







论文笔记✍GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
📜 Abstract
🔨 主流做法+限制 :
我们在自动驾驶场景中提出了一种基于单个 RGB 图像的高效 3D 物体检测框架。我们的工作重点是提取 2D 图像中的底层 3D 信息,并在没有点云或立体数据的情况下确定物体的准确 3D 边界框。
🔨 本文做法:
利用现成的 2D 对象检测器,我们提出了一种巧妙的方法来有效地为每个预测的 2D 框获得粗长方体。粗长方体有足够的精度来指导我们通过细化来确定物体的3D盒子。与之前仅使用从 2D 边界框提取的特征进行框细化的最先进方法相比,我们通过利用可见表面的视觉特征来探索对象的 3D 结构信息。利用曲面的新特征来消除仅使用 2D 边界框带来的表示模糊问题。此外,我们研究了 3D 框细化的不同方法,发现具有质量感知损失的分类公式比回归具有更好的性能。
🔨 结果 :
根据 KITTI 基准评估,我们的方法优于当前基于单 RGB 图像的 3D 对象检测的最先进方法。
问题先导:
怎么获取粗糙的长方体?
怎么区分surface?怎么提取surface特征?提取suface特征干嘛用?
✨ 一、Introduction
🔨 1.1 Motivation :
我们的第一个观察结果是,可以从 2D 检测和场景先验知识中恢复 3D 粗糙结构。由于最先进的 2D 对象检测方法可以提供相当高精度的 2D 边界框,因此正确利用它们可以显着减少搜索空间,这已经应用于几种基于点云的方法中 [19, 12]。此外,利用自动驾驶场景的先验知识(例如投影矩阵),尽管缺乏点云,我们甚至可以在 2D 框中获得物体的近似 3D 边界框(长方体)。
受此启发,我们设计了一种算法,**通过 2D 检测器有效地确定预测对象的基本长方体。**虽然比较粗糙,但基本长方体具有可接受的精度,可以指导我们确定物体的 3D 设置、尺寸(高度、宽度、长度)和方向。因此,基本的粗长方体被我们称为Guidance。

作为我们的第二个观察结果,可以通过研究 3D 盒子的可见表面来利用底层 3D 信息。基于该指导,为了实现高精度,需要进一步分类以消除误报并进行适当细化以实现更好的定位。然而,仅使用二维边界框进行特征提取时信息缺失带来了表示模糊的问题。如图2所示,彼此差异较大的不同3D边界框可以具有相同的对应2D边界框。因此,模型将采用相同的特征作为输入,但分类器预计会为它们预测不同的置信度(图 2 中左侧的置信度较高,其他的置信度较低),这是冲突的。并且残差(Δx、Δy等)预测也很困难。仅从 2D 边界框来看,模型几乎无法知道(引导的)原始参数是什么,但它的目的是基于它们来预测残差。所以说训练是非常没有效果的。为了解决这个问题,我们探索了 2D 图像中的底层 3D 信息,并提出了一种新方法,该方法采用从 3D 框投影的可见表面解析的特征。如图1(c)所示,分别提取可见表面中的特征,然后合并,从而利用结构信息来区分不同形式的3D盒子。
对于3D框细化,我们将传统的回归形式重新表述为分类形式,并为其设计了质量感知损失,这显着提高了性能。
🔨 1.2 本文方法+贡献 :
我们的主要贡献如下:
1.我们提出了一种基于纯单目数据的方法,基于可靠的 2D 检测结果,有效地获得物体的粗略基本长方体。基本长方体提供了对象位置、大小和方向的可靠近似值,并作为进一步细化的指导。
2.我们利用2D图像上投影3D框的可见表面中潜在的3D结构信息,**并提出利用从这些表面提取的特征来克服先前方法中仅使用2D框的特征时特征模糊的问题。**通过表面特征的融合,模型获得了更好的判断能力,提高了细化精度。
3. 我们设计并研究了几种细化方法。我们得出的结论是,对于 3D 框细化任务,具有质量感知损失的基于离散分类的方法比直接回归方法表现得更好。
🔁 二、Related Work
🔨 2.1 常见做法:
3D物体检测方法可以根据数据分为3类,即点云、多视图图像(视频或立体数据)和单目图像。基于点云的方法,例如[4,19,27,12,21],可以直接获取3D空间中物体表面上的点的坐标,因此可以轻松实现比没有点云的方法高得多的精度。基于多视图的方法,例如[3],可以利用从不同视图的图像计算出的视差来获得深度图。虽然点云和立体方法具有更准确的 3D 推理信息,但单目 RGB 相机的设备更方便且便宜得多。
Mono3d的复杂性带来了严重的低效率问题。而我们在合理的假设下设计了一种基于纯射影几何的方法,该方法可以有效地生成数量少得多但精度更高的3D候选框。
这些方法只是从二维边界框中提取特征,这带来了表示模糊的问题。而我们利用表面特征来消除这个问题。
💻 三、Approach
🔨 3.1 FrameWork:

上图 显示了所提出的框架的概述。该框架采用单个 RGB 图像作为输入,包含以下步骤:
1)利用基于 CNN 的检测器来获取可靠的 2D 边界框和对象的观察方向。该子网被称为2D+O子网。
2)将获得的2D边界框和方向与驾驶场景的先验知识一起利用,生成称为引导的基本长方体。
3) 引导投影到像平面上。特征是从其 2D 边界框和可见表面中提取的。这些特征被融合为可区分的结构信息,以消除特征歧义。
4) 另一个称为 3D 子网的 CNN 使用融合特征来细化指导。 3D 检测被视为分类问题,质量感知分类损失用于学习分类器和 CNN 特征。
🔨 3.2 Subnetwork:
3.2.1 2D+O
对于 2D 检测,我们通过添加新的方向预测分支来修改更快的 R-CNN 框架。详细情况如图3所示。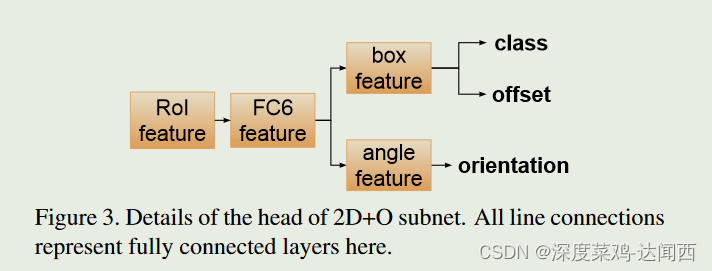
具体来说,使用称为 2D+O 子网的 CNN 从图像中提取特征,然后区域提案网络生成候选 2D 框提案。从这些建议中,ROI 池化用于提取 RoI 特征,然后用于分类、边界框回归和方向估计。 2D+O子网中估计的方向是物体的观察角度,与物体的外观直接相关。我们将观察角表示为 α,以便将其与全局旋转 θ 区分开来。 α和θ都在KITTI数据集中进行了注释,它们的几何关系如图4所示。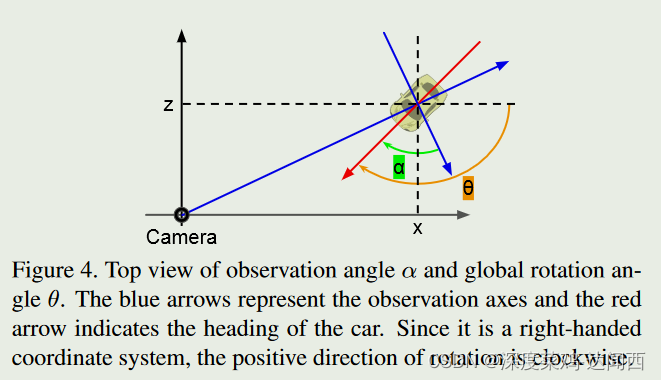
3.2.2 Guidance Gerneration
  根据2D检测结果,对每个2D框评估一个3Dbox。具体来说,我们的目标是在给定 2D 框 B2d = (x2d, y2d, h2d, w2d)、观察角 α 和相机的情况下,获得引导 Bg = (wg, hg, lg, xg, yg, zg, θg)固有矩阵K。
Obtaining Guidance Size (wg, hg, lg)
在自动驾驶场景中,同一类别实例的对象大小的分布是低方差和单峰的。有 (wg, hg, lg) = ( ̄ w, ̄ h, l ̄), 即: 使用每个类别的平均尺寸,作为粗略框的size值。
Estimating Guidance Location (xg, yg, zg)
我们的估计方法基于自动驾驶设置中的发现。对象 3D 框的顶部中心在 2D 平面上有一个稳定投影,非常接近 2D 边界框的顶部中点,3D 底部中心有一个类似的稳定投影,位于 2D 边界框上方并靠近。这一发现可以解释为,由于摄像头设置在数据采集车辆和驾驶场景中其他物体的顶部,因此大多数物体的顶部位置的投影都非常接近二维图像的消失线。与它有相似的高度。
具体做法:根据2Dbox的中心和size,得到2Dbox的上边和下边的中心位置。作为定位3Dbox上顶面和下底面的中心点位置。

z=1 ==> h\~
z=d ==> hg
==》 d = hg/h\~
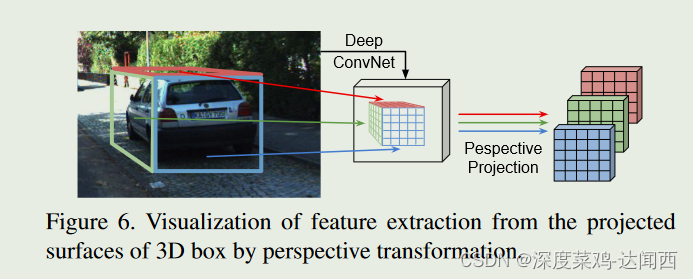
Surface Feature Extraction
图6示出了一个示例,可见投影表面分别对应于浅红色、绿色和蓝色所示的物体的顶部、左侧和背面。
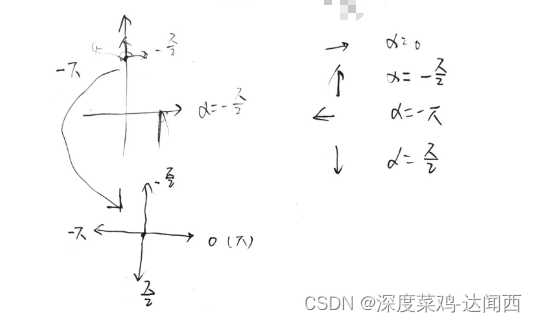
我们有 α ε (−π, π],其中观察者的右手方向为零角度 (α = 0),顺时针方向为正旋转。因此,当 α > 0 时,前表面可见,而当 α < 0 时,前表面可见。背面可见,当− π 2 <α< π 2 时,右侧可见,否则左侧可见。
可见表面区域中的特征通过透视变换扭曲为规则形状(例如 5x5 特征图)。具体来说,对于可见表面 F ,我们首先使用相机投影矩阵获得图像平面中的四边形 F 2d ,然后根据网络的步长计算特征图上缩放的四边形 F 2d s 。根据 F 2d s 的 4 个角点和 5x5 地图的目标 4 个角点的坐标,我们可以得到透视变换矩阵 P 。
每个区域的4个3D坐标==》投影到图像上==》图像上四边形F2ds==》img上(不规则)4个点和目标上(5x5)规则)4个点==》透视变换P。
令X、Y分别表示透视变换之前和之后的特征图。 Y 上坐标为 (i,j) 的元素的值由以下等式计算:

通常(u,v)不是整数坐标,我们使用4个最接近的整数坐标通过双线性插值来获得值Xu,v。
提取的可见表面特征被连接起来(Cat),我们使用卷积层来压缩通道数并融合不同表面上的信息。如图 7 所示,我们还从 2D 边界框提取特征以提供上下文信息。 2D 框特征与融合的表面特征连接起来,最后用于细化。用于回归3D属性
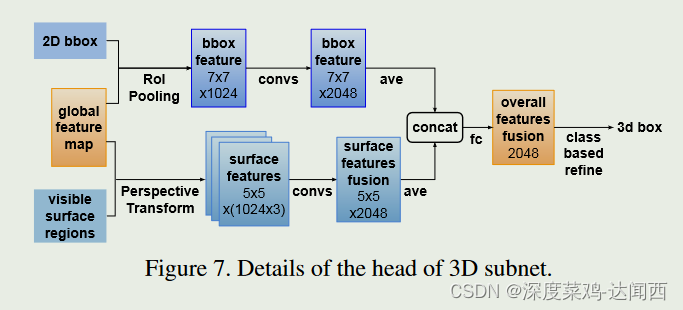
3.2.3 Refinement Methods

Classification Formulation
大范围内的回归通常并不比离散分类表现更好,因此我们将残差回归转化为用于 3D 框细化的分类公式。其主要思想是将残差范围划分为若干个区间,将残差值划分为一个区间。
将 Δdi = dgt i −dgd i 表示为第 i 个引导与其对应的真实 3D 设置描述符 d 的差,其中 d ∈ {w, h, l, x, y, z, θ}。计算训练数据上 Δd 的标准差 σ(d)。然后我们指定 (0, ±σ(d), ±2σ(d), …, ±N (d)σ(d)) 作为描述符 d 的区间的中心,每个区间的长度为 σ( d). N(d)根据Δd的范围选择。
由于指导可能来自误报 2D 框,因此我们将间隔视为多个二元分类问题。在训练过程中,如果引导的 2D 边界框无法与任何地面实况匹配,则所有间隔的概率将接近 0。这样,我们可以将引导视为背景并在推理时拒绝它如果所有类别的置信度都非常低。
Quality Aware Loss
我们期望分类中预测的置信度能够反映相应类别的目标框的质量,使得更准确的目标框获得更高的分数。很重要,因为 AP(平均精度)是通过根据候选人的分数对候选人进行排序来计算的。然而,常用的 0/1 标签不适合此目的,因为无论质量如何变化,模型都被迫为所有正候选者预测 1。受到 2D 检测中损失的启发 [11],我们将 0/1 标签更改为质量感知形式:

类似于 soft-max 一样的操作,软标签。















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









