









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种基于参数优化的小样本学习算法(LEO),与MAML,Meta-SGD算法相比,本文最重要的改进就是引入了一个低维的隐空间(Latent Space)。为了方便理解本文,我们首先回顾一下MAML算法,其目标是通过元训练得到一个好的初始化模型
θ
\theta
θ,使得模型能够通过少量样本的微调训练就能快速的适应任务需求,得到任务
T
i
\mathcal{T}_i
Ti对应的模型参数
θ
i
′
\theta_i'
θi′。为了实现这一目标,MAML算法通过两个层次的训练,内层循环(inner loop)是由一个随机初始化的
θ
\theta
θ开始,为每个任务
T
i
\mathcal{T}_i
Ti都更新得到一个参数
θ
i
′
\theta_i'
θi′,更新过程如下
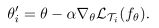
完成一个内层循环后,能够获得若干个任务对应的模型参数
θ
i
′
\theta_i'
θi′,然后再对初始化参数
θ
\theta
θ进行更新(外层循环,outer loop),更新过程如下
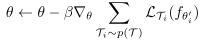
经过多次内外循环迭代后,得到最终模型参数
θ
\theta
θ。值得注意的是,这一系列的更新过程,都是在模型的参数空间
Θ
\Theta
Θ中进行的,这是一个巨大的高维空间,包含了整个模型的所有参数。此外每个任务对应的模型参数
θ
i
′
\theta_i'
θi′都是一个实例化的模型(假设模型是一个卷积神经网络,我们知道这个模型的每个卷积核中的每个权重参数,就是得到了一个实例化模型,并且对于每个任务我们都有相对应的实例化模型)。
了解了MAML后,我们再来看看本文LEO做了那些改进,算法流程如下图所示

可以看到本文首先利用一个编码器
ϕ
e
\phi_e
ϕe和关系网络
ϕ
r
\phi_r
ϕr将元训练集中的样本
x
n
k
x_n^k
xnk投影到一个低维的隐空间
z
\mathbf{z}
z中,得到每个任务对应的隐向量
z
′
z'
z′,然后再利用解码器
ϕ
d
\phi_d
ϕd将隐向量
z
′
z'
z′转化为高维的模型参数
θ
i
′
\theta_i'
θi′,用于类别预测并计算损失。在内层循环中,不再直接对模型参数
θ
i
′
\theta_i'
θi′进行更新,而是对隐向量
z
′
z'
z′进行更新,更新过程如下
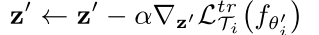
完成一个内层循环后,同样可以获得多个任务对应的模型参数
θ
i
′
\theta_i'
θi′,然后在外层循环中,对编码器
ϕ
e
\phi_e
ϕe,关系网络
ϕ
r
\phi_r
ϕr,解码器
ϕ
d
\phi_d
ϕd和学习率
α
\alpha
α等参数进行更新,更新过程如下
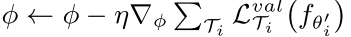
LEO算法的整体思路已经明确了,下面我们具体介绍下编码器
ϕ
e
\phi_e
ϕe,关系网络
ϕ
r
\phi_r
ϕr和解码器
ϕ
d
\phi_d
ϕd是怎样实现的。其中编码器
ϕ
e
\phi_e
ϕe比较简单就是一个常规的特征提取网络,将输入的样本投影到一个编码空间中。对于任务
T
i
\mathcal{T}_i
Ti,其包含
N
N
N各类别,每个类别包含
K
K
K个样本,因此经过编码后能够得到
N
K
NK
NK个编码(特征向量),将所有的编码,两两配对级联起来,可以得到
(
N
K
)
2
(NK)^2
(NK)2组编码,将其输入到关系网络
ϕ
r
\phi_r
ϕr中,并将输出的参数按照类别进行分组,每组再求平均值,得到
N
N
N个类别对应的输出结果,计算过程如下
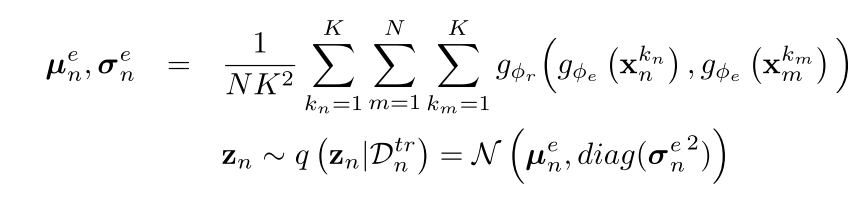
可以看到关系网络输出的参数其实是一个多维高斯混合分布的均值
μ
n
e
\mu_n^e
μne和方差
σ
n
e
\sigma_n^e
σne,共有
2
×
N
2\times N
2×N个参数,然后在这个分布中进行采样,得到每个类别对应的隐向量
z
n
z_n
zn。将隐变量
z
n
z_n
zn输入到解码器中,得到另一个多维高斯混合分布的均值
μ
n
d
\mu_n^d
μnd和方差
σ
n
d
\sigma_n^d
σnd,从中采样得到模型参数权重
w
n
w_n
wn,计算过程如下
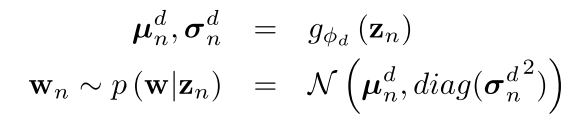
本文中的模型就是一个
N
N
N维的softmax分类器,所以模型参数
θ
i
′
=
{
w
n
∣
n
=
1
,
.
.
.
,
N
}
\theta_i'=\left \{w_n|n=1,...,N\right \}
θi′={wn∣n=1,...,N},因此得到了
w
n
w_n
wn就得到了模型参数
θ
i
′
\theta_i'
θi′。但是与MAML得到的实例化模型不同,本文得到的其实是一个条件概率分布,并从中随机采样得到每个任务对应的模型参数
θ
i
′
\theta_i'
θi′。
实现过程
网络结构
分类器,编码器,关系网络,解码器均采用3层MLP。
损失函数
内存循环采用交叉熵损失函数,计算过程如下
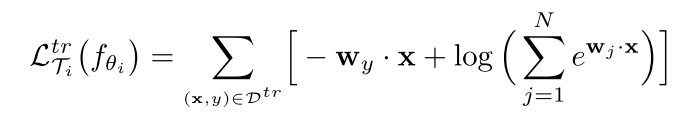
外层循环采用的损失函数包含四个部分,计算过程如下
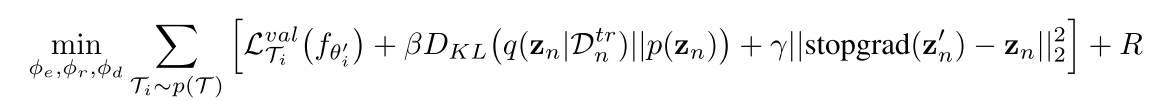
第一项
L
T
i
v
a
l
\mathcal{L}_{\mathcal{T}_i}^{val}
LTival仍采用交叉熵损失函数;第二项是一个加权KL散度,其中
p
(
z
n
)
∼
N
(
0
,
I
)
p(z_n)\sim N(0,I)
p(zn)∼N(0,I)是一个标准正态分布,这一项是用于正则化隐空间,鼓励生成模型(解码器)通过去除隐空间中梯度维度之间的联系,来简化LEO的内层循环更新过程;第三项的目的是为了鼓励编码器和关系网络生成的参数初始化尽可能地接近适当的编码,这将降低自适应过程的负担;最后一项是一个L2正则化损失项,计算过程如下
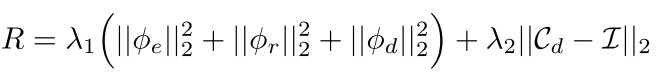
训练策略
算法的训练过程如下

算法推广
与MAML一样,本文的算法也可以引入到其他领域如强化学习,NLP等,但本文没有做进一步的探讨。
创新点
- 在MAML的基础上,引入了隐空间,并且在隐空间内实现参数的内层循环更新
- 不是直接利用编码器或解码器得到对应的隐变量或模型权重参数,而是得到一个条件概率分布,通过随机采样的方式,来间接的获得参数
算法评价
本文是在MAML的基础上进一步进行研究,首先对每一个新任务的模型进行参数初始化时,其参数都是采样自一个与训练数据相关的条件概率分布( w n w_n wn采样自条件概率分布 p ( w ∣ z n ) p(w|z_n) p(w∣zn),而 z n z_n zn又是采样自 p ( z ∣ D n t r ) p(z|\mathcal{D}^{tr}_n) p(z∣Dntr)),因此每个任务模型的起点都是与任务相关的,这有利于自适应更新过程。其次,利用关系网络能够更好地考虑到所有输入数据的之间关系。然后,在低维的隐空间内进行参数更新,这种方式能更有效地适应模型的行为。最后,通过随机采样的方式获取模型参数,这使得整个过程都是随机的,能够表达出小样本条件下的不确定性。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。
















 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











