







transformer 中 self-attention 计算如公式:

Q,K 的序列长度均为图像尺寸,公式 2 计算复杂度为图像尺寸的平方,这样带来较大计算负担。作者认为,对所有特征之间的关联在机器翻译中是必要的,但是在视觉任务中是不必要的。因为机器翻译中每个特征都代表一个特定的单词或标记,而视觉任务中相邻的空间通常表示相同的物体。因此在视觉任务中,可以减少特征向量的数量,构建一个更粗略更具描述性的视觉表达,从而显著降低计算复杂度。
作者首先提出了两个假设:
一个小的 exemplar value 集合可以在一个数据集之间共享;
一个粗略的查询具有足够的描述性来利用这些 exemplar value。



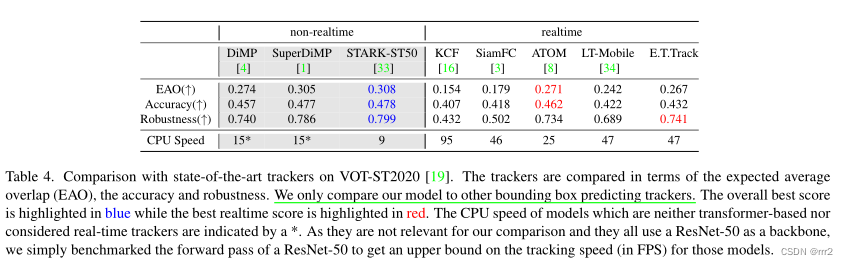
上述提出的 Exemplar Transformer layer 可以作为卷积的替代,作者将 LightTrack 的预测头分支所有卷积换成了 Exemplar Transformer,构建新的跟踪器 E.T.Track 如图 4 所示。
















 2166
2166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









