







一、前言
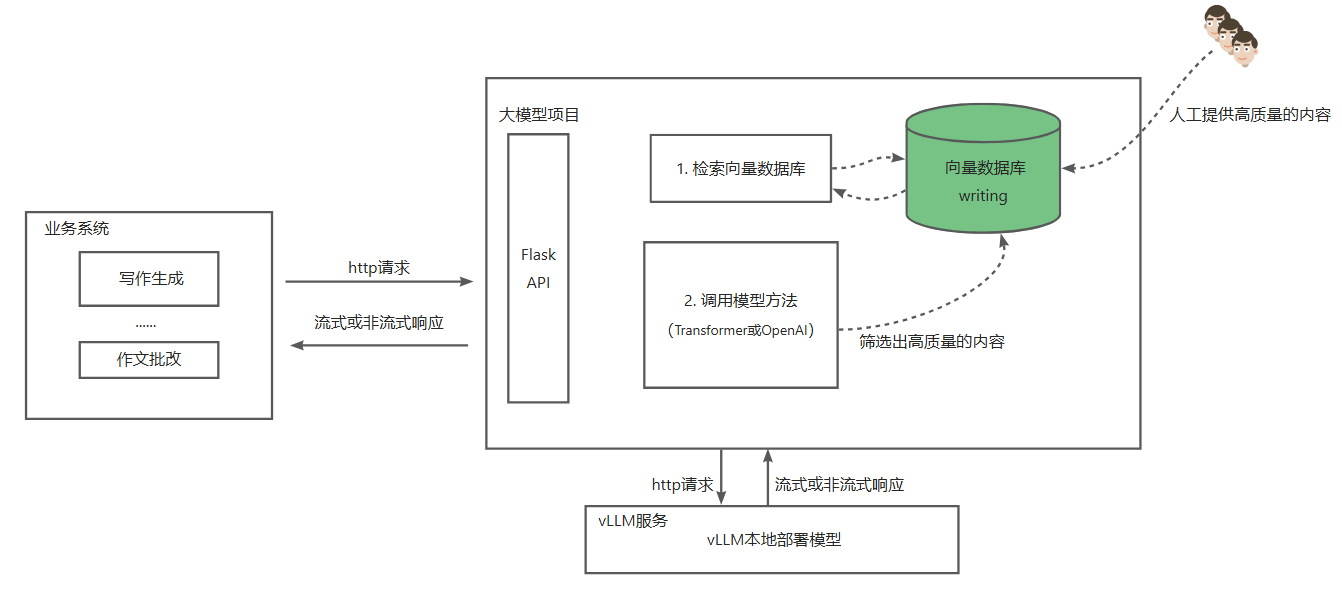
结合前面掌握的vLLM部署Qwen7B模型、通过Embedding模型(bdg-large-zh模型)提取高质量作文内容并预先存储到Milvus向量数据库中,我们很容易实现RAG方案进一步提高写作内容的生成质量。
本篇要实现的目标是:通过FlaskAPI对上游业务系统提供一个开放接口,调用该接口将返回写作内容(非流式)。 该接口优先通过dbg-large-zh模型生成ebedding向量,然后从Milvus向量数据库中查询和向量相似度最高的1条数据,若查到数据且相似度达到指定阈值(如0.75或0.9,具体数值由业务决定),则直接返回Milvus中存储的内容,否则调用Qwen2-7B-Instruct模型生成写作内容。
要实现的架构为:
往期文章:
快速掌握大语言模型-Qwen2-7B-Instruct落地1-CSDN博客
快速掌握大语言模型-Qwen2-7B-Instruct落地2-CSDN博客
快速掌握向量数据库-Milvus探索2_集成Embedding模型-CSDN博客
二、术语
2.1 vLLM
vLLM采用连续批处理,吞吐量相比传统框架(如Hugging Face Transformers)可提升5-10倍;
分布式推理支持允许在多GPU环境下并行处理;
通过PagedAttention技术,vLLM将注意力计算的键值(KV Cache)分页存储在显存中,动态分配空间以减少碎片;
内置了对 OpenAI API 的兼容支持,可直接启动符合 OpenAI 标准的 API 服务;
2.2 FastApi
基于Python的Web框架,主要用于构建高性能、易维护的API和Web应用程序,通过FastApi可以对上游业务系统暴露API,上游业务系统通过http请求即调用相关接口。
2.3 Milvus
Milvus是一个专为处理高维向量数据设计的开源向量数据库,支持数百亿级数据规模,在多数开源向量数据库中综合表现突出(一般是其他的2~5倍)。
提供三种部署方式:本地调试Milvus Lite、企业级小规模数据的Milvus Standalone(一亿以内向量)、企业级大规模数据的Milvus Distributed (数百亿向量)。
2.4 bge-large-zh
bge-large-zh模型是专为中文文本设计的,同尺寸模型中性能优异的开源Embedding模型,凭借其中文优化、高效检索、长文本支持和低资源消耗等特性,成为中文Embedding领域的标杆模型。
2.5 Qwen2-7B-Instruct
Qwen2-7B-Instruct 是阿里云推出的开源指令微调大语言模型,属于 Qwen2 系列中的 70 亿参数版本。该模型基于 Transformer 架构,通过大规模预训练和指令优化,展现出强大的语言理解、生成及多任务处理能力
三、代码
3.1 代码目录
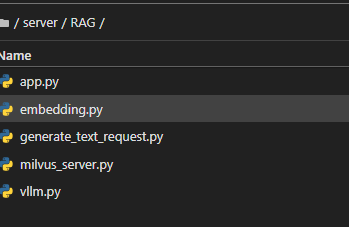
- vllm.py :提供调用Qwen7B模型的方法;
- app.py :提供通过FastAPI暴露给上游业务系统调用的API;
- embedding.py :提供调用bge-large-zh模型生成内容的embedding向量的方法 ;
- milvus_server.py :提供查询Milvus向量数据库的方法;
- generate_text_request.py : 模拟上游业务系统通过http调用app.py提供的生成写作内容的API
3.2 完整代码
3.2.1 安装依赖
# vllm需要的依赖
pip install vllm
# milvus需要的依赖
python -m pip install -U pymilvus
3.2.2 app.py
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import logging
from vllm import Model
from embedding import search_writing_embeddings
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
app = FastAPI()
model = Model()
# 流式响应
@app.get("/chat")
async def chat(prompt: str):
return StreamingResponse(model.generate_stream(prompt), media_type="text/plain")
# 非流式响应(RAG增强检索)
@app.get("/generate")
async def generate(prompt: str):
# 优先通过embedding向量从milvus中搜索相似度最高的1条数据,如果相似度达到90%以上,则直接返回该数据的content_full字段作为结果,否则调用llm模型生成
# 这里的90%是一个阈值,可以根据实际情况调整
res = search_writing_embeddings(prompt)
print(f"search_writing_embeddings:{res}")
threshold = 0.75
if res and res[0] and res[0][0]['distance'] >= threshold:
print("使用milvus中的数据")
result = res[0][0]['entity']['content_full']
else:
print("使用llm模型生成")
result = await model.generate_text(prompt)
return result
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)3.2.3 vllm.py
# 大语言模型LLM文件
import logging
from openai import OpenAI
from pydantic_core import Url
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
model_path = "/mnt/workspace/models/Qwen2-7B-Instruct"
base_url = "http://localhost:9000/v1"
class Model:
def __init__(self):
# 创建 OpenAI 客户端实例,这里的密钥可以随意填写,vLLM 不需要验证
self.client = OpenAI(api_key="EMPTY", base_url= base_url)
# 流式处理
async def generate_stream(self, prompt: str):
try:
logging.info(f"开始处理提示: {prompt}")
# 使用新客户端调用 API
# 确保使用类的实例属性 self.client
chat_response = self.client.chat.completions.create(
model= model_path,
messages=[{"role": "user", "content": prompt}],
stream=True,
max_tokens=512,
temperature=0.7,
top_p=0.9
)
for chunk in chat_response:
msg = chunk.choices[0].delta.content
if msg is not None:
logging.info(f"生成文本块: {msg}")
yield msg
logging.info("流式输出结束")
except Exception as e:
logging.error(f"处理提示时出错: {e}", exc_info=True)
# 非流式处理
async def generate_text(self, prompt: str):
try:
logging.info(f"开始处理提示: {prompt}")
# 使用新客户端调用 API
response = self.client.chat.completions.create(
model= model_path,
messages=[{"role": "user", "content": prompt}],
stream=False,
max_tokens=512,
temperature=0.7,
top_p=0.9
)
# 获取完整响应
content = response.choices[0].message.content
logging.info(f"文本生成完成:{content}")
return content
except Exception as e:
logging.error(f"处理提示时出错: {e}", exc_info=True)
return ""
3.2.4 embedding.py
from transformers import AutoTokenizer, AutoModel
import torch
import random
from milvus_server import WritingDTO, insert_data_to_milvus,search_data_from_milvus
# 加载模型和分词器
model_path = "/mnt/workspace/models/bge-large-zh" # 根据实际情况修改
model = AutoModel.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 推理模式
model.eval()
# 写作生成合集名称
writing_collection_name = "writing"
def get_embedding_list(text_list):
"""
输入文本列表,返回文本的embedding向量
:param text_list: 待获取embedding的文本集合
:return: ebedding向量集合
"""
# 编码输入(自动截断和填充)
encoded_input = tokenizer(text_list, padding=True, truncation=True, return_tensors='pt')
# 调用大模型得到文本的embedding
with torch.no_grad():
model_output = model(**encoded_input)
sentence_embeddings = model_output[0][:, 0] # bdge-large-zh 模型的输出是一个元组,第一个元素是句子的嵌入向量,1024维
print(f"sentence_embeddings:{ len(sentence_embeddings[0])}")
# 归一化处理:可以提高模型的稳定性和收敛速度,尤其在处理向量相似度计算时非常有用
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
# 转换嵌入向量为列表
embeddings_list = sentence_embeddings.tolist()
return embeddings_list
def insert_writing_embeddings(text_list):
"""
获取写作生成内容的文本的embedding向量,并写入到milvus中
:param text_list: 待获取embedding的写作生成内容集合
:return: 写入到到milvus结果,ebedding向量集合
"""
# 获取embedding
embeddings_list = get_embedding_list(text_list)
print(f"embeddings_list:{len(embeddings_list)}")
# 写作记录合集
writing_list = []
for i, embedding in enumerate(embeddings_list):
writingDTO = WritingDTO(embedding, text_list[i], random.randint(500,9999)) #组装对象数据,其中biz_id是业务ID,这里这里方便说明暂设为随机数字
writing_list.append(writingDTO.to_dict()) # 将对象转换为字典,并添加到集合中
# 插入数据到 Milvus
res = insert_data_to_milvus(writing_collection_name,writing_list)
return res,embeddings_list
def search_writing_embeddings(text):
"""
获取写作内容的embedding向量,并从milvus中搜索
"""
# 获取embedding
embeddings_list = get_embedding_list([text])
# 搜索数据
res = search_data_from_milvus(writing_collection_name,embeddings_list,["id","content_full","biz_id"],1)
return res
if __name__ == "__main__":
# 输入文本
content = "推荐广州有哪些好玩的地方"
# 将文本转eembedding向量并写入到milvus中
res = search_writing_embeddings(content)
print("Search result:", res)3.2.5 milvus_server.py
from pymilvus import MilvusClient, db
import numpy as np
from pymilvus.orm import collection
from typing import Iterable
# 定义 Milvus 服务的主机地址
host = "阿里云公网IP"
# 创建一个 Milvus 客户端实例,连接到指定的 Milvus 服务
client = MilvusClient(uri=f"http://{host}:19530",db_name="db001") # 连接到 Milvus 服务并选择数据库 "db001"
# collection_name = "writing" # 指定要连接的集合名称 "writing"
# 写作生成对象
class WritingDTO:
def __init__(self, content_vector, content_full, biz_id):
self.content_vector = content_vector
self.content_full = content_full
self.biz_id = biz_id
def to_dict(self):
"""
将 WritingDTO 对象转换为字典。
:return: 包含 WritingDTO 对象属性的字典
"""
return {
"content_vector": self.content_vector,
"content_full": self.content_full,
"biz_id": self.biz_id
}
def insert_data_to_milvus(collection_name,data):
"""
将对象集合中的数据插入到 Milvus 集合中。
:param data: 字典对象集合
:return: 插入操作的结果
"""
print(f"insert_data_to_milvus:{collection_name}")
print(f"insert_data_to_milvus:{len(data)}")
res = client.insert(
collection_name=collection_name,
data=data
)
return res
def search_data_from_milvus(collection_name,query_vector,output_fields, top_k=10):
"""
从 Milvus 集合中搜索与查询向量最相似的向量。
:param query_vector: 查询向量
:param top_k: 返回的最相似向量的数量
:return: 搜索结果
"""
res = client.search(
collection_name= collection_name, # 合集名称
data=query_vector, # 查询向量
search_params={
"metric_type": "COSINE", # 向量相似性度量方式,COSINE 表示余弦相似度(适用于文本/语义相似性场景); 可选 IP/COSINE/L2
"params": {"level":1},
}, # 搜索参数
limit=top_k, # 查询结果数量
output_fields= output_fields, # 查询结果需要返回的字段
consistency_level="Bounded" # 数据一致性级别,Bounded允许在有限时间窗口内读取旧数据,相比强一致性(STRONG)提升 20 倍查询性能,适合高吞吐场景;
)
return res3.2.6 generate_text_request.py
import requests
url = "http://0.0.0.0:8000/generate?prompt=广州有什么好玩的"
response = requests.get(url, stream=True)
print(response.text)四、调用结果
4.1 启动vllm
python -m vllm.entrypoints.openai.api_server --model /mnt/workspace/models/Qwen2-7B-Instruct --swap-space 10 --disable-log-requests --max-num-seqs 256 --host 0.0.0.0 --port 9000 --dtype float16 --max-parallel-loading-workers 1 --max-model-len 10240 --enforce-eager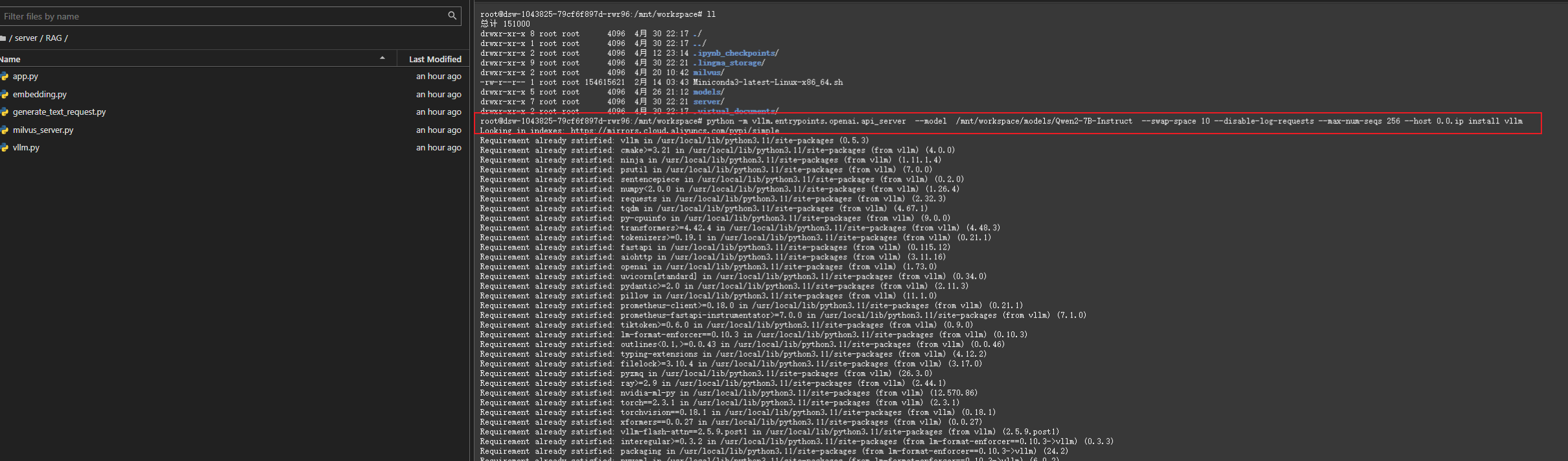
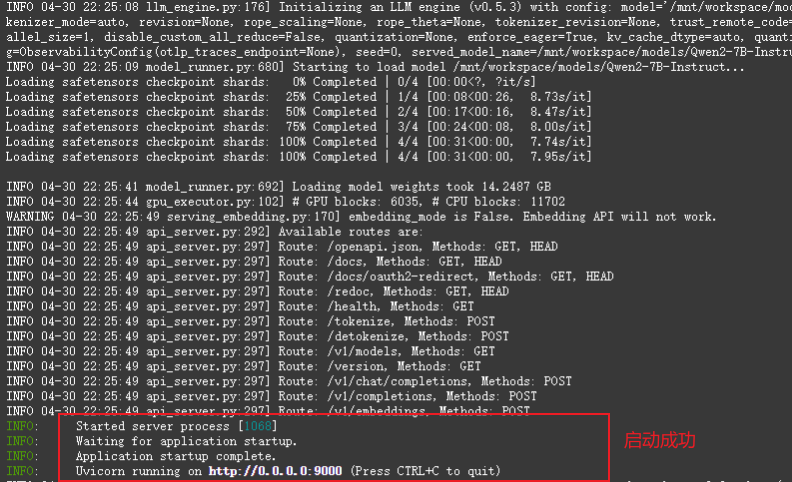
4.2 启动FastAPI

4.3 上游业务系统调用

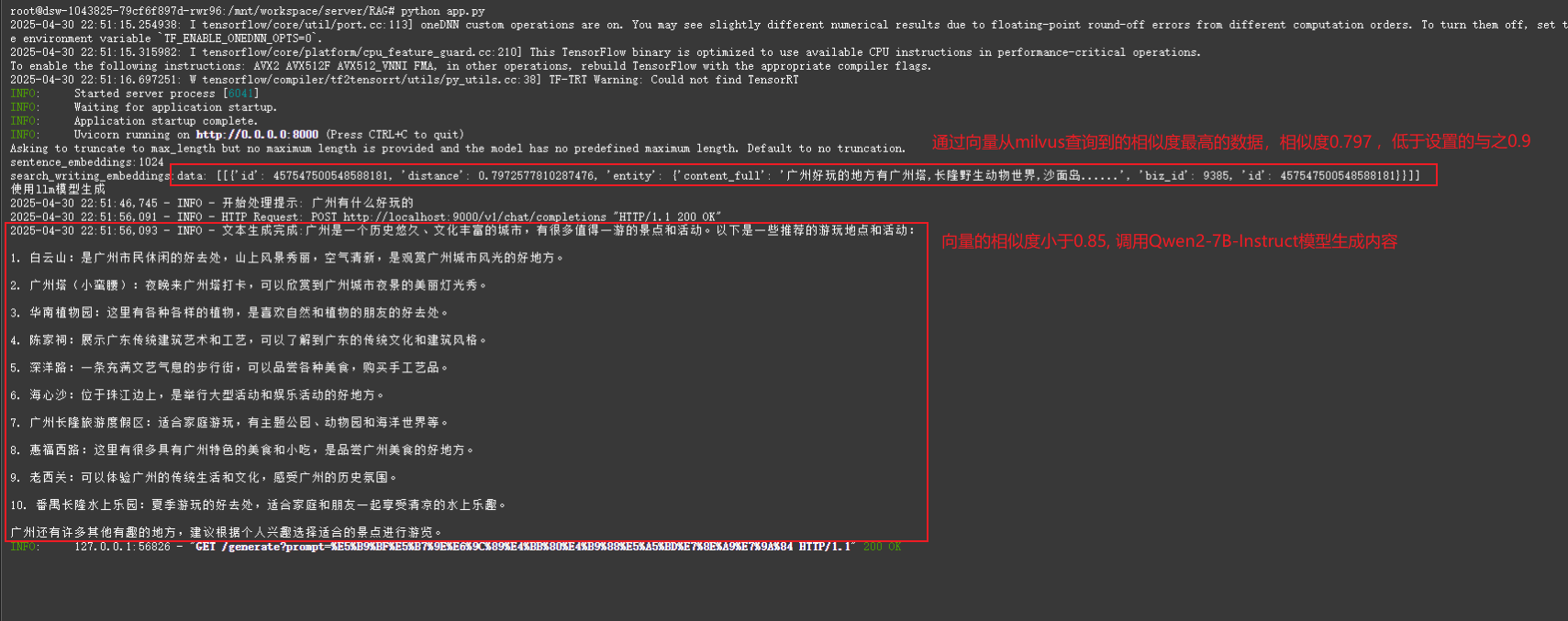
情况1:向量查询结果相似度低于阈值(90%相似度)的情况 ==> 通过Qwen7B模型生成内容
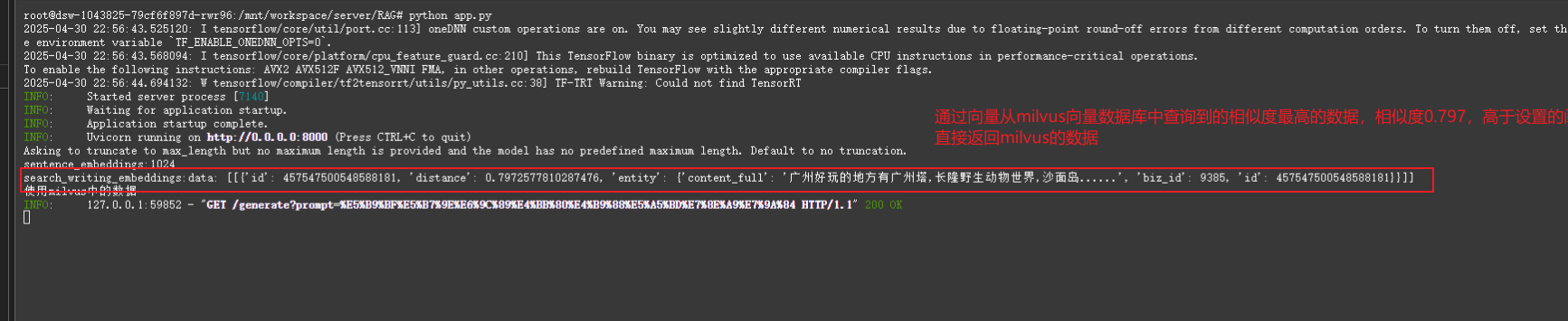
情况2:向量查询结果相似度高于于阈值(75%相似度)的情况 ==> 直接返回向量查询结果的内容


















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









