







摘要:
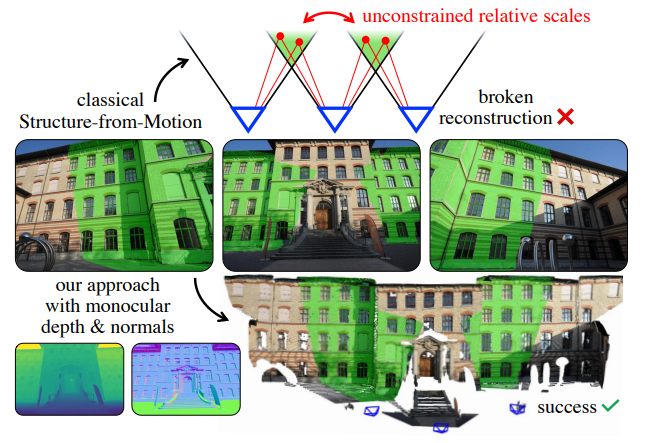
尽管结构光束法(SfM)近年来取得了显著进展,但在极端视角变化、低重叠、低视差或高度对称的场景下,现有最先进的系统仍容易失败。由于避免这些问题的图像采集具有挑战性,因此这些限制严重阻碍了SfM的广泛应用,特别是对非专业用户。
本文提出通过引入由深度神经网络预测的单目深度与法向先验信息来扩展传统的SfM方法,从而克服上述问题。通过将单目和多视角的约束紧密结合,本研究方法在面对极端视角变化时显著优于现有方法,同时在常规条件下仍保持强大的性能。本研究还展示了单目先验能够有效避免由于场景对称性导致的错误匹配,这是SfM中一个长期存在的问题。本系统首次实现了从少量图像中可靠地重建复杂室内环境。通过合理的先验不确定性传播方法,我们的系统对先验误差具有鲁棒性,能兼容不同模型生成的先验信息,且几乎无需调整,因此能够轻松适应未来单目深度与法向估计技术的发展。代码已公开发布:github.com/cvg/mpsfm。
引言(Introduction)
结构光束法(Structure-from-Motion, SfM)是计算机视觉领域的一个核心问题,涉及从一组二维图像中估计三维结构和相机运动。该领域已经取得了巨大进展,催生了许多先进的SfM系统,如Bundler、VisualSfM、COLMAP 和 GLOMAP,这些系统在定位与建图、多视图立体重建以及新视角合成等任务中广泛应用。
尽管如此,SfM仍存在多个挑战和失败情形,尤其是在面对极端视角或光照变化、重复结构、大规模场景、以及隐私保护等方面。其中最常见的失败情形是极端视角变化,例如低重叠或低视差的图像对,这类情况会影响SfM重建过程中的多个阶段。虽然近年来在图像匹配方面,机器学习取得了巨大突破,能够应对极端视角或对称问题,但在后续重建阶段仍存在根本性限制,常常导致不稳定甚至失败的重建结果。
目前主流的SfM系统普遍依赖于三视图重叠(即至少三张图像共同观察到一个三维点),以保证三维结构的一致性。然而,在实际拍摄过程中,确保足够的视角重叠本身就是一项挑战。这对非专业用户而言尤其困难,即便是专家也需要提前精心规划或多次尝试才能捕捉到理想的图像集合。拍摄冗余图像虽可提高重建的可能性,但却带来了处理时间、存储和计算成本的大幅增加。
本文提出了一种基于单目深度估计的方案,用以解决这些剩余的关键难题。我们将单目深度与法向信息引入传统的增量式SfM流程中,从而不再依赖三视图轨迹,仅通过两视图即可实现准确的三维重建。这使得系统在低重叠场景中依然具有强大性能,同时在高重叠场景下表现依然稳定。我们还引入了密集深度一致性检测方法,可用于识别对称性导致的错误配准。通过融合单视图和多视图优化,并结合不确定性传播,我们的系统可以有效处理由单目深度估计带来的误差,并与多视图结构共同优化。此外,未来深度学习方法在深度与法向估计方面的进步将直接增强本系统性能,而无需额外调整。
相关工作
传统的SfM:
早期的SfM研究主要靠定序视频序列来进行三维重建,后续研究转向处理无序的图像集合。经典的系统通常分为增量式和全局式第二类经典编程,其中COLMAP是最常用的增量式SfM引擎。
然而,这些系统有一个共同的根本限制:需要至少三张图片的重叠观点才能构成线程路径,以保证三维结构的稳定性。有工作已经评估过这个问题,并尝试利用混合2D-3D或2D-2D对应关系进行相机姿态估计。也有研究者尝试仅通过图像轨径边缘进行两视图SfM,但还是依赖三视图重叠以确定观测比例。
与之相比,我们的方法不需要三视图路径或重叠,且通过强大的单相光光源先驱动,避免了传统方法常见的观点表达失效问题。
SfM中的深度学习:
在机器学习大量成功应用后,一系列工作尝试将数据驱动的方法融入SfM模块,其中大部分联系在特征表示和匹配阶段,如SuperPoint、LightGlue等。也有少量工作要展示在指数编辑、材料调整和相机标定等方面的进步。
最近一些新系统如DuSt3R、MASt3R等在两视图匹配和重建上达到了优秀性能,MASt3R-SfM就是基于这样的匹配和点云描述,用类似于传统全局SfM的模型进行重建。第一类型经进入后,还有数据驱动系统尝试经过端到端训练条件进行共同最优化。然而,这些经迟系统在普遍或大规模场景中仍难以替代传统SfM。
相比之下,我们在传统增量式SfM中融入了单相光光源先驱动以解决这些失效问题,同时保持了系统的通用性和可扩展性。
好的,以下是第3章“方法(Method)”部分的翻译:
3. 方法(Method)
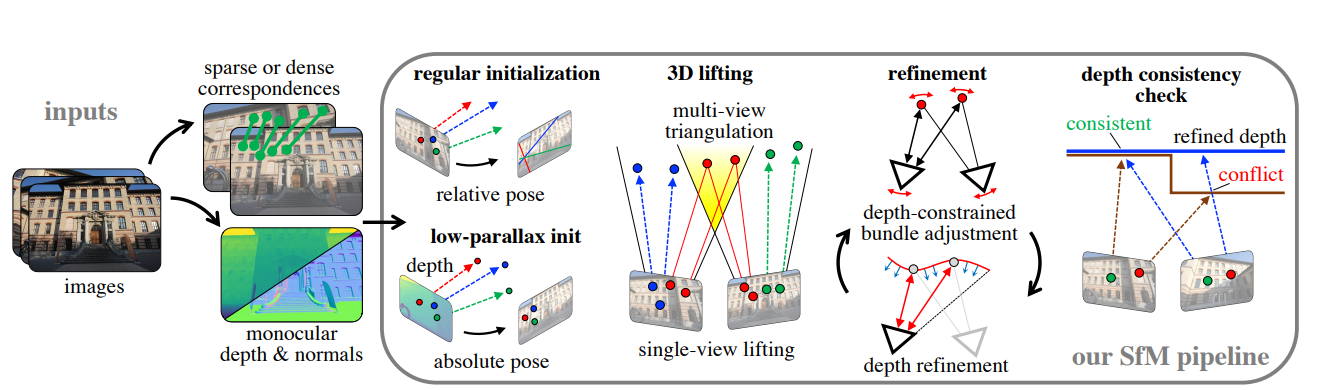
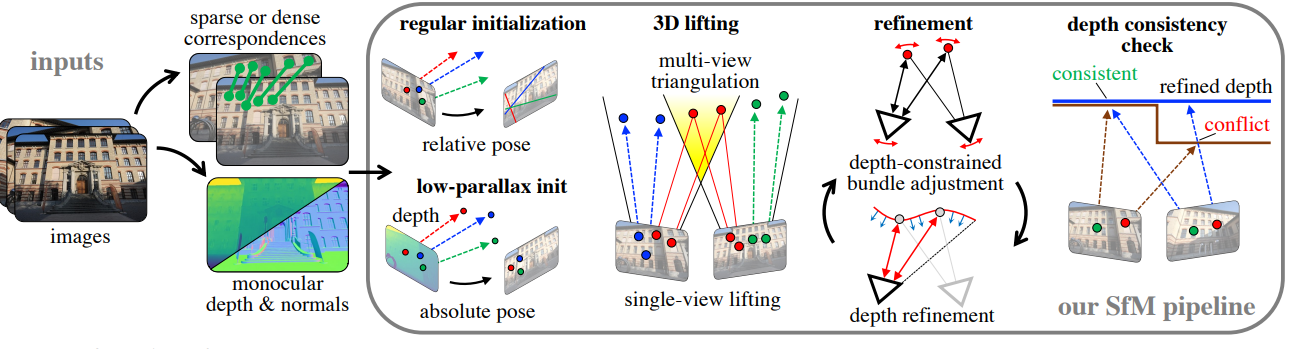
首先对问题进行公式化,并概述我们的系统流程——如下图所示。
输入(Inputs):
系统接收以下输入:
-
一组无序图像
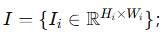
-
每张图像的内参
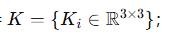
-
对每张图像,我们估计其单目深度图
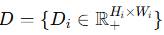 和法向图
和法向图 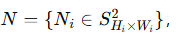 ,以及它们各自的不确定性图
,以及它们各自的不确定性图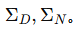

输出(Outputs):

系统概述(System Overview):

3.1 两视图初始化(Two-View Initialization)
初始姿态估计:
借鉴COLMAP,我们首先根据内点数量排序图像对,选取能估计稳定相对姿态的图像对。如果没有满足条件的图像对,我们就使用单目深度作为先验,从图像 Ia 中提取三维点,再与 Ib 中的二维点进行PnP姿态估计,初始化两视图的姿态。
初始三维点云构建:
我们通过提升低视差的内点并对其余点三角化来构建初始点云,然后用以下公式对每张图像的深度图进行尺度对齐:

最后,我们将未与任何三维点关联的图像点通过深度提升添加到点云中。
3.2 下一视图注册(Next View Registration)
视图选择(View Selection):
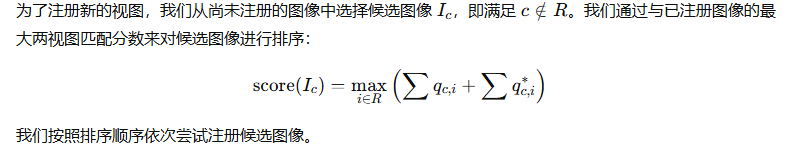
注册(Registration):

随后进行一次局部优化(见第3.3节)和深度一致性检查(见第3.4节)。
3.3 局部与全局优化(Local and Global Refinement)
在完成两视图初始化和新视图注册之后,联合优化相机姿态与三维结构。
借鉴 COLMAP 的调度机制,在已注册图像与三维点之间交替执行局部或全局的 bundle adjustment(捆绑调整)。这种方式可使增量式 SfM 达到摊销后的线性运行时间。
优化问题定义(Optimization Problem):


高效求解策略(Efficient Solving):
整体目标函数的 Hessian 矩阵具有复杂的稀疏结构(见附录),不适合使用 Schur 补技巧。为保留优化的可行性,我们采用交替块坐标下降策略:

3.4 深度一致性检查(Depth Consistency Check)
仅依赖稀疏图像观测进行重建过滤(如 COLMAP 所采用的)虽然重要,但在检测遮挡冲突和自由空间冲突方面存在局限。传统的稀疏 SfM 在图像因对称结构、姿态估计失败或其他错误注册而导致的崩溃性错误中表现不佳。



3.5 实现细节(Implementation Details)
匹配搜索(Correspondence Search):
我们主要依赖 COLMAP 的匹配流程,但使用了更强的特征和匹配器:
-
特征提取采用 SuperPoint;
-
匹配器使用 LightGlue。
由于我们的方法不依赖三视图轨迹(multi-view tracks),因此能够有效处理稠密匹配。此外,我们也在实验中测试了 RoMa 等稠密匹配方法。
在使用 MASt3R 进行图像匹配时,我们使用其提供的深度估计与 DSINE 估计的法向信息。我们还在第 4.3 节中测试了其他深度模型(例如 Depth Anything v2、DepthPro)。
单目深度先验(Monocular Depth Priors):
我们最通用的配置使用 Metric3D-v2 预测的深度和法向先验,并附带每像素的不确定性估计。
-
使用 MASt3R 匹配器时,我们则使用其自身的深度预测结果,并配合 DSINE 提供的法向图;
-
我们还在第 4.3 节中评估了其他模型的效果。
优化细节(Refinement Optimization):

4. 实验(Experiments)
我们从两个方面评估系统性能:
-
低重叠(low-overlap)场景;
-
低视差(low-parallax)场景。
4.1 低重叠重建(Low-overlap Reconstruction)
设置(Setup):
我们选用了多个 SfM 数据集中的图像集合【如 ETH3D [53]、SMERF [15]、Tanks & Temples [33]】。
对于每个场景,我们采样不同重叠度的图像组。
视角重叠的定义如下:
-
如果有 GT 深度图,则根据可见像素比计算;
-
否则,使用原始 SfM 模型中可见三维点的数量计算。
我们假设相机内参已知。
相机姿态评估标准遵循【文献[29]】,通过与 GT 相比计算旋转和平移的最大角度误差,并报告 1°/5°/20° 内的 AUC(Area Under the recall Curve)。
对比方法(Compared Approaches):
基于稀疏匹配的方法:
-
COLMAP + SIFT;
-
COLMAP + SuperPoint + LightGlue(SP+LG);
-
SLR(Structure-less Resectioning)【73】;
-
GLOMAP【43】(全局SfM)。
基于稠密匹配的方法:
-
RoMa【19】与 COLMAP;
-
DF-SfM【24】:使用 LoFTR 匹配后在 COLMAP 上优化;
-
VGG-SfM【64】:对图像子集同时估计对应关系;
-
MASt3R-SfM【16】:基于两视图稠密点云构建。
我们的方法对这些匹配输入均可适配。
三图像组实验(Triplet Evaluation):
我们从 ETH3D 中采样多个室内外场景,构建多个三图像组合,重叠度从 0 到 50%。如图1所示。
实验结果显示:
-
COLMAP 在低重叠(特别是无三视图轨迹)下重建失败;
-
SP+LG 和 SLR 提高了一些鲁棒性,但仍然不足;
-
我们的方法在各重叠度下均表现更稳健,AUC@20° 和 AUC@1° 均领先。
场景级完整重建(Full-scene SfM):
我们从以下数据集中构建多图像场景:
-
ETH3D;
-
SMERF;
-
Tanks & Temples。
我们采样 5 个不同重叠级别的图像子集,并以 COLMAP 在完整图像集上重建得到的相机位姿作为 GT。
实验结果显示:
-
在低重叠场景中,我们显著优于所有现有方法;
-
随着重叠度增加,我们在鲁棒性上仍保持领先;
-
稠密特征(如 RoMa、MASt3R)匹配比 SP+LG 更有效;
-
MASt3R 能更好地处理极端视角,带来整体最佳匹配输入;
-
在 T&T 的部分以物体为中心的场景中,我们在 AUC@1° 上略逊 MASt3R-SfM,主要由于其前景点稀少。
图 3 展示了各方法在低重叠场景下的可视化比较。

4.2 低视差重建(Low-parallax Reconstruction)
由于增量式 SfM 在图像注册阶段依赖粗糙的三维结构,因此在低视差(即相机移动方向与视线方向接近)的场景下容易失败。
设置(Setup):
我们采用 RealEstate10K 数据集【74】,其中包含大量室内和室外视频序列,这些序列具有以下挑战特征:
-
纹理稀少;
-
相机前向平移;
-
原地旋转等低视差运动模式。
我们对比以下方法:
-
COLMAP 和 GLOMAP(分别采用 SuperPoint 和 LightGlue 特征);
-
MASt3R-SfM【16】;
-
StudioSfM【37】:专为低视差场景设计,利用单目深度进行初始化和正则化,但不进行深度 refinement 或不确定性处理。
我们还调整了 COLMAP 的最小三角化角度参数,使其更适用于低视差设置(包括默认值与调优值两个版本)。
实验结果(Results):
如表 3 所示,我们将方法分为两类:
-
全局 SfM 方法:如 GLOMAP 和 MASt3R-SfM,在结构不依赖多视角三角化的前提下,天然更适应低视差场景;
-
增量式 SfM 方法:如 COLMAP 与我们的方法。
我们的方法(MP-SfM)在增量式范式下仍能有效处理低视差问题,甚至超过了 MASt3R-SfM 的精度。这主要归功于我们在整个流程中引入了单目先验,并对其不确定性进行建模和优化。
换句话说,MP-SfM 缩小了增量式与全局 SfM 在低视差条件下的性能差距,同时保持了增量式框架的灵活性与扩展性。



















 2659
2659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











