









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种深度元学习的方法用于解决小样本学习问题,作者指出原有的元学习算法都是基于实例空间(instance space)进行学习的,而即使是同类物体,其受到光照,背景,位置等因素的影响,外表差异也非常大,因此许多元学习方法的分类效果与人类的能力相去甚远。本文则提出利用深度神经网络将学习的对象由实例空间转移到概念空间(concept space),其实就是利用一个DNN网络提取目标物体的抽象特征,再利用这一特征训练元学习器,作者称该DNN网络为概念生成器(concept generator)。但是由于小样本学习任务中,样本数量有限,无法使DNN得到充分训练,因此作者又设计了一个概念区分器(concept discriminator),其实就是一个普通的分类器,并利用一个额外的数据集对其进行训练。这里要与GAN中生成器和区分器的概念区别开来,二者之间并不存在对抗训练的关系。整个网络的流程如下图所示。
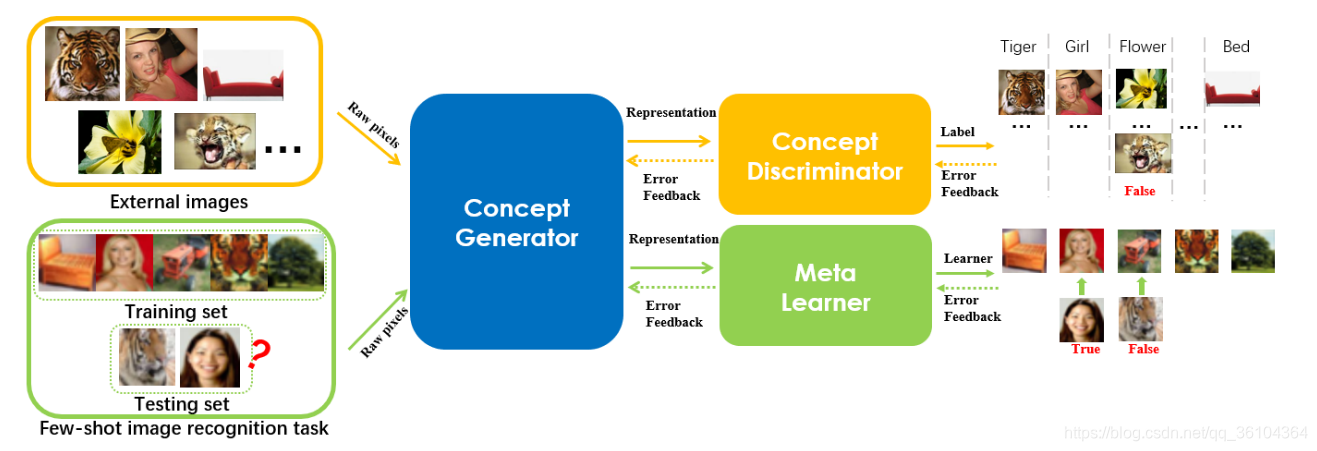
由上图可知,整个网络可以分成三个部分:概念生成器,概念区分器和元学习器。训练数据集也分成小样本数据集和额外数据集两部分。训练过程中小样本数据集中的图像经过概念生成器处理,转化为更加抽象的概念(也就是特征向量),元学习器利用这些概念进行学习。而为了保证概念生成器具有足够的表征能力,又利用额外数据集进行训练,将提取到的概念输入到概念区分器中进行分类预测,并计算损失更新参数。
实现过程
网络结构
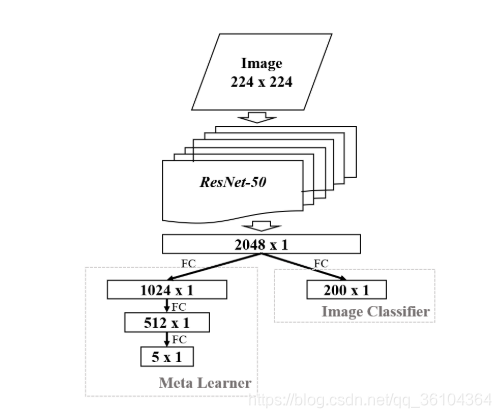
概念生成器可采用任何深度卷积神经网络结构如Inception,VGG,ResNet等,本文采用ResNet-50;概念区分器可采用任何有监督分类器,如支持向量机,最近邻分类器或神经网络,本文采用浅层的带有全连接层的神经网络作为分类器。元学习器可采用经典的元学习算法,如Matching Network,MAML,Meta-SGD等。网络结构示例如下
损失函数
损失函数包括两部分:一部分是用于概念区分器训练的,通常是交叉熵损失函数;另一部分是对元学习器进行训练的,要根据元学习器的需要采用合适的损失函数。
训练策略
本文以Meta-SGD作为元学习器,其训练过程如下图所示

分为两个阶段:内循环和外循环,内循环阶段是对元学习器中的参数
ϕ
i
\phi_i
ϕi进行更新,得到
ϕ
i
′
\phi_i'
ϕi′,然后在测试集上计算损失
L
t
e
s
t
\mathcal{L}_{test}
Ltest;外循环阶段是对元学习器中的参数
ϕ
\phi
ϕ和
α
\alpha
α(学习率),还有概念生成器的参数
θ
G
\theta_{\mathcal{G}}
θG和概念区分器的参数
θ
D
\theta_{\mathcal{D}}
θD进行更新。
算法推广
作者提到如果能够提供相应的额外数据集,本文提出的方法可应用于终生学习(lifelong learning)的场景。
创新点
- 提出深度元学习算法DEML,将元学习算法的学习对象由具体的实例转化为抽象的概念
- 设计了概念生成器和概念区分器结构,利用额外数据集对其进行训练,提高概念生成器的表征能力
算法评价
本文提出的想法其实并不复杂,而且在许多元学习算法中都包含有特征提取网络这一结构,区别在于原有的原学习算法是将特征提取网络的参数内置在 ϕ \phi ϕ里,跟随整个元学习器进行训练,而本文则是将其外置为概念生成器,单独进行训练,且利用一个额外的数据集对其进行辅助训练。就实验结果来看,本文的方法相对于原有的元学习算法,在多个数据集上都取得了明显的提升(准确率提高7%-10%),但由于引入了额外数据集,这种比较是否有失公允呢?而且在实际任务中,很难获得与任务相关的辅助数据集来进行训练,因此本文的方法在实际应用中的效果存疑。结合之前的一篇文章《TADAM: Task dependent adaptive metric for improved few-shot learning》可以看到,采用联合训练的方式似乎要比先预训练再微调训练这一方式要更好。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。


















 3384
3384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











