 多视图三维重建详解:数据关联、SFM流程与挑战
多视图三维重建详解:数据关联、SFM流程与挑战





 本文详细介绍了多视图三维重建的Pipeline,包括数据关联中的特征提取、匹配与验证,以及SFM的稀疏重建过程。重点讨论了增量式、全局式和分组式SFM策略及其优缺点。文中还涵盖了关键技术和挑战分析。
本文详细介绍了多视图三维重建的Pipeline,包括数据关联中的特征提取、匹配与验证,以及SFM的稀疏重建过程。重点讨论了增量式、全局式和分组式SFM策略及其优缺点。文中还涵盖了关键技术和挑战分析。
背景
掌握传统的多视图三维重建基本流程
总体流程
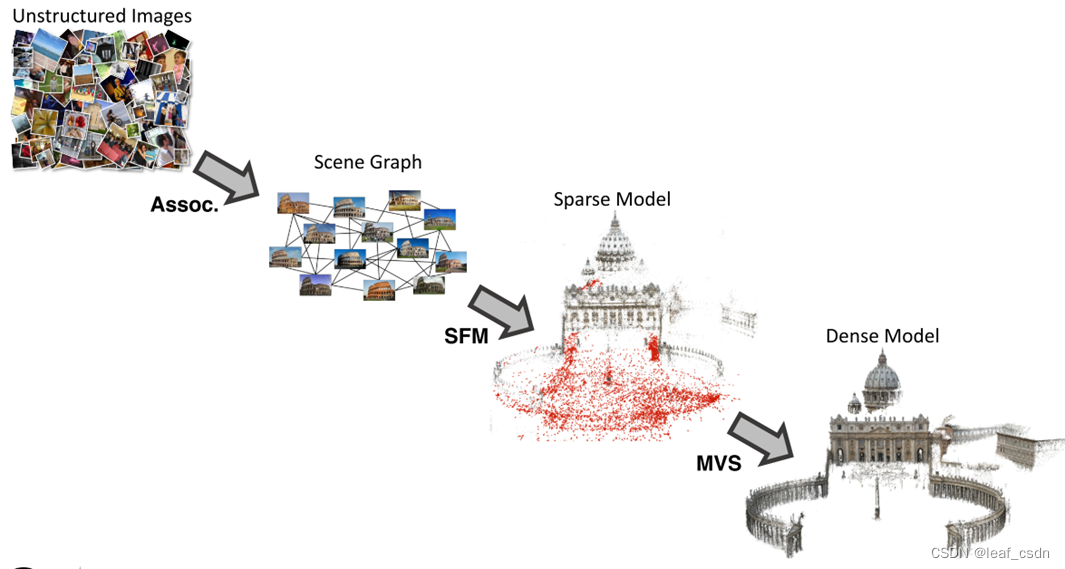
多视图三维重建的Pipieline如下图,总共分为四个步骤:
- 拍摄场景多视角的图像
- 建立这些图像之间的联系(Data Association)
- SFM稀疏重建
- MVS稠密重建
Data Association
建立图像之间的联系主要包含以下4个步骤:1)特征提取;2)特征匹配;3)基于几何的特征对验证;4)特征建树
1)图像的特征提取。
1.1)全局特征描述子
· Color histogram颜色直方图

· GIST feature
首先, 在4个尺度和8个方向上设置Gabor滤波器,并对图像做滤波,得到32个滤波后图像。
其次, 对滤波后图像分成44个区域,计算每个区域内像素均值。
最后, 得到4844=512个区域均值组成的特征向量,即为Gist512特征。
1.2)局部特征描述子
· SIFT & SURF & DSP-SIFT

· BRIEF
一种二进制描述、不具备旋转不变性,不具备尺度不变性

· OBR
ORB特征在速度方面相较于SIFT、SURF已经有明显的提升
同时,保持了特征子具有旋转与尺度不变性
2)特征匹配
特征匹配具有两条路线:
2.1)Matching
① 每个图像分别提取全部的特征
② 图像和图像之间搜索最佳匹配特征(最佳匹配也可能是误匹配)
③ 进一步SSD、SAD、NCC等块匹配方式来验证
2.2)Tracking
① 图像1中提取特征A
② 在图像2中,临近的图像位置处,寻找完全相同的特征A
③ 在图像3中再次寻找完全相同的特征A(在连续视频帧中、或两两拍摄场景的位置相差不多时有效)
3)基于几何的特征对验证
基于对极约束:图像中的一个点p1,在另一个图像中的匹配点p2,必然在极线L2上

由对极几何的约束关系,将特征对中不满足几何约束的误匹配点剔除,如下图中红色线描述的特征对

关于对极约束的描述,若是一般的场景下,匹配点对P1-P2之间满足如下用基础矩阵描述的关系:

当物体是一个接近平面的对象时,可利用平面单应性矩阵H(单应性变换 Homography Estimation)来表达两个视图中点的关系


根据已有的特征点对, 由于是存在误匹配点对的,因此,通常基于RANSAC来选择若干点对P1-P2求解稳定的F或H,然后利用F或H建立的对极约束,剔除不满足几何约束的特征点对。如下表所示,根据场景类型是通用的、平面类的、全景类的,使用合理的模型进行特征对验证。

F矩阵是一个3*3的矩阵,秩为2,且没有尺度信息,因此自由度为7,典型的解法是使用归一化8点法来获取求解最佳近似F矩阵。值得注意的是:系数矩阵的正则化和反正则化,其次,SVD得到的解不是最终解,需要进一步最佳估计满足F矩阵特质的解

基础矩阵F和本质矩阵E之间关系如下

在内参矩阵初始化后是已知的状态,那么根据F可以估计得到E矩阵,再由E矩阵和旋转矩阵R和平移量t满足的如下关系,来分解得到R,t

[
t
x
]
[t_x]
[tx]是平移量的反对称矩阵,对于E进行SVD分解,在四对解中,带入实际的点,判断点和相机坐标系正、反方向的关系,获取正解

对于单应性矩阵H分解得到R,t的过程可以参考之前的博文H分解得到RT
4)特征建树
所有图像的特征描述建立搜索树,以便新的下一帧图像进行特征匹配时,快速的找到对应的特征及所在的图像ID
SFM稀疏重建
SFM(Structure From Motion)
· Structure —— 指场景的几何结构
· Motion —— 指相机从多个角度来获取场景图像的过程
· 输入:多角度同一场景的图像
· 输出:场景内物体的三维坐标、相机的位姿参数
在Data Association中,我们能够获取两两视图之间的R,t相对关系,接下来我们需要获取场景内关键点的三维坐标,以及各个视图的绝对位姿信息。主要有如下三个策略


- 增量式SFM
Incremental Reconstruction的主要步骤包含:Initialization, Image Registration, Triangulation, Bundle Adjustment, Outlier Filtering, Reconstruction.

1)Initialization.
1.1) Choose two non-panoramic views ( 𝑡 ≠ 0). 指从所有的多视角中,挑选两个非全景拍摄的视图作为起始位置。
1.2) Triangulate inlier correspondences. 已知两两视图之间的R,t关系,在初始化内参已知的情况下、特征点对也已经匹配完成,就可以进行两两视图之间的特征点三维重建。

1.3)Bundle adjustment. 上述过程是在初始化内参情况下完成的,为了进一步获取精确的内、外参数和三维点坐标,需要利用已知的特征点二维坐标,对两两视图系统进行优化。
2)Absolute camera registration.
2.1)Find 2D-3D correspondences. 两两视图完成上述初始化工作后,当第三幅视图进入计算时,首先根据特征匹配,找到图像1和图像3,图像2和图像3的特征匹配点对。

2.2)Solve Perspective-n-Point problem. 根据Initialization过程中重建得到的三维点,以及图像3中的匹配点,就能建立3D-2D的对应关系,由此利用PnP来求解图像3的绝对位姿。参考之前的博文,PnP的一些总结

2.3)Triangulate new points. 图像1-图像3,图像2-图像3两两组合,重建新的三维点

3)Bundle Adjustment. 将三个视图的图像、三维点、相机内外参数再次进行系统优化。
4)Outlier filtering. 剔除重投影误差过大的点;剔除重建点三维坐标无穷大的点

增量式SFM就是在每一次新的视图进入计算时,都要重复的匹配、重建和捆绑调整,因此,准确性和鲁棒性比较高
-
全局式SFM
全局SFM是完成所有的两两视图重建后,再统一进行BA捆绑优化,效率高,但稳定性低

-
分组式SFM
分组式SFM根据先验将图像进行分组,每一个组内进行增量式SFM或全局式SFM,然后融合所有组的三维信息

将三种策略的SFM的对比如下

Challenges




















 9796
9796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











