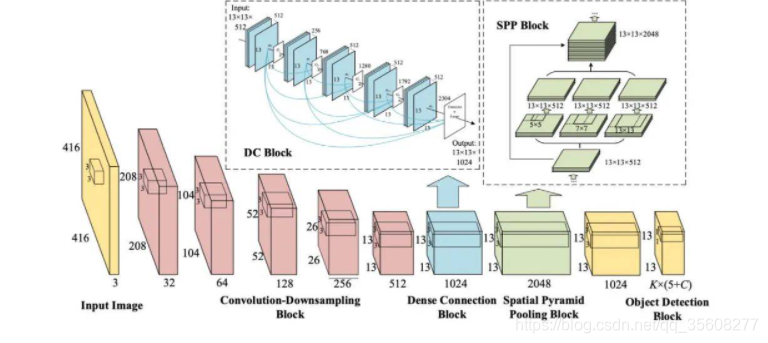
spp
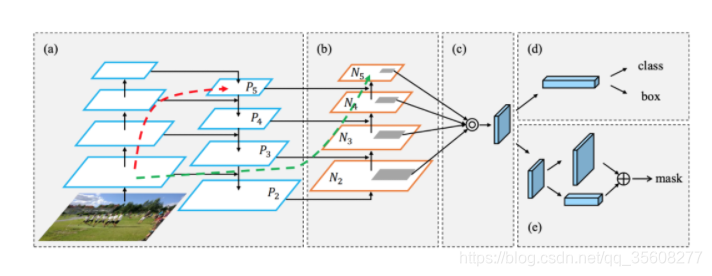
panet
翻译
https://blog.csdn.net/qq_38316300/article/details/105759305
https://zhuanlan.zhihu.com/p/136172670
https://www.jiqizhixin.com/articles/2020-06-06-5
ref
https://blog.csdn.net/xiaohu2022/article/details/80666655?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-1&spm=1001.2101.3001.4242
https://blog.csdn.net/litt1e/article/details/88907542
https://www.jianshu.com/p/d13ae1055302

















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









