







转载自:http://m.blog.csdn.net/u011771047/article/details/72777349
图像分割也是一项有意思的研究领域,它的目的是把图像中各种不同物体给用不同颜色分割出来,如下图所示,其平均精度(mIoU,即预测区域和实际区域交集除以预测区域和实际区域的并集),也从最开始的FCN模型(图像语义分割全连接网络,该论文获得计算机视觉顶会CVPR2015的最佳论文的)的62.2%,到DeepLab框架的72.7%,再到牛津大学的CRF as RNN的74.7%。该领域是一个仍在进展的领域,仍旧有很大的进步空间。

A Review on Deep Learning Techniques Applied to Semantic Segmentation:原文链接
5.1度量标准
为何需要语义分割系统的评价标准?
- 为了衡量分割系统的作用及贡献,其性能需要经过严格评估。并且,评估须使用标准、公认的方法以保证公平性。
- 系统的多个方面需要被测试以评估其有效性,包括:执行时间、内存占用、和精确度。
- 由于系统所处背景及测试目的的不同,某些标准可能要比其他标准更加重要,例如,对于实时系统可以损失精确度以提高运算速度。而对于一种特定的方法,尽量提高所有的度量性能是必须的。
5.1.1 执行时间
速度或运行时间是一个非常有价值的度量,因为大多数系统需要保证推理时间可以满足硬实时的需求。某些情况下,知晓系统的训练时间是非常有用的,但是这通常不是非常明显,除非其特别慢。在某种意义上说,提供方法的确切时间可能不是非常有意义,因为执行时间非常依赖硬件设备及后台实现,致使一些比较是无用的。
然而,出于重用和帮助后继研究人员的目的,提供系统运行的硬件的大致描述及执行时间是有用的。这可以帮助他人评估方法的有效性,及在保证相同环境测试最快的执行方法。
5.1.2 内存占用
内存是分割方法的另一个重要的因素。尽管相比执行时间其限制较松,内存可以较为灵活地获得,但其仍然是一个约束因素。在某些情况下,如片上操作系统及机器人平台,其内存资源相比高性能服务器并不宽裕。即使是加速深度网络的高端图形处理单元(GPU),内存资源也相对有限。以此来看,在运行时间相同的情况下,记录系统运行状态下内存占用的极值和均值是及其有价值的。
5.1.3 精确度
图像分割中通常使用许多标准来衡量算法的精度。这些标准通常是像素精度及IoU的变种,以下我们将会介绍常用的几种逐像素标记的精度标准。为了便于解释,假设如下:共有k+1个类(从L0到Lk,其中包含一个空类或背景),pij表示本属于类i但被预测为类j的像素数量。即,pii表示真正的数量,而pij pji则分别被解释为假正和假负,尽管两者都是假正与假负之和。
- Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。
PA=∑ki=0pii∑ki=0∑kj=0pij - Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
MPA=1k+1∑i=0kpii∑kj=0pij Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和。在每个类上计算IoU,之后平均。
MIoU=1k+1∑i=0kpii∑kj=0pij+∑kj=0pji−piiFrequency Weighted Intersection over Union(FWIoU,频权交并比):为MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。
FWIoU=1∑ki=0∑kj=0pij∑i=0kpii∑kj=0pij+∑kj=0pji−pii
在以上所有的度量标准中,MIoU由于其简洁、代表性强而成为最常用的度量标准,大多数研究人员都使用该标准报告其结果。
直观理解
如下图所示,椭圆A代表真实值,椭圆B代表预测值。橙色部分为A与B的交集,即真正(预测为1,真实值为1)的部分,绿色部分表示假负(预测为0,真实为1)的部分,黄色表示假正(预测为1,真实为0)的部分,两个椭圆之外的白色区域表示真负(预测为0,真实值为0)的部分。表示绿色+橙色+黄色为A与B的并集。
- MP计算橙色与(橙色与黄色)的比例。
- MIoU计算的是计算A与B的交集(橙色部分)与A与B的并集(绿色+橙色+黄色)之间的比例,在理想状态下A与B重合,两者比例为1 。
二、基础知识:
这部分是基础知识,熟悉的可直接跳过
如图所示,集合A:真实值;集合B:预测值。 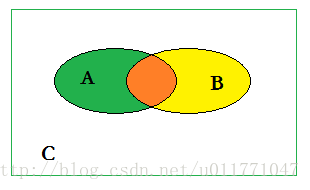
针对预测值和真实值之间的关系,我们可以将样本分为4类:
真正值(TP):预测值为1,真实值为1;橙色,A∩B
真负值(TN):预测值为0,真实值为0;白色,~(A∪B)
假正值(FP):预测值为1,真实值为0;黄色,B-(A∩B)
假负值(FN):预测值为0,真实值为1;绿色,A-(A∩B)
# 为方便记忆,可以这样理解:
# TP:T(预测对了true) P(预测为正样本positive);真的正值,说明被预测为正样本,预测是真的,即真实值为正样本
# TN:T(预测对了true) P(预测为负样本negative);真的负值,说明被预测为负样本,预测是真的,即真实值为负样本
# FP:T(预测错了false)P(预测为正样本positive);假的正直:说明被预测为正样本,但预测是假的,即真实值为负样本
# FN:T(预测错了false)P(预测为负样本negative);假的负值,说明被预测为负样本,但预测是假的,即真实值为正样
召回率: 正确率:
针对预测样本而言,预测为正例的样本中真正正例的比例:
预测为正的有两种:
1、正样本被预测为正 TP
2、负样本被预测为正 FP
所以精确率:precesion = TP/(TP+FP) 其中分母预测为正样本数量。
针对原来的样本而言,表示样本中有多少正例被预测正确了(预测为正例的真是整理占所有真实正例的比例):
1、原来的正样本被预测为正样本 TP
2、原来的正样本被预测为负样本 FN
所以召回率为:racall = TP/(TP+FN) 其中分母表示原来样本中的正样本数量。
▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶▶
三、图像分割的衡量指标:
图像分割中通常有很多中衡量标准,也有很多中版本的pixel-accuracy 和IoU,这里我们介绍目前最常用的几种。为了方便解释,我们重述下定义:假设有k+1个类别(从L0到Lk包括一个背景或者空类 别)Pij为类别i的像素被预测为类别j的个数,换句话说,也就是Pii就是被正确分类(TP)的像素个数,Pij和Pji通常被解释为FP和FN,尽管两者都是假正和假负之和。
像素精确度(pixel accuracy,PA)
这是最简单的指标,用来计算被正确分类的像素个数和总像素数之间的比例:
为了方便理解,展开的形式为:
其中,分子中的每一项均为各个类别正确分类的像素个数;分母中的每一个括号项中为预测为该类别的所有像素数,
因此之和为所有像素数(TP+(FN+FP))。
平均像素精确度(Mean pixel Accuracy,MPA),这是在PA基础上做了微整提升,为类别内像素正确分类概率的平均值:
为了比较和PA的不同,展开:
这里的每一个加法项均为每个类别内部像素正确分类的比例,所有类别的正确分类概率之和最后取平均值。
平均交并比(Mean Intersection over Union,MIoU)
这是一个标准的衡量metric ,计算两个集合之间交集和并集的比例,在图像分割中,就是真实值(Ground Truth)和预测值两个集合。可以转换为TP(intersection)与TP ,FN ,FP之和(union)的比值。先计算每个类内的交并比,然后计算均值。
展开
对式中的每一个加法项是针对每一个类别进行计算平均交并比,其中分母中的第一项为真实值(GT)中该类的像素个数,第二项为预测值中预测为该类的像素个数,前两项中间存在一个交集:真实值中的也在预测值中,因此减去一个第三项。
对所有的类别分别求交并比,然后计算均值,即为MIoU.
加权交并比(Frequency Weighted Intersection over Union,FWIoU)
这是在MIoU上的基础上做稍微的提升,对每一个类根据出现的频率为其设置权重:
展开:
FWIoU=1∑ki=0∑kj=0Pij⋅(P00P00+P01P00+...+P0kP00(P00+P01+...+P0k)+(P00+P10+...+Pk0)−P00+...+Pk0Pkk+Pk1Pkk+...+PkkPkk(Pk0+Pk1+...+Pkk)+(P0k+P1k+...+Pkk)−Pkk) =1∑ki=0∑kj=0Pij⋅(P00⋅(P00+P01+...+P0k)(P00+P01+...+P0k)+(P00+P10+...+Pk0)−P00+...+Pkk⋅(Pk0+Pk1+...+Pkk)(Pk0+Pk1+...+Pkk)+(P0k+P1k+...+Pkk)−Pkk) =P00+P01+...+P0k∑ki=0∑kj=0Pij⋅P00(P00+P01+...+P0k)+(P00+P10+...+Pk0)−P00+...+Pk0+Pk1+...$$+Pkk∑ki=0∑kj=0Pij⋅Pkk(Pk0+Pk1+...+Pkk)+(P0k+P1k+...+Pkk)−Pkk
从第二个等号已经可以看出,乘法的第一个乘法因子的分母为全部的像素个数;乘法的第二项中每一项的分子中,第二个乘法因子(P00+P01+...+P0k)表示在真实值中(GT),该类别(此处为0)的所有像素个数;
因此第三个等号整理后,两者的比例P00+P01+...+P0k∑ki=0∑kj=0Pij=∑kj=0Pij∑ki=0∑kj=0Pij(当i为固定值时,此时为0)为该类像素在GT中出现的概率,乘法的后一项仍为MIoU中的类内交并比,因此只是在MIoU的基础上对每个类加了个权重,该权重为该类像素在GT中出现的比率。
over……..
参考博客:http://blog.csdn.net/u014593748/article/details/71698246
paper:《A Review on Deep Learning Techniques Applied to Semantic Segmentation》















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









