







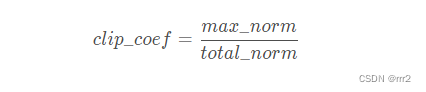
梯度越大,total_norm值越大,进而导致clip_coef的值越小,最终也会导致对梯度的裁剪越厉害,很合理
norm_type不管取多少,对于total_norm的影响不是太大(1和2的差距稍微大一点),所以可以直接取默认值2
norm_type越大,total_norm越小(实验观察到的结论,数学不好,不会证明,所以本条不一定对)
...
loss = crit(...)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=10, norm_type=2)
optimizer.step()
...
clip_coef越小,则对梯度的裁剪越厉害,即,使梯度的值缩小的越多
max_norm越小,clip_coef越小,所以,max_norm越大,对于梯度爆炸的解决越柔和,max_norm越小,对梯度爆炸的解决越狠.max_norm可以取小数
ref
https://blog.csdn.net/Mikeyboi/article/details/119522689















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









