









【预训练语言模型】KG-BERT: BERT for Knowledge Graph Completion
核心要点:
- 知识图谱是不全的,先前的补全方法只是考虑稀疏的结构信息,忽略了上下文的文本信息;
- 将实体、关系和三元组是为序列,并将知识图谱补全的任务视作序列分类任务;
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | MT-DNN |
| 2 | 发表位置 | ACL 2019 |
| 3 | 所属领域 | 自然语言处理、预训练语言模型 |
| 4 | 研究内容 | 预训练语言模型、知识增强语言模型 |
| 5 | 核心内容 | Knowledge-enhanced PLM |
| 6 | GitHub源码 | https://github.com/sunyilgdx/NSP-BERT |
| 7 | 论文PDF | https://arxiv.org/pdf/1901.11504.pdf |
一、动机
- 知识图谱对人工智能领域的贡献很大,但是知识图谱的普遍问题是图谱不全(incompleteness);
- 本文提出使用BERT来结合知识图谱实现图谱补全;
二、方法:KG-BERT
BackBone选择BERT,提出KG-BERT模型在预训练好的BERT基础上继续fine-tuning。
Triple Classification
将三元组转换为文本序列模式,转换方法如下图所示:
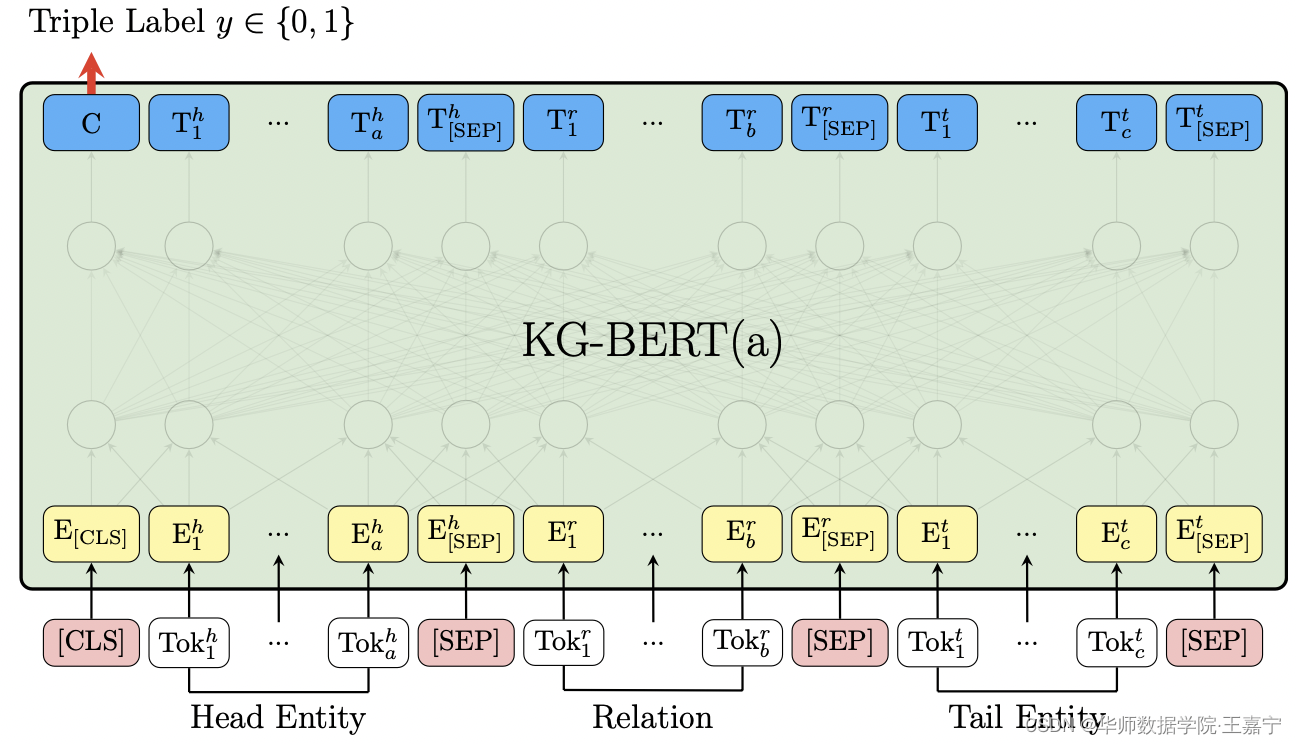
将实体、关系的名称或描述文本,通过[CLS]和[SEP]进行顺序拼接,喂入KG-BERT中后,获得[CLS]的表征向量,并进行二分类,判断该三元组是否成立。
数据划分是,分为正样本(三元组即在KG中)和负样本(给定一个三元组,随机替换实体或关系,且确保生成的新的三元组在KG中不存在),负样本形式化描述为:

最终使用交叉信息熵损失函数:

Relation Classification
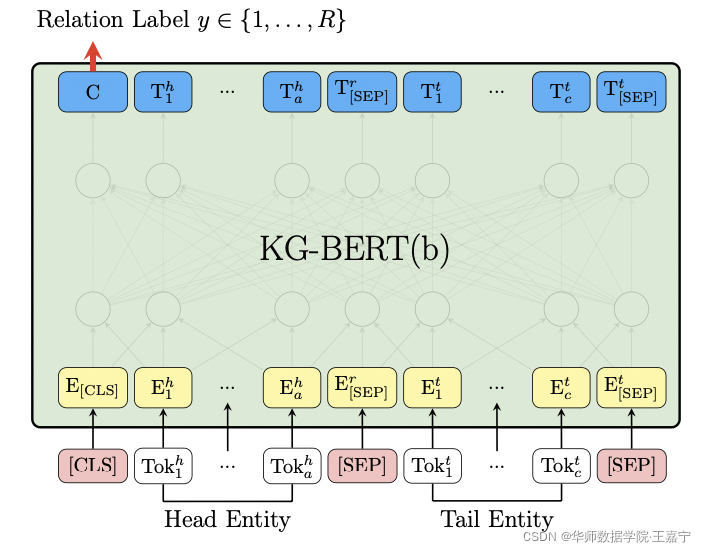
KG-BERT也可以完成关系分类,输入两个实体或实体描述,输出多类分类。采用负对数损失函数:

三、实验
数据集(KG):

Baseline:
均为知识表示学习相关方法:

评估任务:
-
triple classification:

-
link prediction:

-
relation prediction:



















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











