









KGGen,一种利用语言模型和聚类算法从文本中提取高质量KG的开源Python库。通过MINE基准测试,证明了KGGen在生成功能性KG方面的潜力,其性能比现有方法提高了18%。未来的研究方向包括改进聚类方法和扩展基准测试以处理更大规模的语料库
技术创新:
1 多阶段处理架构
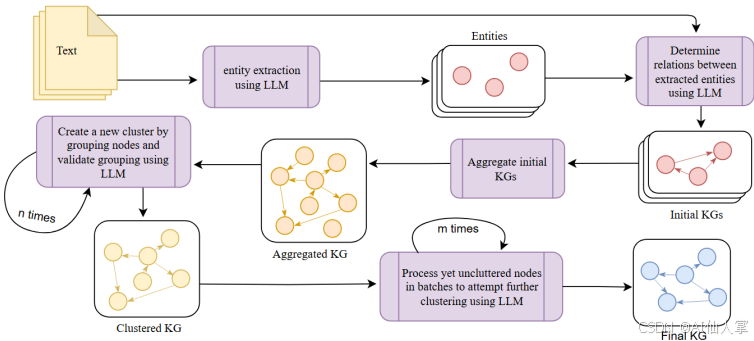
1.1实体和关系提取:
首先,使用GPT-4o模型从输入文本中提取实体和关系。这一步骤通过两个独立的LLM调用来实现,以确保实体之间的一致性。
1.2聚合:
将提取的实体和关系聚合到一个单一的图中,减少冗余。这一步骤不需要LLM参与。
1.3实体和边聚类:
对提取的实体和边进行迭代聚类,以合并表示相同真实世界实体或概念的节点和边。聚类过程通过多个LLM调用来实现,逐步合并相似实体和边,直到无法进一步合并。
具体步骤如下:
- 初始聚类尝试:将所有实体列表传递给LLM,尝试提取一个聚类。可以使用一个可选的聚类指令字符串来指导聚类过程。
- 验证聚类:使用LLM判断聚类的有效性,如果通过则添加到聚类中,并从实体列表中移除这些实体。
- 分配标签:为聚类分配一个标签,以捕捉聚类中实体的共享意义。
- 迭代聚类:重复上述步骤,直到n次循环后仍未成功提取聚类。
- 批量检查:对剩余的实体进行批量检查,决定是否将其添加到现有聚类中。每次添加新实体时,再次使用LLM验证聚类的有效性。
- 最终验证:重复步骤5,直到没有剩余实体需要检查。
对边的聚类操作类似,但提示略有不同。
这种模块化设计不仅提高了系统的可维护性,还确保了每个阶段的输出质量和一致性。
2 实体提取机制
DSPy框架:通过定义TextEntities和ConversationEntities签名类,分别处理普通文本和对话文本中的实体提取。
严格的错误处理机制:确保API调用失败时能够优雅降级,提高系统的稳定性和可靠性。
3 关系抽取策略
主谓宾三元组:使用TextRelations和ConversationRelations签名类,确保关系的主语和宾语都来自之前提取的实体集合,防止“悬空”关系的出现。
4 创新的聚类算法
渐进式聚类:模拟人类专家逐步达成共识的过程,通过多次迭代和验证,合并相似的实体和关系。
优势:
• 处理语言变化(如时态、单复数)。
• 识别同义词和近义词。
• 确保合并后的实体和关系保持语义一致性。
实验设计
论文提出了衡量文本到KG提取性能的第一个基准测试——信息节点和边度量(MINE)。具体设计如下:
数据收集:
从维基百科生成100篇长度约为1000字的文章,每篇文章基于100个不同主题生成,涵盖历史、艺术、科学、伦理和心理等领域。
评估指标:
通过提取每篇文章中的15个事实来评估生成的KG的质量。使用all-MiniLM-L6-v2模型将这些节点向量化,并通过余弦相似度评估短句子信息与图中节点的语义相似性。
查询和评估:
对每篇文章生成的KG进行查询,确定与查询事实最相似的top-k节点,然后在其邻域内查找所有节点,最后返回这些节点及其关系。使用LLM判断查询事实是否可以从查询的节点和关系中推断出来,结果为1表示可以推断出来,为0表示不可以。
结果与分析
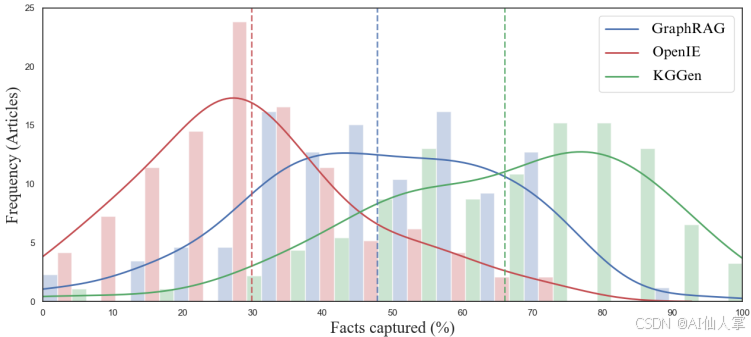
定量结果:
在MINE基准测试中,KGGen的平均得分为66.07%,显著优于GraphRAG的47.80%和OpenIE的29.84%。
定性结果:
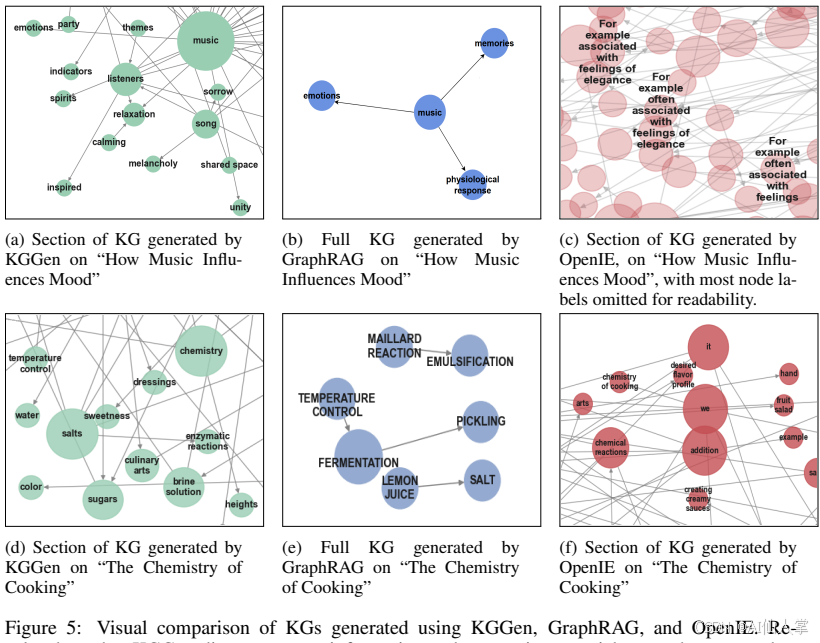
KGGen生成的KG密集且连贯,能够有效捕捉关键关系和信息的例子。相比之下,GraphRAG生成的KG节点和连接数量较少,导致关键信息被遗漏;OpenIE生成的KG节点冗长且不连贯,包含大量无用的通用节点。
主要用途
- 辅助RAG:创建图谱以辅助检索增强生成(Retrieval-Augmented Generation)。
- 生成合成数据:为模型训练和测试创建图结构的合成数据。
- 文本结构化:将任何文本结构化为图谱。
- 关系分析:分析源文本中概念之间的关系。
代码走读
关系抽取 steps/_2_get_relations.py
##
from typing import List
import dspy
# 定义TextRelations类,继承自dspy.Signature,用于从文本中提取关系
class TextRelations(dspy.Signature):
"""
从源文本中提取主谓宾三元组。
主语和宾语必须来自实体列表。实体是之前从相同的源文本中提取的。
这是一个提取任务,请务必全面、准确并忠实于参考文本。
"""
# 源文本,作为输入字段
source_text: str = dspy.InputField()
# 实体列表,作为输入字段
entities: list[str] = dspy.InputField()
# 关系列表,作为输出字段,描述为包含主谓宾元组的列表,其中主语和宾语必须与实体列表中的项精确匹配,要全面
relations: list[tuple[str, str, str]] = dspy.OutputField(desc="List of subject-predicate-object tuples where subject and object are exact matches to items in entities list. BE THOROUGH")
# 定义ConversationRelations类,继承自dspy.Signature,用于从对话中提取关系
class ConversationRelations(dspy.Signature):
"""
从对话中提取主谓宾三元组,包括:
1. 所讨论概念之间的关系
2. 说话者与概念之间的关系(例如,用户询问关于X的问题)
3. 说话者之间的关系(例如,助手回应用户)
主语和宾语必须来自实体列表。实体是之前从相同的源文本中提取的。
这是一个提取任务,请务必全面、准确并忠实于参考文本。
"""
# 源文本,作为输入字段
source_text: str = dspy.InputField()
# 实体列表,作为输入字段
entities: list[str] = dspy.InputField()
# 关系列表,作为输出字段,描述为包含主谓宾元组的列表,其中主语和宾语必须与实体列表中的项精确匹配,要全面
relations: list[tuple[str, str, str]] = dspy.OutputField(desc="List of subject-predicate-object tuples where subject and object are exact matches to items in entities list. BE THOROUGH")
# 定义get_relations函数,用于根据输入数据和实体列表获取关系
def get_relations(dspy: dspy.dspy, input_data: str, entities: list[str], is_conversation: bool = False) -> List[str]:
"""
根据输入数据和实体列表获取关系。
参数:
dspy: dspy实例
input_data: 输入的文本数据
entities: 实体列表
is_conversation: 是否为对话数据,默认为False
返回:
过滤后的关系列表
"""
# 如果是对话数据,使用ConversationRelations进行关系提取
if is_conversation:
extract = dspy.Predict(ConversationRelations)
else:
# 否则,使用TextRelations进行关系提取
extract = dspy.Predict(TextRelations)
# 调用extract方法进行关系提取
result = extract(source_text=input_data, entities=entities)
# 过滤关系,只保留主语和宾语都在实体列表中的关系
filtered_relations = [
(s, p, o) for s, p, o in result.relations
if s in entities and o in entities
]
return filtered_relations
聚类核心代码[steps/_3_cluster_graph.py]
# 此文件主要用于图的聚类相关操作,包含多个类和函数的定义
# 定义 cluster_items 函数,用于对项目进行聚类操作
def cluster_items(dspyi: dspy.dspy, items: set[str], item_type: str = "entities", context: str = "") -> tuple[set[str], dict[str, set[str]]]:
"""
返回项目集合和聚类字典,该字典将代表项目映射到项目集合。
"""
# 组合上下文信息
context = f"{item_type} of a graph extracted from source text." + context
# 复制项目集合,用于后续操作,避免修改原始数据
remaining_items = items.copy()
# 初始化聚类字典
clusters = {}
# 初始化无进展计数
no_progress_count = 0
# 创建 ExtractCluster 的预测器
extract = dspyi.Predict(ExtractCluster)
# 创建 ValidateCluster 的预测器
validate = dspyi.Predict(ValidateCluster)
# 创建 ChooseRepresentative 的预测器
choose_rep = dspyi.Predict(ChooseRepresentative)
# 创建 CheckExistingClusters 的思维链
check_existing = dspyi.ChainOfThought(CheckExistingClusters)
# 当还有剩余项目时进行循环
while len(remaining_items) > 0:
# 使用 extract 预测器获取聚类结果
e_result = extract(items=remaining_items, context=context)
# 获取建议的聚类
suggested_cluster = e_result.cluster
# 如果建议的聚类不为空
if len(suggested_cluster) > 0:
# 使用 validate 预测器验证聚类
v_result = validate(cluster=suggested_cluster, context=context)
# 获取验证后的聚类项目
validated_cluster = v_result.validated_items
# 如果验证后的聚类项目数量大于 1
if len(validated_cluster) > 1:
# 重置无进展计数
no_progress_count = 0
# 使用 choose_rep 预测器选择代表项目
r_result = choose_rep(cluster=validated_cluster, context=context)
# 获取代表项目
representative = r_result.representative
# 将代表项目和验证后的聚类项目存入聚类字典
clusters[representative] = validated_cluster
# 从剩余项目中移除已聚类的项目
remaining_items = {item for item in remaining_items if item not in validated_cluster}
# 继续下一次循环
continue
# 无进展计数加 1
no_progress_count += 1
# 如果无进展计数达到上限或没有剩余项目,则退出循环
if no_progress_count >= LOOP_N or len(remaining_items) == 0:
break
# 如果还有剩余项目
if len(remaining_items) > 0:
# 将剩余项目转换为列表以便批量处理
items_to_process = list(remaining_items)
# 按批次处理剩余项目
for i in range(0, len(items_to_process), BATCH_SIZE):
# 获取当前批次的项目
batch = items_to_process[i:min(i + BATCH_SIZE, len(items_to_process))]
# 如果聚类字典为空
if not clusters:
# 将每个项目作为一个单独的聚类存入聚类字典
for item in batch:
clusters[item] = {item}
# 继续下一次循环
continue
# 使用 check_existing 思维链检查项目所属聚类
c_result = check_existing(
items=batch,
clusters=clusters,
context=context
)
# 获取项目所属的聚类代表列表
cluster_reps = c_result.cluster_reps_that_items_belong_to
# 处理每个项目及其对应的代表
for i, item in enumerate(batch):
# 获取项目对应的代表,如果索引超出范围则为 None
rep = cluster_reps[i] if i < len(cluster_reps) else None
# 如果代表不为空且代表在聚类字典中
if rep is not None and rep in clusters:
# 创建新的聚类,包含原聚类和当前项目
new_cluster = clusters[rep] | {item}
# 使用 validate 预测器验证新的聚类
v_result = validate(cluster=new_cluster, context=context)
# 获取验证后的项目集合
validated_items = v_result.validated_items
# 如果验证后的项目集合数量等于原聚类数量加 1
if len(validated_items) == len(clusters[rep]) + 1:
# 将当前项目添加到原聚类中
clusters[rep].add(item)
else:
# 将当前项目作为一个单独的聚类存入聚类字典
clusters[item] = {item}
else:
# 将当前项目作为一个单独的聚类存入聚类字典
clusters[item] = {item}
# 获取聚类字典的键集合
new_items = set(clusters.keys())
# 返回新的项目集合和聚类字典
return new_items, clusters
# 定义 cluster_graph 函数,用于对图进行聚类操作
def cluster_graph(dspy: dspy.dspy, graph: Graph, context: str = "") -> Graph:
"""
对图中的实体和边进行聚类,并相应地更新关系。
参数:
dspy: DSPy 运行时
graph: 输入的图,包含实体、边和关系
context: 用于聚类的附加上下文字符串
返回:
具有聚类后的实体和边、更新后的关系以及聚类映射的图
"""
# 对图中的实体进行聚类
entities, entity_clusters = cluster_items(dspy, graph.entities, "entities", context)
# 对图中的边进行聚类
edges, edge_clusters = cluster_items(dspy, graph.edges, "edges", context)
# 基于聚类更新关系
relations: set[tuple[str, str, str]] = set()
# 遍历图中的关系
for s, p, o in graph.relations:
# 在实体聚类中查找主语
if s not in entities:
for rep, cluster in entity_clusters.items():
if s in cluster:
s = rep
break
# 在边聚类中查找谓词
if p not in edges:
for rep, cluster in edge_clusters.items():
if p in cluster:
p = rep
break
# 在实体聚类中查找宾语
if o not in entities:
for rep, cluster in entity_clusters.items():
if o in cluster:
o = rep
break
# 将更新后的关系添加到关系集合中
relations.add((s, p, o))
# 返回聚类后的图
return Graph(
entities=entities,
edges=edges,
relations=relations,
entity_clusters=entity_clusters,
edge_clusters=edge_clusters
)
if __name__ == "__main__":
# 引入 os 模块
import os
from ..kg_gen import KGGen
# 定义模型名称
model = "openai/gpt-4o"
# 获取环境变量中的 OPENAI_API_KEY
api_key = os.getenv("OPENAI_API_KEY")
# 如果没有获取到 API 密钥
if not api_key:
# 打印提示信息
print("Please set OPENAI_API_KEY environment variable")
# 退出程序
exit(1)
# 示例:家庭关系
kg_gen = KGGen(
model=model,
temperature=0.0,
api_key=api_key
)
graph = Graph(
entities={
"Linda", "Joshua", "Josh", "Ben", "Andrew", "Judy"
},
edges={
"is mother of", "is brother of", "is father of",
"is sister of", "is nephew of", "is aunt of",
"is same as"
},
relations={
("Linda", "is mother of", "Joshua"),
("Ben", "is brother of", "Josh"),
("Andrew", "is father of", "Josh"),
("Judy", "is sister of", "Andrew"),
("Josh", "is nephew of", "Judy"),
("Judy", "is aunt of", "Josh"),
("Josh", "is same as", "Joshua")
}
)
try:
# 对图进行聚类操作
clustered_graph = kg_gen.cluster(graph=graph)
# 打印聚类后的图
print('Clustered graph:', clustered_graph)
except Exception as e:
# 抛出异常
raise ValueError(e)
快速开始
- 安装模块:
pip install kg-gen - 使用示例:
- 初始化
KGGen:
from kg_gen import KGGen kg = KGGen( model="openai/gpt-4o", # 默认模型 temperature=0.0, # 默认温度 api_key="YOUR_API_KEY" # 如果在环境变量中设置则可选 )- 示例1:处理单字符串输入
text_input = "Linda is Josh's mother. Ben is Josh's brother. Andrew is Josh's father." graph_1 = kg.generate( input_data=text_input, context="Family relationships" )- 示例2:处理大文本,分块并聚类
with open('large_text.txt', 'r') as f: large_text = f.read() graph_2 = kg.generate( input_data=large_text, chunk_size=5000, # 按5000字符分块处理文本 cluster=True # 对相似实体和关系进行聚类 )- 示例3:处理消息数组
messages = [ {"role": "user", "content": "What is the capital of France?"}, {"role": "assistant", "content": "The capital of France is Paris."} ] graph_3 = kg.generate(input_data=messages) - 初始化



















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











