







请先看【专栏介绍文章】:【图像去噪(Image Denoising)】关于【图像去噪】专栏的相关说明,包含适配人群、专栏简介、专栏亮点、阅读方法、定价理由、品质承诺、关于更新、去噪概述、文章目录、资料汇总、问题汇总(更新中)
文章目录
- 背景介绍
- 数据集
- 评估指标
- 参赛队伍
- 主要ideas和架构
- 各团队的具体方法
- 第1名:惊为天人的200万张自制训练集
- 第2名:堆叠模型到设备爆显存的临界点
- 第3名:边缘特征或许是决胜的关键
- 第4名:线性结构在竞赛中焕发的第二春
- 第5名:Restormer永远的神
- 第6名:阐明模型参数和复杂度是我最后的倔强
- 第7名:xxIR+xxIR=xxxxIR
- 第8名:Pureformer = SCUNet+Restormer
- 第9名:应该是一篇已经成熟的论文
- 第10名:换个题目重画个图就拿了第10
- 第11名:简简单单SCUNet第11名
- 第12名:超分模型也来凑热闹
- 第13名:Diffusion来了,但我才是第12名
- 第14名:GAN也有春天
- 第15名:虽竞赛但论文
- 第16名:走错赛道了?
- 第17名:结构图我都不用重新画!
- 第18名:Xformer+SwinIR < NAFNet+RCAN
- 第19名:一次难得的Diffusion实战机会
- 第20名:只用UNet是我最后的倔强
- 总结与思考
- 相关专栏
- 与我联系

背景介绍

Report连接:The Tenth NTIRE 2025 Image Denoising Challenge Report
The Tenth NTIRE 2025 Image Denoising Challenge是第十届CVPR NTIRE (New Trends in Image Restoration and Enhancement) Workshop研讨会比赛之一 —— 图像去噪挑战赛,旨在促进去噪领域的发展,对不同的去噪技术进行公平比较,促成潜在的合作关系。
标准设置:加噪声白噪(AWGN),σ=50。计算效率和模型复杂度不参与评判。
也就是说,只看涨点,无疑又是一场军备竞赛。
数据集
- 训练集:DIV2K的800张和LSDIR的84991张,允许使用额外的外部数据集,例如Flickr2K,允许使用高级数据增强方法;
- 验证集:DIV2K的100张和LSDIR的1000张;
- 测试集:DIV2K的100张和LSDIR的1000张;
其中,推理阶段可以访问DIV2K验证集的100张图像,测试阶段可以使用DIV2K测试集的100张图像和LSDIR 测试集的附加 100 张图像进行评估。为了确保公平,测试阶段的真实无噪声图像隐藏。
此外,严禁将DIV2K的验证集和测试集加到训练集之中。
评估指标
使用PSNR/SSIM衡量200个测试图像,官方提供代码:https://github.com/AHupuJR/NTIRE-0225_Dn50_challenge,包含加噪代码和baseline测试代码。
按官方代码格式提交到CodaLab评估服务器,反馈结果。
参赛队伍
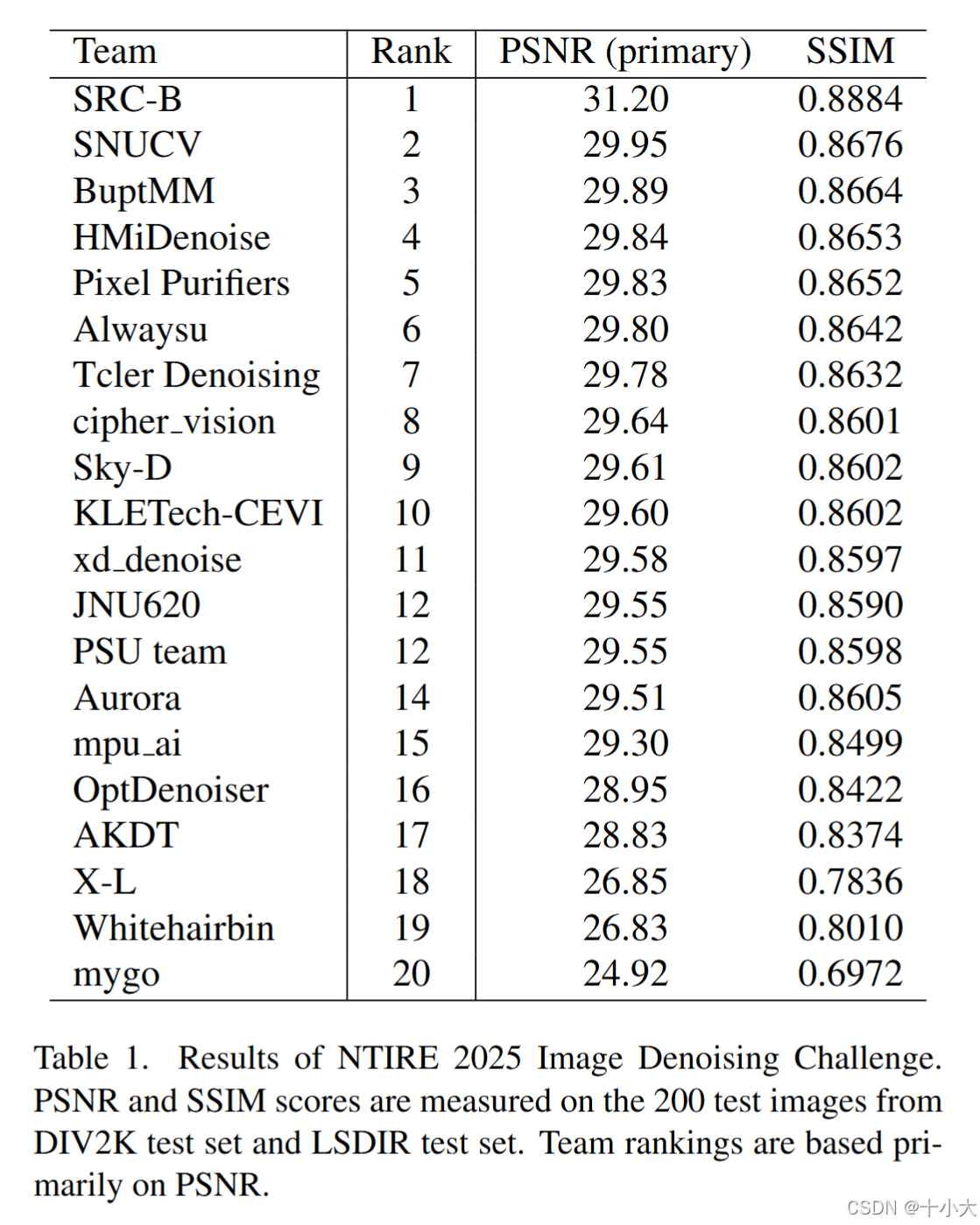
共20个队伍成绩有效,290名参与者。前六名的成绩都超过了去年。
在参赛人员中,我发现了一些熟悉的身影:
- MambaIR和MambaIRv2的作者,来自清华大学的Hang Guo,知乎:https://www.zhihu.com/people/hang-hang-oc,比较有趣的是第二名的团队使用了MambaIRv2;
- CVPR 2024 HNN的作者;
- AKDT的作者们(像是来宣传文章的),AKDT文章链接(VISAPP 2025):https://www.scitepress.org/Papers/2025/131577/131577.pdf,论文精读:【图像去噪】论文精读:AKDT: Adaptive Kernel Dilation Transformer for Effective Image Denoising,论文复现:【图像去噪】论文复现:新型Transformer块!可学习扩张卷积用于噪声估计引导多头自注意力!AKDT的Pytorch源码复现,跑通源码,获得去噪结果和评价指标,网络结构实现详解,并计算模型复杂度!;
主要ideas和架构
由于计算效率和模型复杂度不影响成绩,混合架构是采用最多的,前3名的架构结合了基于Transformer和基于CNN的网络。
由于可以使用额外的训练集,对于训练数据的选择以及相关Tricks是第1名团队的做法,只选择高质量数据训练,而不是对整个 DIV2K 和 LSDIR 数据集进行训练。
架构设计:第2名使用MambaIRv2的混合结构。
训练技巧:使用小波变换损失、渐进式学习策略。
推理技巧:高百分比patch重叠可以导致更高的PSNR、使用自集成或模型集成。
各团队的具体方法
第1名:惊为天人的200万张自制训练集
Title: Dynamic detail-enhanced image denoising framework
PSNR/SSIM:31.20/0.8884
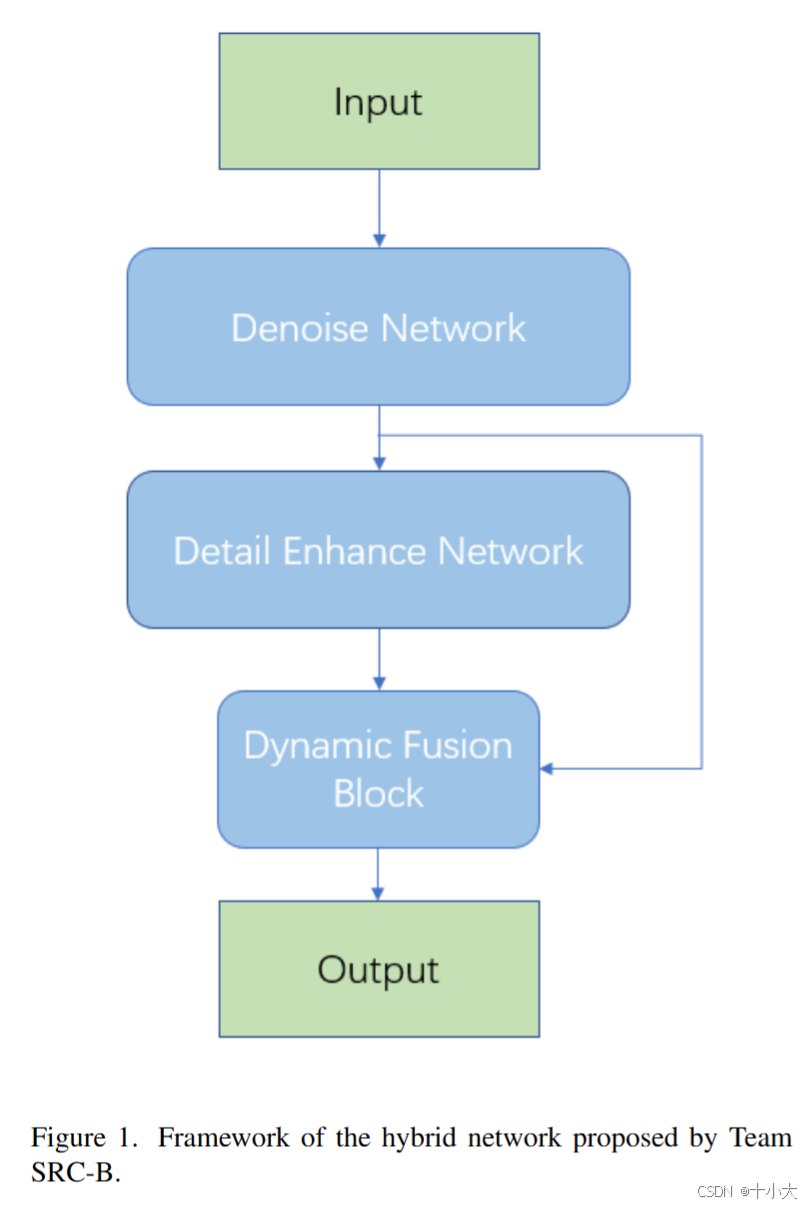
- 混合结构:CNN擅长恢复局部细节,Transformer擅长捕获全局上下文,又不用考虑计算效率和复杂度,于是提出混合网络 —— Restormer+NAFNet,前者为去噪网络,后者为细节增强网络,最后通过一组可学习的参数动态融合上述两个部分的特征,平衡去噪和细节保留,从而提升整体性能。
- 数据集:除了DIV2K和LSDIR外,有200 万张图像组成的自收集自定义数据集,在微调阶段使用高质量数据集( LSDIR 的 1000 张图像、来自自定义数据集的 1000 张图像和来自 DIV2K 的所有 800 张图像)。数据选择如下:
- 图像分辨率:只保留分辨率大于900x900的图像;
- 图像质量:只保留所有三个指标排名前30%的图像:拉普拉斯Var、BRISQUE和NIQE;
- 语义选择:为了实现语义平衡,他们于 Clip 特征进行了语义选择,以确保数据集反映了各种场景类别的多样性和代表性内容。
- 训练策略:包含三个阶段
- 第一阶段,使用200 万张图像的自定义数据集预训练整个网络,学习率1e-4;
- 第二阶段,使用DIV2K 和 LSDIR 数据集微调细节增强网络模块,学习率1e-5;
- 第三阶段,从自定义数据集中选择 1,000 张图像、LSDIR 数据中的 1,000 张图像和 DIV2K 中的 800 张图像作为训练集,学习率1e-6;
- 损失函数:交替迭代L1损失、L2损失和平稳小波变换(SWT)损失;
- 渐进式学习:图像块大小从 256 增加到 448 和 768。
PS:人家都是在DIV2K和LSDIR上训练,你上来就200万张自制数据集,这玩个蛋啊。
第2名:堆叠模型到设备爆显存的临界点
Title: Deep ensemble for Image denoising
PSNR/SSIM:29.95/0.8676
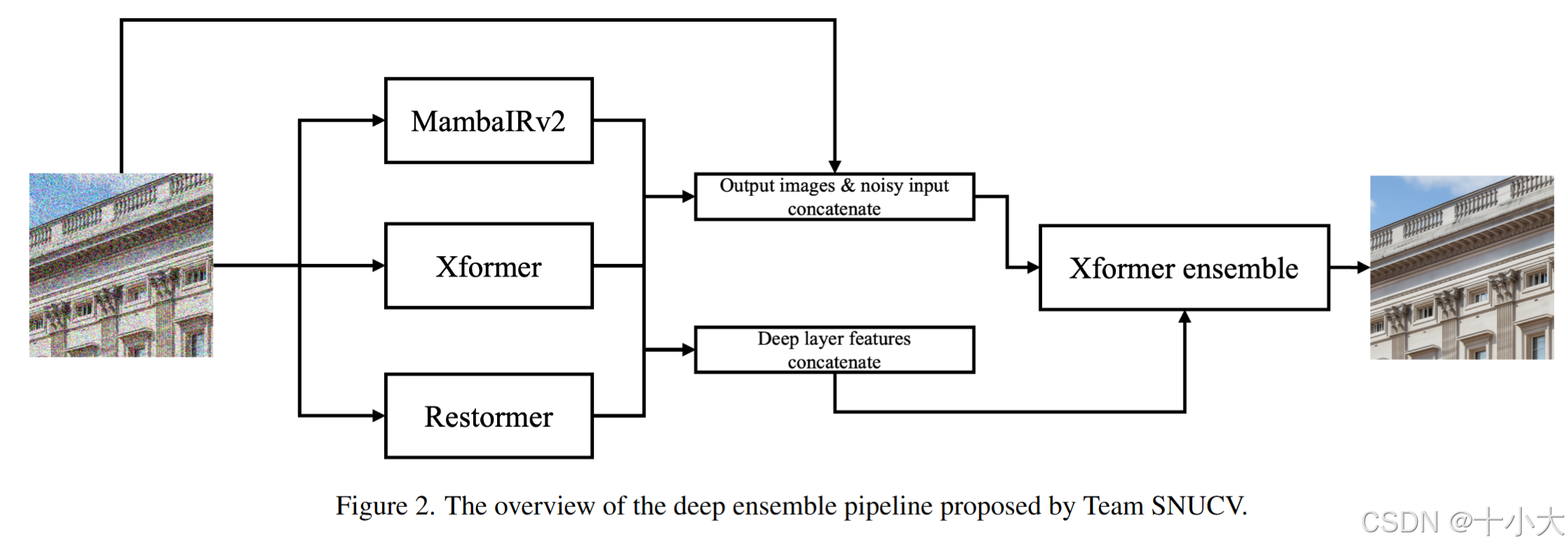
-
混合结构:MambaIRv2+Xformer+Restormer,最后基于Xformer集成。
-
训练细节:与 训练 MambaIRv2、 Restormer 和 Xformer的策略一致,渐进式训练,补丁大小逐渐增加为 [128, 160, 192, 256, 320, 384],对应的批量大小为 [8, 5, 4, 2, 1, 1]。
- 损失函数:去噪模型使用 L1 损失进行训练,而集成模型使用 L1 损失、MSE 损失和高频损失的组合进行训练。
-
推理细节:使用自集成,滑动窗口重叠计算,补丁大小设置为 [256, 384, 512],对应的重叠值为 [48, 64, 96],对结果平均。
PS:不限制计算效率和模型复杂度,第2名的思路才比较常规,不在数据上下功夫,而在于模型设计。
第3名:边缘特征或许是决胜的关键
Title: DDU——Image Denoising Unit using transformer and morphology method
PSNR/SSIM:29.89/0.8664
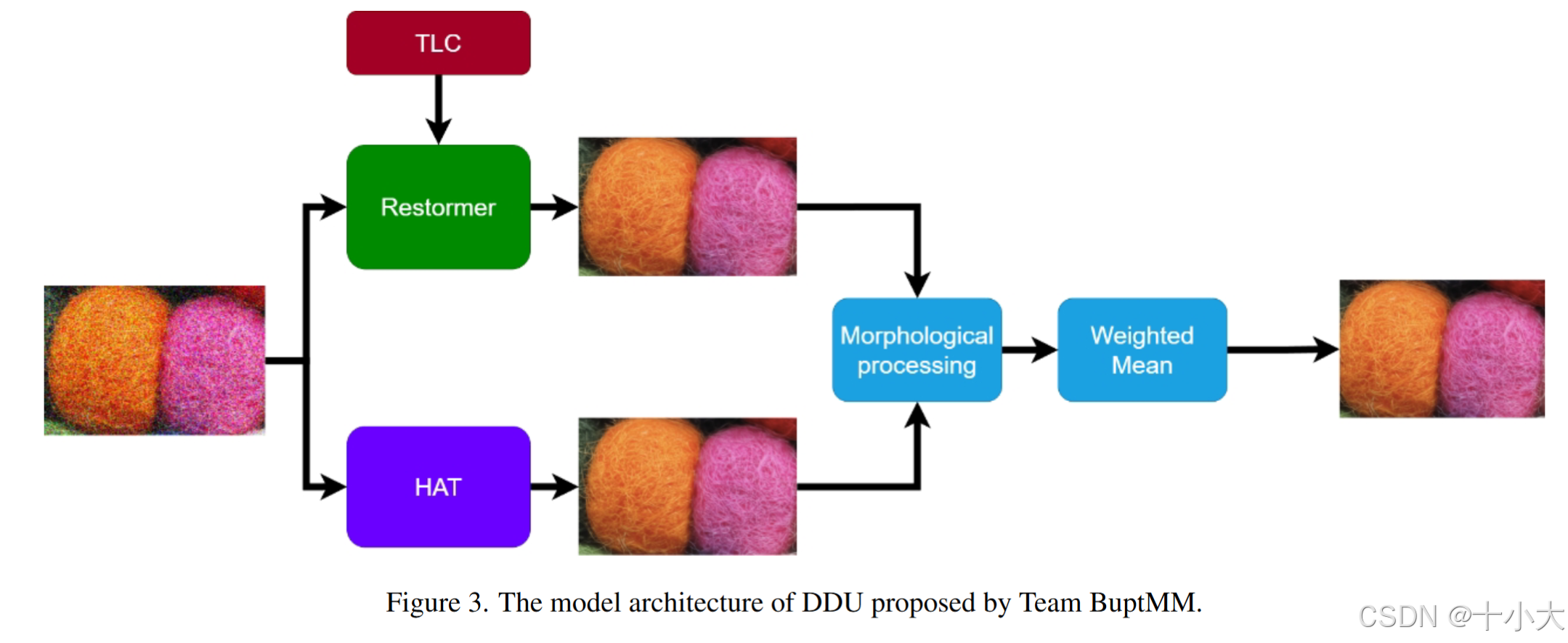
- 混合结构: Restormer+HAT,分为两个阶段,第一阶段使用TLC增强Restormer能力,第二阶段使用Canny算子对两个模型处理的图像进行边缘检测,对两个边缘图像进行OR运算,然后将结果与HAT的边缘进行异或运算,得到两幅图像之间的边缘差。对于边缘差异的这一部分,他们使用HAT[11]获得的结果作为保存的标准,最后取二者的像素平均值为最终结果。
- 训练策略:Restormer和HAT都使用渐进式训练策略。
PS:也是全局和局部特征融合的思路,额外的处理提升性能。
第4名:线性结构在竞赛中焕发的第二春
Title: Hybrid Denosing Method Based on HAT
PSNR/SSIM:29.84/0.8653
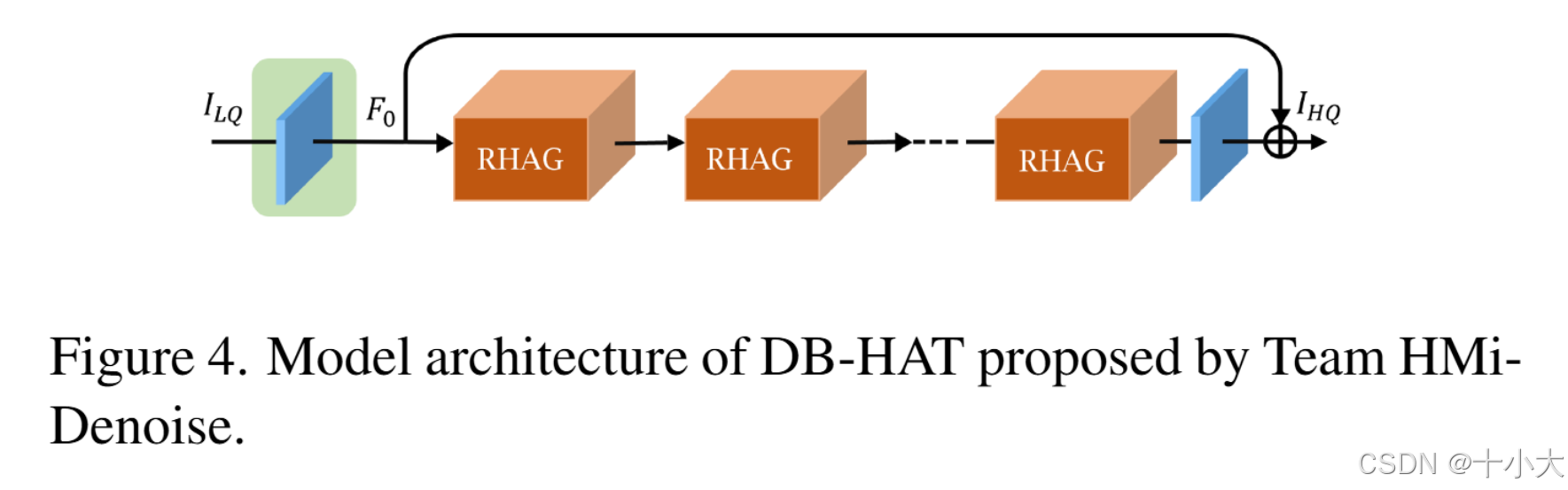
- 模型结构:HAT改进为DB-HAT,常规三部分线性结构,即浅层特征提取3×3Conv,深层特征提取若干个块,重建层为3×3Conv +上采样(如果超分就是n倍上采样,去噪省略上采样)。
- 训练策略:先在小patch(64x64)上以大batch(16)训练,然后在小batch(1)中patch (128x128)上训练,最后在小batch(1)大patch(224x224)上优化。使用余弦退火策略衰减学习率,损失函数为L2损失。
PS:HAT还是牛逼。
第5名:Restormer永远的神
Title: Denoiser using Restormer and Hard Dataset Mining
PSNR/SSIM:29.83/0.8652
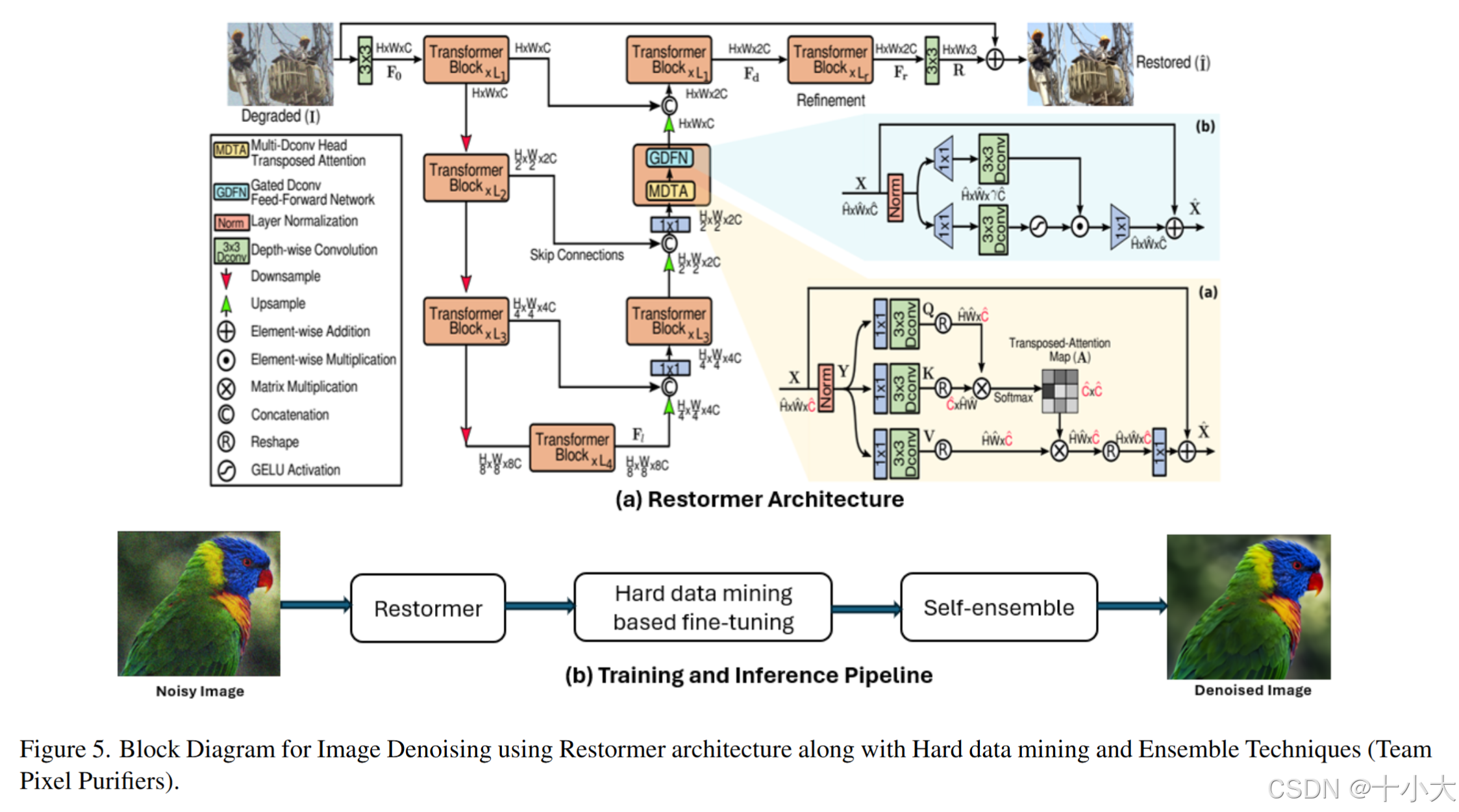
- 核心思路:
- Hard Dataset Mining微调模型:选择损失值超过预定义阈值的训练补丁在我们的基础训练模型上进行迁移学习,学习率比初始学习率降低100倍;
- 数据集配比:DIV2K 与 LSDIR 比率 12:88 有助于提高整体 PSNR;
- 自集成:使用Self Ensemble有效提升性能;
PS:Hard Dataset Mining来自论文Alternating between canonical and hard datasets for improved image demosaicing。
第6名:阐明模型参数和复杂度是我最后的倔强
Title: Bias-Tuning Enables Efficient Image Denoising
PSNR/SSIM:29.80/0.8642
核心思想:偏差调优。
Baseline为未Clipping的预训练Restormer,DIV2K 验证的 PSNR/SSIM为 27.47/0.79,将此冻结恢复器(LayerNorm 模块除外)嵌入可学习的偏差参数并微调模型后,PSNR 增加了 3dB 以上。
推理过程使用自集成和补丁拼接(将测试块使用AutoStitch拼成与训练图像大小的相同的图像,重叠区域使用线性融合)。
复杂性:参数总数:26.25M;可学习偏差参数的总数:0.014M;FLOPS:140.99G(在形状为 256 × 256 × 3 的图像上进行评估)。
第7名:xxIR+xxIR=xxxxIR
Title: Tcler Denoising
PSNR/SSIM:29.78/0.8632
核心思路:PromptIR-Dn50+MambaIRv2-Dn50+融合。
训练细节:与Restormer训练策略相同,损失函数为Charbonnier 损失和梯度加权 L1 损失。
在测试阶段,输入大小固定为112×112,并应用自集成技术来进一步提高模型的性能。
PS:由于未给结构图无法得知具体细节。
第8名:Pureformer = SCUNet+Restormer
Title: Pureformer: Transformer-Based Image Denoising
PSNR/SSIM:29.64/0.8601
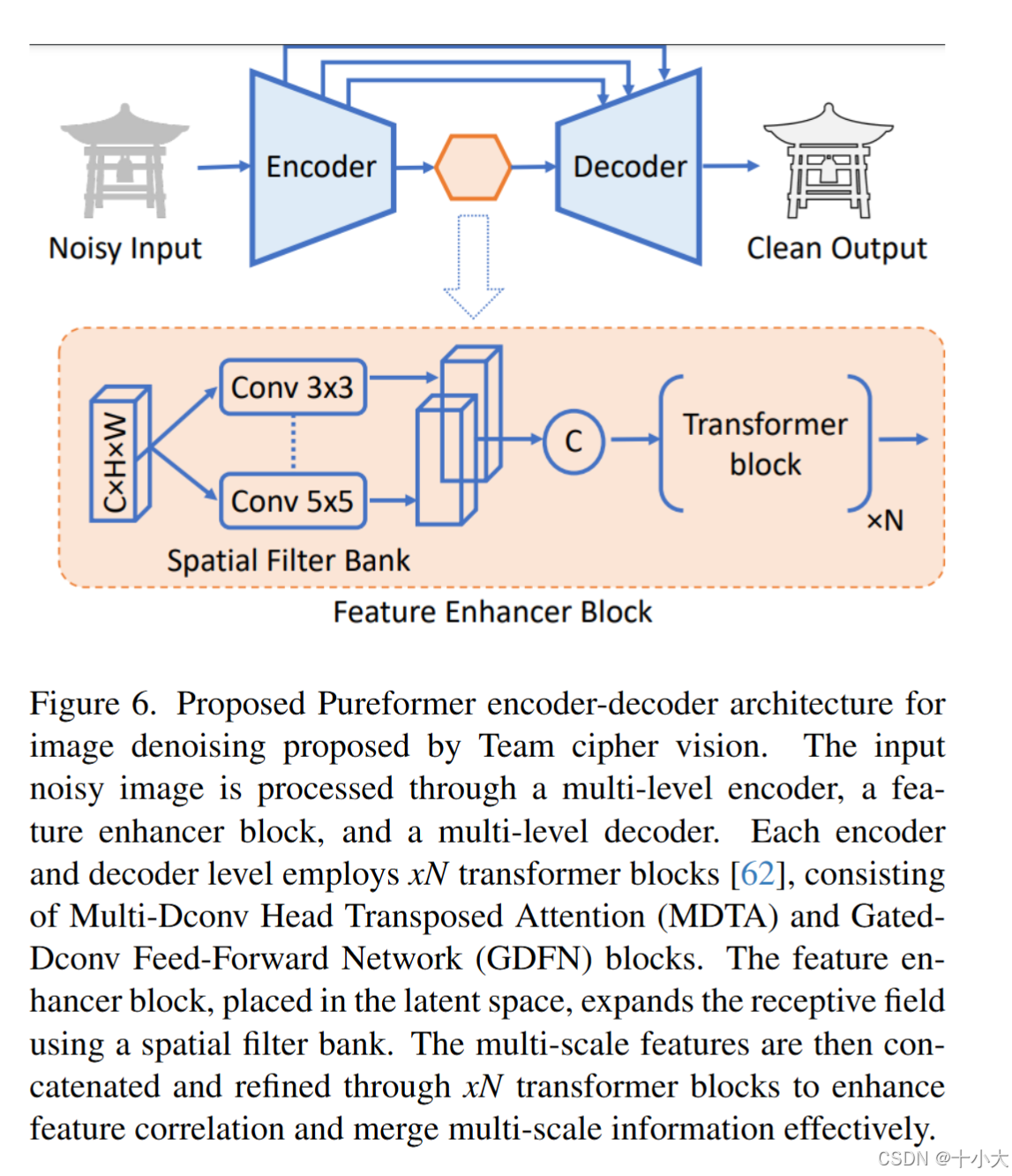
- 网络结构: 四级encoder-decoder结构,Trans块结合了SCUNet和Restormer的Trans块。
- 训练策略: 前15个epoch预热,然后余弦退火;
- 推理策略: 图像块大小为512×512,自集成;
第9名:应该是一篇已经成熟的论文
Title: A Two-Stage Denoising Framework with Generalized Denoising Score Matching Pretraining and Supervised Fine-tuning
PSNR/SSIM:29.61/0.8602

- 框架结构: 自监督GDSM预训练(来自Corruption2Self (C2S))+监督微调;
文章为:Score-based selfsupervised MRI denoising
第10名:换个题目重画个图就拿了第10
Title: HNNFormer: Hierarchical Noise-Deinterlace Transformer for Image Denoising
PSNR/SSIM:29.60/0.8602
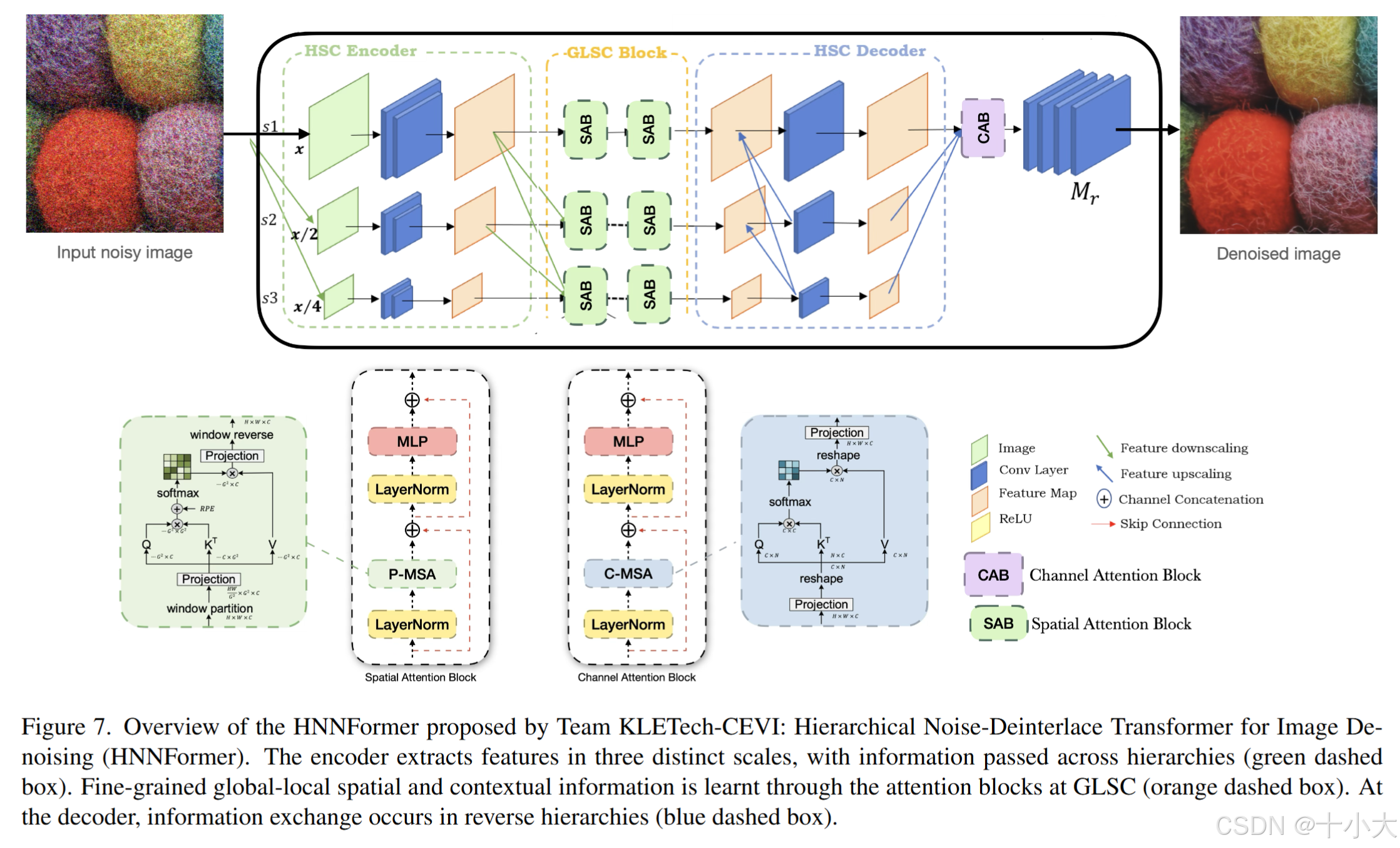
CVPRW2024原作者团队:HNN: Hierarchical Noise-Deinterlace Net Towards Image Denoising
第11名:简简单单SCUNet第11名
Title: SCUNet for image denoising
PSNR/SSIM:29.58/0.8597
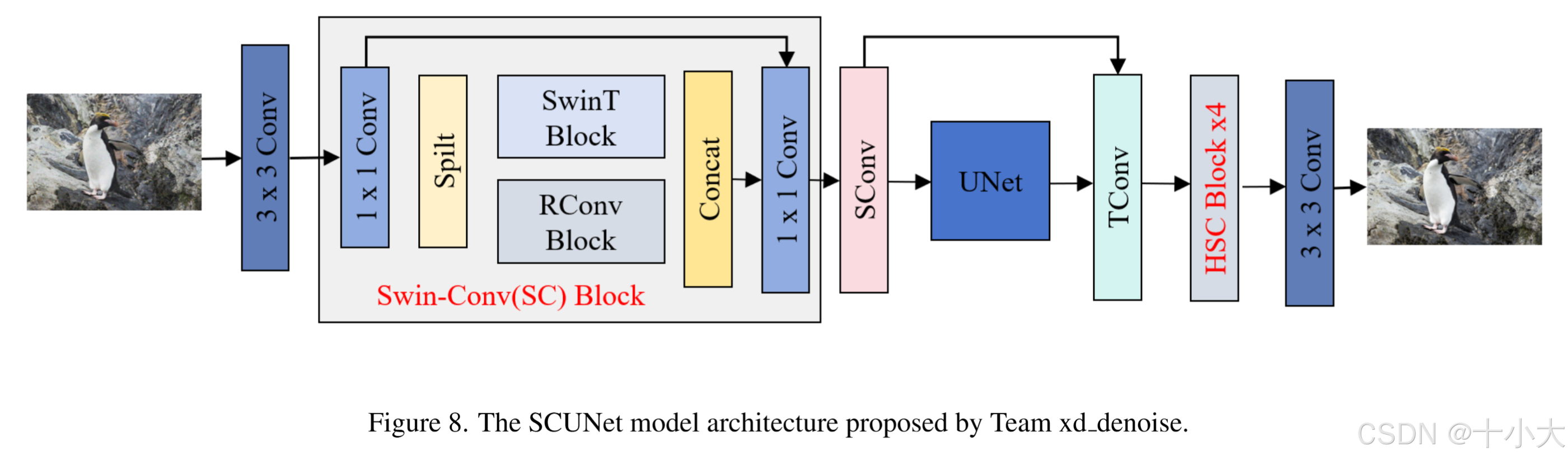
- 网络结构:与SCUNet完全一致。
- 测试策略:使用Test-Time Augmentation(TTA),连接3个U-Net和SCUNet,根据权重0.6和0.4的分配获得输出,最后concat提升性能。
第12名:超分模型也来凑热闹
Title: Image Denoising using NAFNet and RCAN
PSNR/SSIM:29.55/0.8590
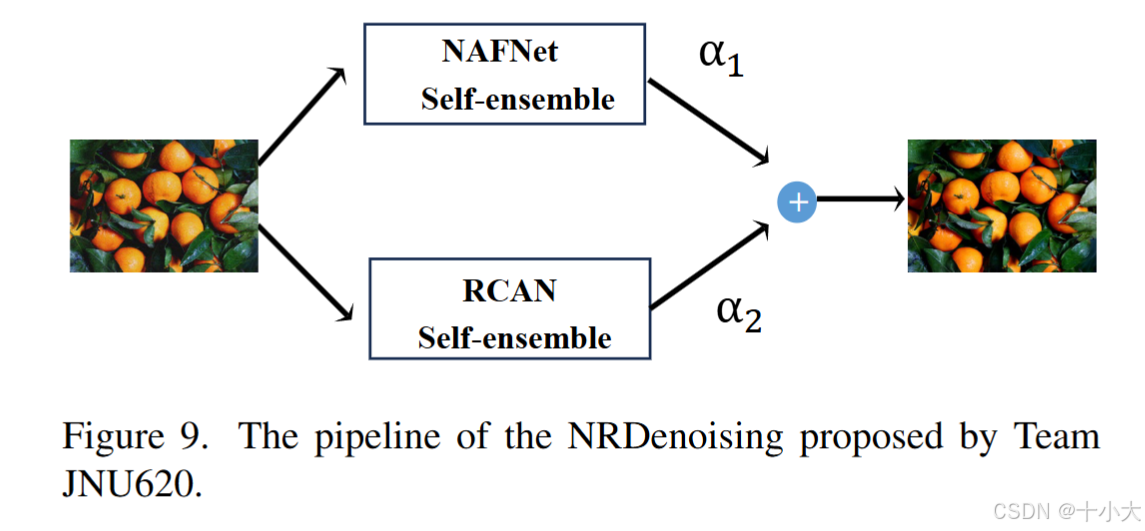
- 网络结构:依旧是多分支特征融合思路,NAFNet+RCAN。
- 训练策略:DIV2K训练NAFNet和RCAN,NAFNet补丁大小为 384×384,RCAN补丁大小为200×200,都是常规参数。
- 推理策略:和第3名一样,使用TLC增强NAFNet性能,自集成。
第13名:Diffusion来了,但我才是第12名
Title: OptimalDiff: High-Fidelity Image Enhancement Using Schr ̈odinger Bridge Diffusion and Multi-Scale Adversarial Refinement
PSNR/SSIM:29.55/0.8598
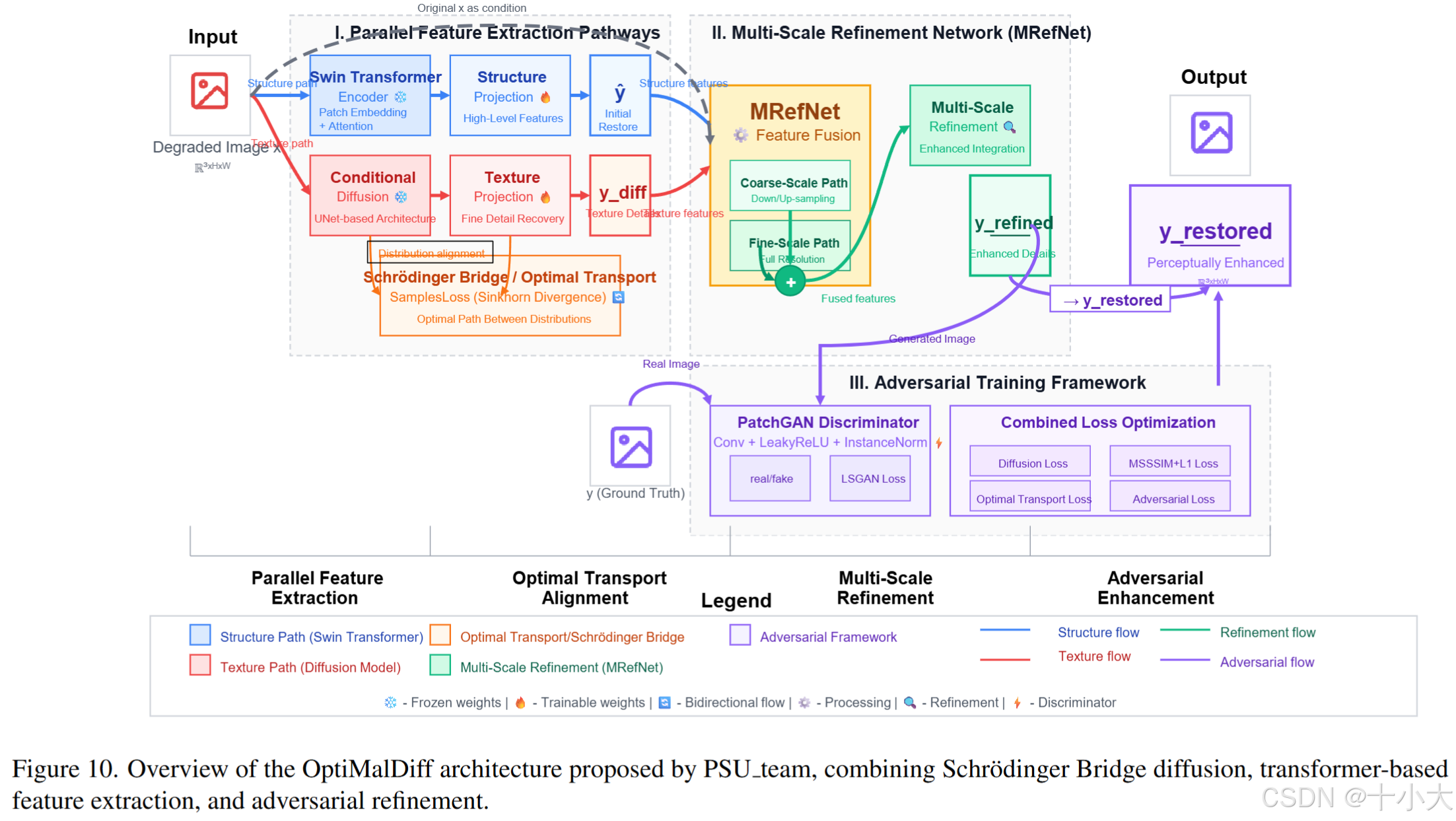
- OptimalDiff架构:1)Swin Transformer 主干;2)Schr ̈odinger Bridge Diffusion;3)多尺度细化网络(MRefNet)。
- 训练策略:复合损失函数联合优化,包括扩散损失、基于Sinkhorn的最优传输损失、多尺度SSIM和L1损失以及对抗性损失。
PS:已经成熟的工作,或者在投的文章,边打比赛边科研。
第14名:GAN也有春天
Title: GAN + NAFNet: A Powerful Combination for High-Quality Image Denoising
PSNR/SSIM:29.51/0.86058
-
模型架构:GAN+NAFNet,激活函数使用SiLU。
-
损失函数:L1、L2 和 Sobel 损失函数联合优化。
-
推理阶段:TLC+自集成。
PS:没有结构图,全凭想象。
第15名:虽竞赛但论文
Title: Enhanced Blind Image Restoration with Channel Attention Transformers and Multi-Scale Attention Prompt Learning
PSNR/SSIM:29.30/0.8499
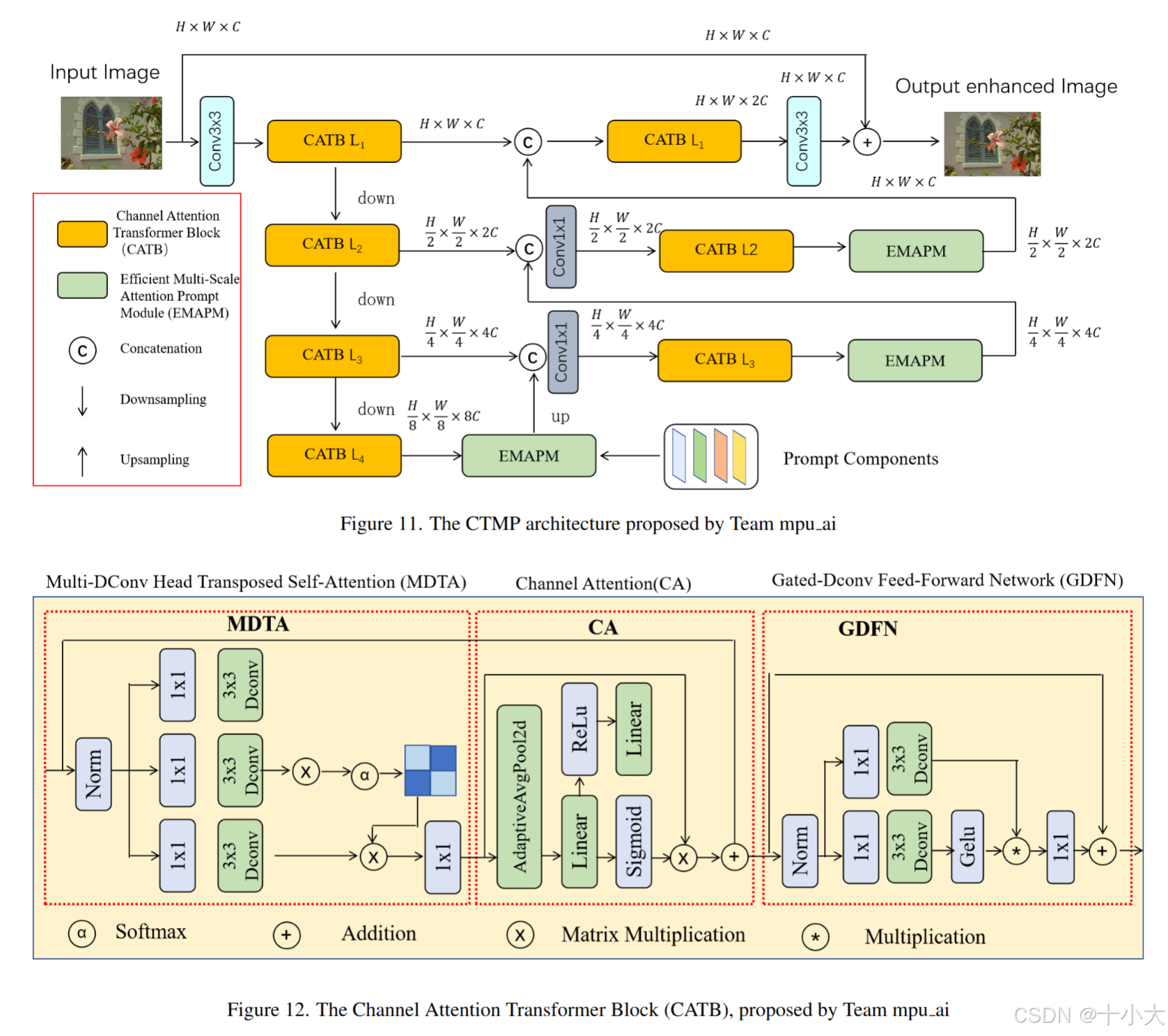
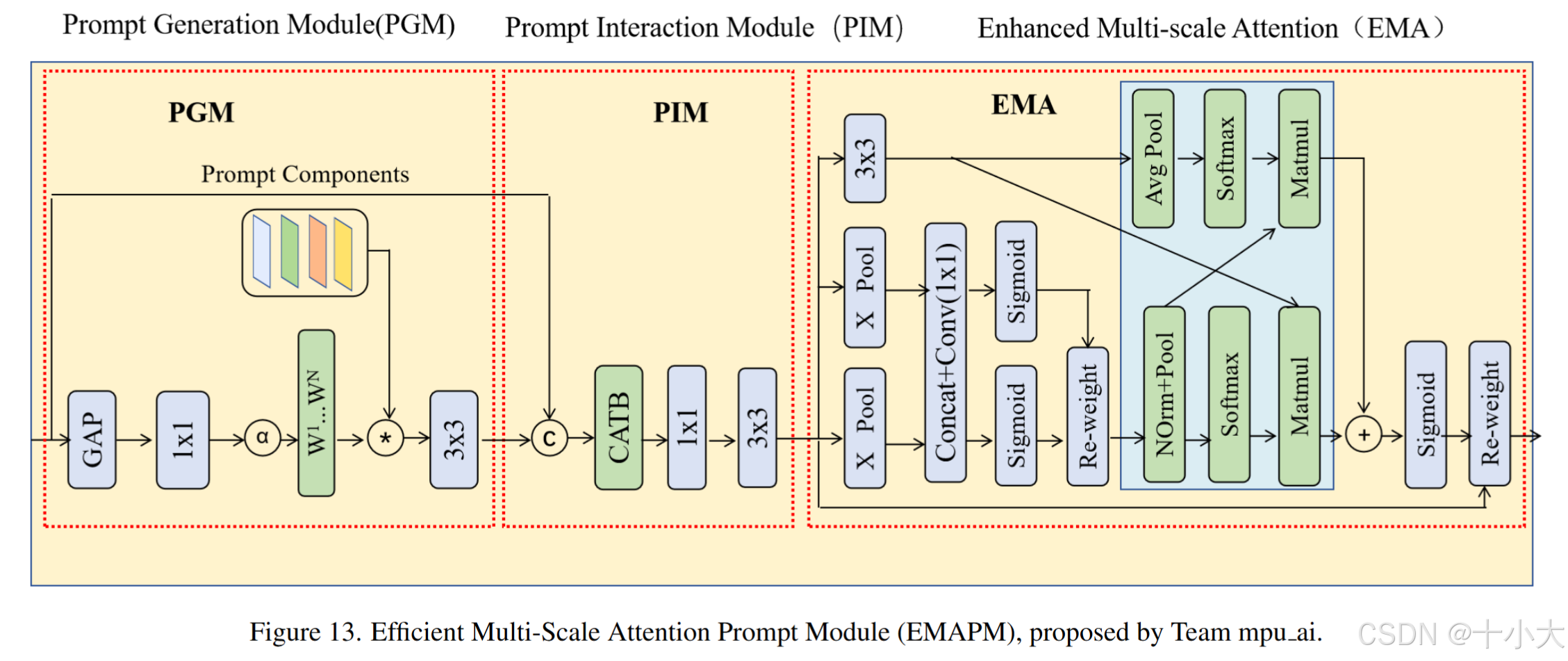
强烈推荐看4.15这段的描述。
PS:事实证明,模型越复杂性能不一定越好,但改进的模块一定适合发论文。
第16名:走错赛道了?
Title: Towards two-stage OptDenoiser framework for image denoising
PSNR/SSIM:28.95/0.8422
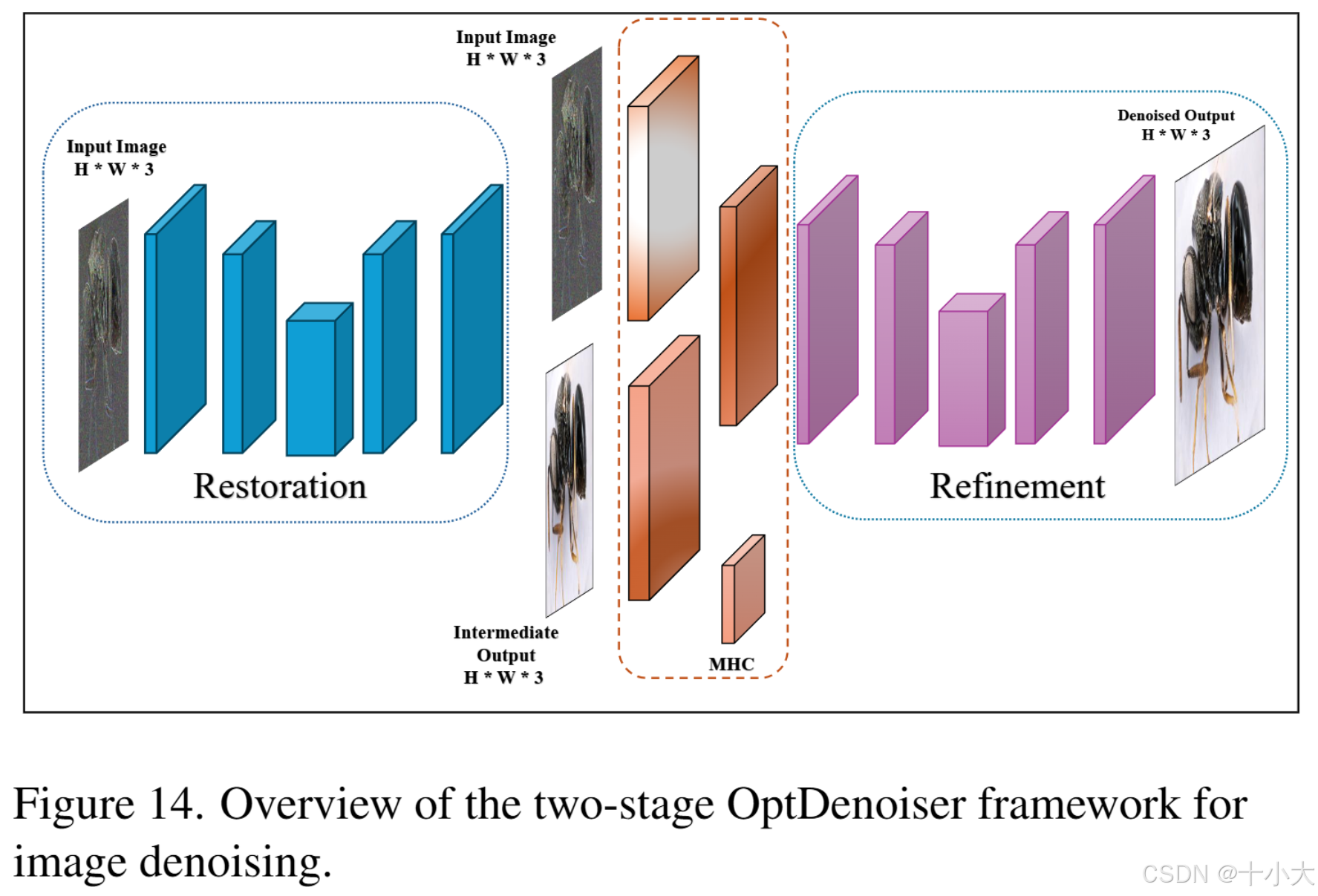
- 网络结构:二阶段网络,恢复+优化。第一阶段为Retinexformer,但有锯齿状的边缘、模糊的输出和捕获和表示噪声输入中复杂结构的困难,为了解决上述问题引入MHC,最后添加一个额外的encoder-decoder块。
- 损失函数:将感知损失函数与亮度色度引导相结合,以减轻颜色不一致,确保视觉上连贯和感知细化的重建。
PS:Retinex理论是低光增强领域的基石,Retinexformer是著名的低光增强模型。用来做去噪还得解决色彩和亮度问题。
第17名:结构图我都不用重新画!
Title: High-resolution Image Denoising via Adaptive Kernel Dilation Transformer
PSNR/SSIM:28.83/0.8374
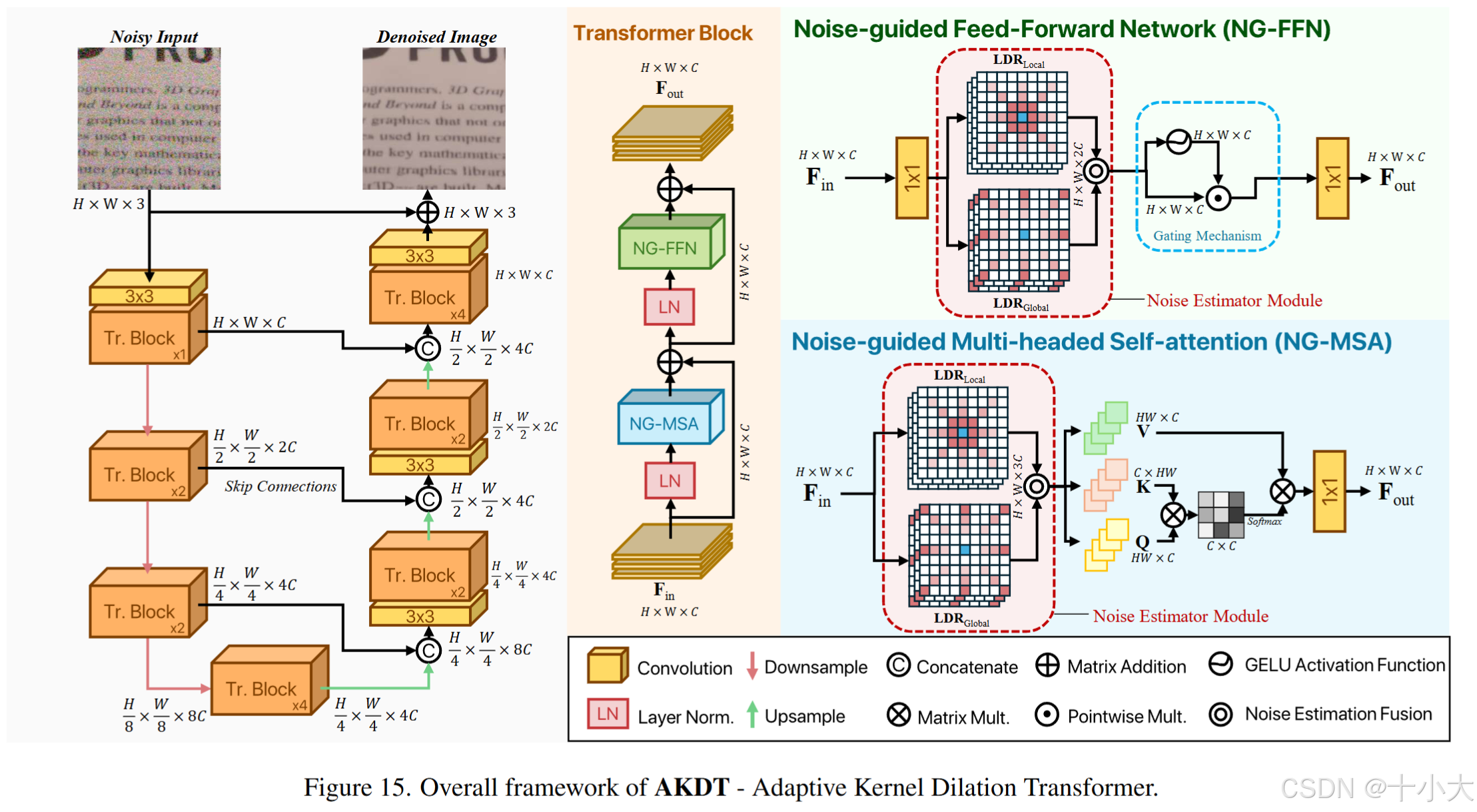
ADKT不过多赘述了,详细的论文精读和复现见如下文章:
- (VISAPP 2025)【图像去噪】论文精读:AKDT: Adaptive Kernel Dilation Transformer for Effective Image Denoising
- (VISAPP 2025)【图像去噪】论文复现:新型Transformer块!可学习扩张卷积用于噪声估计引导多头自注意力!AKDT的Pytorch源码复现,跑通源码,获得去噪结果和评价指标,网络结构实现详解,并计算模型复杂度!
PS:和15一样,模型越复杂性能不一定越好,但改进的模块一定适合发论文。真实世界去噪效果好的模型不一定在AWGN上效果好。
第18名:Xformer+SwinIR < NAFNet+RCAN
Title: MixEnsemble
PSNR/SSIM:26.85/0.7836
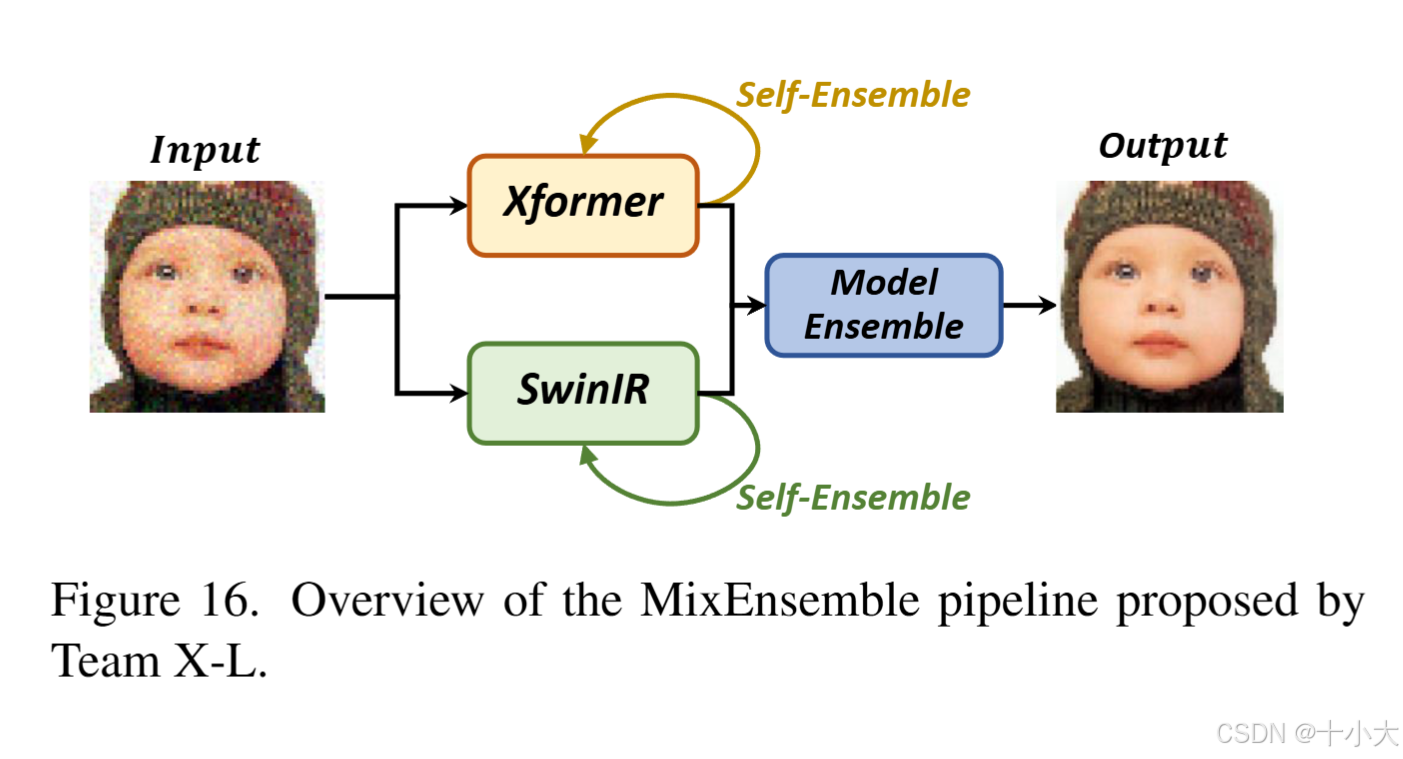
PS:不应该和第12的NAFNet+RCAN指标差这么多啊。
第19名:一次难得的Diffusion实战机会
Title: Diffusion-based Denoising Model
PSNR/SSIM:26.83/0.8010

主干为NAFNet(或 UNet), 基于Refusion: Enabling large-size realistic image restoration with latent-space diffusion models.
第20名:只用UNet是我最后的倔强
Title: High-resolution Image Denoising via Unet neural network
PSNR/SSIM:24.92/0.6972
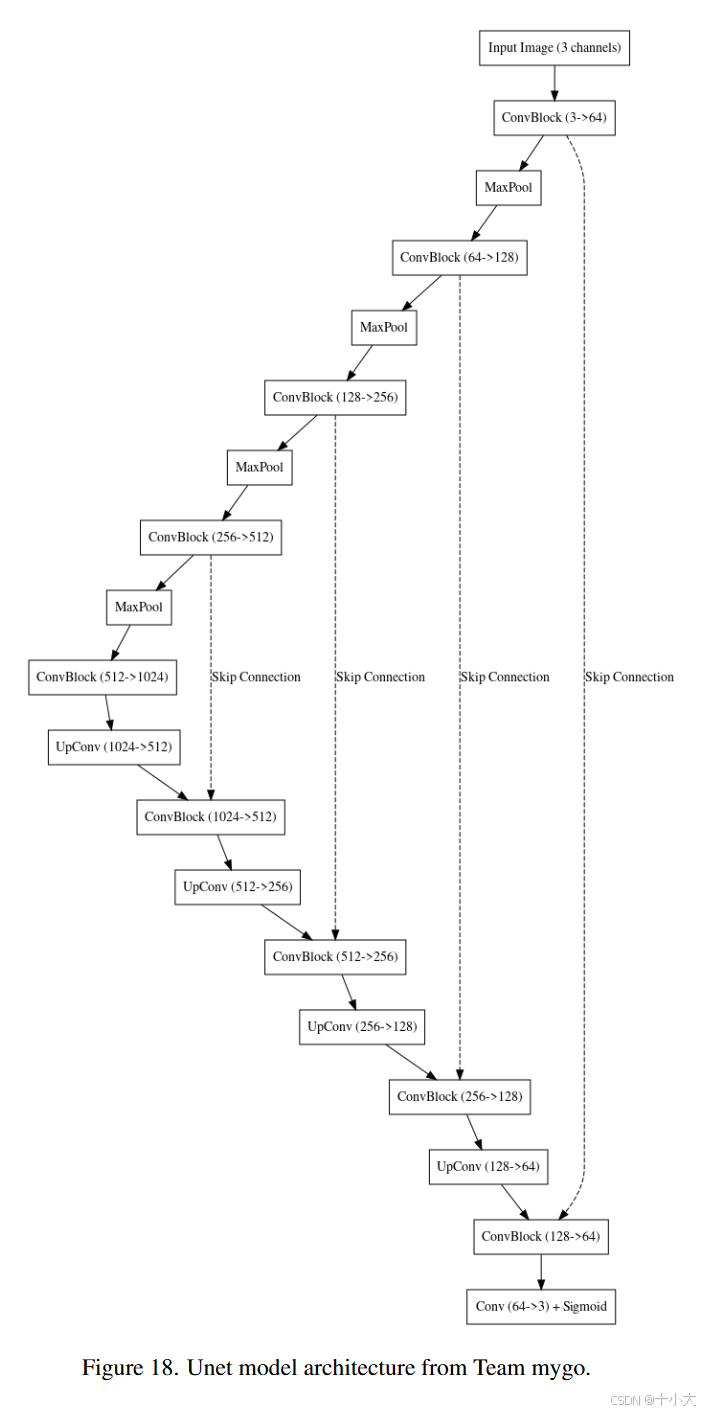
总结与思考
- 主流思路:混合模型多分支SOTA模型输出融合;
- SOTA模型使用统计(Restormer还是太全面了):
| Restormer | NAFNet | Xformer | MambaIRv2 | PromptIR | HAT | Swin | SCUNet | RCAN | GAN | Diffusion | 其他 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 团队序号 | 1,2,3,5,6,8,15,17 | 1,12,14 | 2,18 | 2,7 | 7 | 3,4 | 13,18 | 8,11 | 12 | 14 | 13,19 | 9(自监督+监督),10(HNN),16(Retinexformer),20(UNet) |
| 占比 | 40% | 15% | 10% | 10% | 5% | 10% | 10% | 10% | 5% | 5% | 10% | 20% |
- 训练策略:主流为渐进式学习,退火余弦;
- 推理策略:自集成,重叠块,TLC(3,12,14);
- 常用的有效涨点方式:多分支融合(竞赛多分支模型,论文多分支模块),自集成(Model,Model+);
- 模型越复杂性能不一定越好,真实世界去噪效果好的模型不一定在AWGN上效果好;
- Diffusion不适合竞赛,本身偏向无监督,肯定没有监督模型性能好;
- 给研究生们的启发1:模块排列组合是有效果的,也不用担心和其他人雷同;
- 给研究生们的启发2:多看看其他领域的方法,底层视觉基本通用;
- 给研究生们的启发3:数据、模型、训练、推理四个阶段都可以创新,不一定非得盯着模型,改完不work是正常现象;
- 特殊疑问:没太理解“补丁拼接(将测试块使用AutoStitch拼成与训练图像大小的相同的图像,重叠区域使用线性融合)"为什么会涨点,虽然测试集切块都是按顺序按相同重叠区域裁剪的,但如果改变步长,重叠区域又恰好视差较大,使用AutoStitch拼接会产生伪影,可能是总体上性能提升?
相关专栏
Restormer、NAFNet等去噪方法的论文精读和复现见专栏:【图像去噪(Image Denoising)】关于【图像去噪】专栏的相关说明,包含适配人群、专栏简介、专栏亮点、阅读方法、定价理由、品质承诺、关于更新、去噪概述、文章目录、资料汇总、问题汇总(更新中)
HAT、RCAN等超分方法的论文精读和复现见专栏:【超分辨率(Super-Resolution)】关于【超分辨率重建】专栏的相关说明,包含专栏简介、专栏亮点、适配人群、相关说明、阅读顺序、超分理解、实现流程、研究方向、论文代码数据集汇总等
与我联系
图像去噪交流群(QQ):1037809432
VX:shixiaodayyds(可加微信交流群,注明来意)
至此本文结束。
如果本文对你有所帮助,请点赞收藏,创作不易,感谢您的支持!
点击下方👇公众号区域,扫码关注,可免费领取一份200+即插即用模块资料!


















 105
105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











