






图像拼接系列相关论文精读
- Seam Carving for Content-Aware Image Resizing
- As-Rigid-As-Possible Shape Manipulation
- Adaptive As-Natural-As-Possible Image Stitching
- Shape-Preserving Half-Projective Warps for Image Stitching
- Seam-Driven Image Stitching
- Parallax-tolerant Image Stitching
- Parallax-Tolerant Image Stitching Based on Robust Elastic Warping
文章目录
前言
论文题目:超级点:自监督感兴趣点检测和描述
论文地址:SuperPoint
代码链接1:https://github.com/magicleap/SuperPointPretrainedNetwork
代码连接2:https://github.com/rpautrat/SuperPoint
摘要
在计算机视觉领域,本文提出一个训练感兴趣点检测器和描述子的自监督学习框架,为了适应庞大的多视野几何问题。与基于块的神经网络不同,我们的全卷积模型在整张图片上操作并计算局部感兴趣点和描述子,只通过一次前向计算。我们介绍单应变换,它是一个多尺度多单应的研究,增加感兴趣点检测的重复性并执行跨域变换。我们的模型在MS-COCO数据集上训练,比最初的预变换深度模型和其他传统角点检测器检测到的兴趣点都多。和LIFT,SIFT,ORB相比,单应计算结果更好。
1.介绍
几何计算机视觉任务,如同步定位和映射(SLAM),运动结构(SFM),相机校准和图像匹配,它们的第一步是提取图像特征点。感兴趣点是2D空间中来自不同光线条件和观测点的稳定且重复的。数学和计算机视觉的子域如多视野几何由理论和算法组成,建立在假设之上,假设感兴趣点可以被提取和图像间匹配。然而,大多数真实世界的结算及系统缺少图片,没有理想化的局部点。
卷积神经网络在几乎所有图像作为输入的任务中表现出很高的水平。特别是,全卷积神经网络预测2D关键点或坐标已经有很好的研究,如人类姿态估计,目标检测,房间布局估计。这些技术的核心是人类标注的真实标签。(ground truth locations)。
类似地构想把兴趣点检测作为大尺度有监督的机器学习问题和训练最新的卷积神经网络结构取检测它们似乎是合理的。不幸地是,当比较语义任务如人体关键点估计时,训练的神经网络检测人体部位如嘴角或左踝,感兴趣点检测的概念是语义不明的。因此,训练卷积神经网络用强监督兴趣点是重要的。
不同于使用人类标注取定义感兴趣点,我们提出一个自监督解决办法——自训练。在我们的方法中,我们创建一个伪真实兴趣点区域,通过兴趣点检测器自己监督,而不是依靠大量人类标注影响。
为了生成伪真实兴趣点,我们首先在一个有百万例子的人工合成数据集中训练全卷积网络,叫做Synthetic Shapes。如下图。这个数据集主要是一些形状的角点。
这个数据集包含简单的几何图形,兴趣点都无歧义。命名为MagicPoint,它比传统的兴趣点检测器明显更好。尽管变换困难,MagicPoint在真实图片上表现也很好。然而,当在纹理和模式不同的图形集合上使用的典型的兴趣点检测器相比,MagicPoint少检测了很多潜在的兴趣点。为了适应真实图片的性能,我们提出一个多尺度,多变换技术——改进的单应变换(Homographic Adaptation)。
Homographic Adaptation可以自监督训练兴趣点。它多次扭曲输入图像,以帮助兴趣点检测器看到不同的观测点和尺度场景。如下图。

Homographic Adaptation和MagicPoint结合提升检测器性能,生成伪真实兴趣点。检测结果更重复更红火数量更多,因此命名为超级点。
检测鲁棒性和重复性的兴趣点之后的最常见步骤就是给每个兴趣点一个不同维度的描述符以获得更高的语义。因此,我们最后将超级点和一个描述器子网结合。如下图。
虽然超级点结构由卷积层深度堆叠而成,可以提取多尺度特征,但也是直接和兴趣点网络结合,直接连一个附加的子网计算兴趣点描述子。整个系统展示在图1.
2.相关工作
主要在几个方面和其他方法对比,有传统的有基于深度学习的。
还和其他的自监督方法比较了,有两篇之前的铺垫。
Geometric Matching Networks [20]
and Deep Image Homography Estimation [4]
。然而这些方法缺少兴趣点和点的关联,不发适应高等级计算机视觉任务。
3.SuperPoint结构
全卷积网络,在整张图像上操作,通过混合长度描述子产生兴趣点聚类,单一前向计算。模型用一个单一共享编码器降低输入图像维度,然后分成两个解码器头,分布学习具体权重,一个是检测器一个是描述子。两个分支大多数参数可以共享,不同于先检测特征点后计算描述的传统结构,缺少共享计算和表现。
3.1 共享编码器
超级点结构使用VGG风格的编码器来降低图像维度。编码器由卷积层,池化层和非线性激活函数组成。用三个最大池化层,图像大小是 H × W H \times W H×W, H c = H / 8 , W c = W / 8 H_c = H / 8 ,W_c = W / 8 Hc=H/8,Wc=W/8。低维度输出像素叫cells,在8×8的像素cell的编码结果中,三个2×2非重叠最大池化操作。编码器将输入图片 I ∈ R H × W I \in \mathbb{R}^{H \times W} I∈RH×W映射到中间tensor B ∈ R H c × W c × F \mathcal{B} \in \mathbb{R}^{H_c \times W_c \times F} B∈RHc×Wc×F,更小的空间维度和更大的通道深度( H c < H , W c < W a n d F > 1 H_c < H,W_c <W \ and \ F>1 Hc<H,Wc<W and F>1)。
3.2 兴趣点解码
对于兴趣点检测,每个输出像素都和输入像素都和一个可能的点相关。标准网络涉及为稠密预测,是一个编码-解码结构,分辨率通过池化降低或步长卷积,然后上采样回到原来的分辨率,类似SegNet。不幸的是,上采样层往往计算量大,还会有棋盘效应(checkerboard artifacts)。因此,我们涉及兴趣点检测器头降低模型计算量。(这个解码器没有参数,卷积子像素,Pytorch中是pixel shuffle)
兴趣点检测器头计算 X ∈ R H c × W c × 65 \mathcal{X} \in \mathbb{R}^{H_c \times W_c \times 65} X∈RHc×Wc×65,输出一个大小 R H × W \mathbb{R}^{H \times W } RH×W的向量。65通道与局部相符合,非重叠8×8网格区域像素是一个额外的无兴趣点垃圾桶。通过softmax,垃圾桶的维度由 R H c × W c × 64 \mathbb{R}^{H_c \times W_c \times 64} RHc×Wc×64变为 R H × W \mathbb{R}^{H \times W } RH×W。
3.3 描述子解码器
描述头计算
D
H
c
×
W
c
×
D
\mathbb{D}^{H_c \times W_c \times D}
DHc×Wc×D,输出张量为
R
H
×
W
×
D
\mathbb{R}^{H \times W \times D }
RH×W×D。为了输出L2正则化混合长度描述子的稠密映射,我们使用和UCN模型相似的取首先输出一个半稠密网格描述子(每个8像素)。学习半稠密描述子而不是稠密的降低训练内存和保持运行时间平滑。解码器执行描述子的双三次差值,然后L2正则化激活统一长度。见图3.

3.4 损失函数
最终损失是两个中间损失之和:一个是兴趣点检测器
L
p
\mathcal{L_p}
Lp,一个是描述子
L
d
\mathcal{L_d}
Ld。我们使用既有伪真实兴趣点和随机生成单应矩阵中生成的真实点扭曲图像。同时优化两个损失,给定一对图像,如2c中展示的。我们使用
λ
\lambda
λ均衡最终损失:
L
(
X
,
X
′
,
D
,
D
′
;
Y
,
Y
′
,
S
)
=
L
p
(
X
,
Y
)
+
L
p
(
X
′
,
Y
′
)
+
λ
L
d
(
D
,
D
′
,
S
)
(1)
\mathcal{L(X,X',D,D';Y,Y',S) = L_p(X,Y)+L_p(X',Y')+\lambda L_d(D,D',S)}\tag1
L(X,X′,D,D′;Y,Y′,S)=Lp(X,Y)+Lp(X′,Y′)+λLd(D,D′,S)(1)
感兴趣点检测器损失函数
L
p
\mathcal{L_p}
Lp是单元
x
h
w
∈
X
\mathbf{x}_{hw} \in \mathcal{X}
xhw∈X的全卷积交叉熵损失。相关真实兴趣点标签Y(如果两个真实角点位置相同,随机选择其中之一)和独立参数作为
y
h
w
y_{hw}
yhw.损失是:
L
p
(
X
,
Y
)
=
1
H
c
W
c
∑
h
=
1
w
=
1
H
c
,
W
c
l
p
(
x
h
w
;
y
h
w
)
,
(2)
\mathcal{L_p(X,Y)} = \frac{1}{H_cW_c}\sum_{h=1 w=1}^{H_c,W_c}l_p(x_{hw};y_{hw}),\tag2
Lp(X,Y)=HcWc1h=1w=1∑Hc,Wclp(xhw;yhw),(2)
where
l
p
(
x
h
w
;
y
)
=
−
l
o
g
(
e
x
p
(
x
h
w
y
)
∑
k
=
1
65
e
x
p
(
x
h
w
k
)
.
(3)
l_p(x_{hw};y) = -log\bigg(\frac{exp(x_{hwy})}{\sum_{k=1}^{65}exp(x_{hwk}}\bigg).\tag3
lp(xhw;y)=−log(∑k=165exp(xhwkexp(xhwy)).(3)
描述器损失用所有的描述子单元。(h,w)和(h’,w’)单应关系可以写作:
s
h
w
h
′
w
′
=
{
1
,
i
f
∣
∣
H
p
h
w
^
−
p
h
′
w
′
∣
∣
≤
8
0
,
o
t
h
e
r
w
i
s
e
(4)
s_{hwh'w'} = \begin{cases} 1,& if ||\widehat{\mathcal{H\mathbf{p}_{hw}}}-\mathbf{p}_{h'w'}||\leq 8 \\ 0,& otherwise \end{cases}\tag4
shwh′w′={1,0,if∣∣Hphw
−ph′w′∣∣≤8otherwise(4)
其中,
p
h
′
w
′
\mathbf{p}_{h'w'}
ph′w′是(h,w)单元的中间像素,
H
p
h
w
^
\widehat{\mathcal{H\mathbf{p}_{hw}}}
Hphw
是单应乘中间像素,通常是通过欧氏距离和坐标得到。
描述子损失定义为:
L
d
(
D
,
D
′
,
S
)
=
1
(
H
c
W
c
)
2
∑
h
=
1
w
=
1
H
c
,
W
c
∑
h
′
=
1
w
′
=
1
H
c
,
W
c
l
d
(
d
h
w
,
d
′
h
w
;
s
h
w
h
′
w
′
)
,
(5)
\mathcal{L_d(D,D',S)}=\frac{1}{(H_cW_c)^2}\sum_{h=1w=1}^{H_c,W_c}\sum_{h'=1w'=1}^{H_c,W_c}l_d(\mathbf{d}_{hw},\mathbf{d'}_{hw};s_{hwh'w'}),\tag5
Ld(D,D′,S)=(HcWc)21h=1w=1∑Hc,Wch′=1w′=1∑Hc,Wcld(dhw,d′hw;shwh′w′),(5)
where
l
d
(
d
,
d
′
;
s
)
=
λ
d
∗
s
∗
m
a
x
(
0
,
m
p
−
d
T
d
′
)
+
(
1
−
s
)
∗
m
a
x
(
0
,
d
T
d
′
−
m
n
)
.
(6)
l_d(\mathbf{d},\mathbf{d'};s) = \lambda_d * s *max(0,m_p-\mathbf{d^Td'})+(1-s)*max(0,\mathbf{d^Td'}-m_n).\tag6
ld(d,d′;s)=λd∗s∗max(0,mp−dTd′)+(1−s)∗max(0,dTd′−mn).(6)
4.合成形状预训练
MagicPoint结合Homographic Adaptation 生成伪真实兴趣点标签,自监督训练无标签图像
4.1 人工合成形状

移除了有歧义的标签。当图像渲染过了之后,应用单应扭曲增强训练样本数量。数据是即时生成的,不会经过网络两次。
4.2 MagicPoint
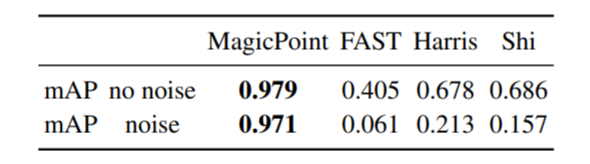
和其他传统方法比,mAP很大。
5.Homographic Adaptation
本文方法的核心:将输入图像随机单应扭曲,再合输入结合形成新的结果——Homographic Adaptation。过程如下图:
简言之,输入图像检测到特征点和随机扭曲得到的其他特征点结合,形成了最终的特征点,这样做得到的特征点肯定比只在单一视角得到的特征点多。
5.1 公式
f
θ
(
⋅
)
f_\theta(\cdot)
fθ(⋅)代表我们希望去改变的初始兴趣点函数,
I
I
I代表输入图片,x是兴趣点结果,H是随机单应,那么:
x
=
f
θ
(
I
)
(7)
\mathbf{x} = f_\theta(I)\tag7
x=fθ(I)(7)
理想化的兴趣点生成器应该服从于单应矩阵。如果输出变为输入,函数
f
θ
(
⋅
)
f_\theta(\cdot)
fθ(⋅)会随着H改变。换句话说,改变的检测器满足如下式子:
H
x
=
f
θ
(
H
(
I
)
)
,
(8)
\mathcal{H}\mathbf{x} = f_\theta(\mathcal{H}(I)),\tag8
Hx=fθ(H(I)),(8)
将单应矩阵移到等式右侧:
x
=
H
−
1
f
θ
(
H
(
I
)
)
.
(9)
\mathbf{x} = \mathcal{H}^{-1}f_\theta(\mathcal{H}(I)).\tag9
x=H−1fθ(H(I)).(9)
实际上,检测器不是完美协变的。(covariant:协变,线性变换一个量随另一个量变换的函数)。等式9中不同的单应矩阵会产生不同的兴趣点x。Homographic Adaptation的基本思想是再随机H的足够大样本中得到一个结果总和。结果聚集的超级点检测器如下:
F
^
(
I
;
f
θ
)
=
1
N
h
∑
i
=
1
N
h
H
i
−
1
f
θ
(
H
i
(
I
)
)
.
(10)
\hat{F}(I;f_\theta) = \frac{1}{N_h}\sum_{i=1}^{N_h}\mathcal{H}_i^{-1}f_\theta(\mathcal{H}_i(I)).\tag{10}
F^(I;fθ)=Nh1i=1∑NhHi−1fθ(Hi(I)).(10)
5.2 选择单应矩阵
并不是所有的3*3矩阵都是好的结果。为了能得到接近相机真实变化的矩阵,我们分解单应矩阵到更简单更少表现变换的级别。我们从已有的范围内,对于平移,缩放,平面选择和均衡投影损失,使用一个缩减正太分布。这些变化结合在一起,有一个初始的中心裁剪,帮助避免边界人工。如下图所示:s
使用平均召回。单应扭曲的数量
N
h
N_h
Nh是一个超参数,第一个单应没有改变,
N
h
=
1
N_h=1
Nh=1。确定最好的
N
h
N_h
Nh,实验证明超过100个单应,收益就会下降。
5.3 迭代单应改变

第一行是初始的,中间和最下面是通过Homographic Adaptation进一步训练出来的,提升了检测器性能。
6.实验细节
(由于需要SuperPoint更好地提取特征点,本文只关注网络模型的构建,并不关注训练过程,直接用预训练好的模型使用)。
8个3×3卷积层,大小为64-64-64-64-128-128-128-128。每两层之间有一个2×2池化层。每个解码器头有一个256单元的3×3卷积层,紧跟着一个65单元的1×1卷积层。所有的卷积层用ReLU非线性激活函数和BatchNorm正则化。
7.相关代码及检测效果
使用代码链接1中的源码,获得检测点和描述符并将其可视化。类似代码见如下链接:【Python+OpenCV】主流特征点检测器和描述子总结与实现附拼接结果(SIFT,SURF,ORB,AKAZE,FAST,BRIEF,CenSurE,BEBLID)
检测结果展示:



总结与思考
- 经过MagicPoint训练过的SuperPoint用于检测特征点时确实比传统的检测算法好,因为训练集中都是一些基本形状,那么在检测的图像中有形状和角点时,特征点很容易被检测出来。其他算法对比:【Python+OpenCV】主流特征点检测器和描述子总结与实现附拼接结果(SIFT,SURF,ORB,AKAZE,FAST,BRIEF,CenSurE,BEBLID)
- 不错的思路:多视角单应变换,将不同视角检测到的特征点合到一起。能不能应用到其他地方?
- 特征点更明确之后,拼接的准确率能否提升?
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











