






InternVL
三个创新点:
- 设计了6B的视觉编码器,8B的中间件(这是为了解决之前的工作中这两部分参数量小,无法和LLM的参数匹配的问题)
- 采用预训练的多语言LLaMA,来初始化中间件
- 稳定的训练策略:首先在大规模的粗糙的图文数据上启动对比学习,接着在fine-grained数据上进行生成学习
中间件QLLaMA:
其实就是QFormer的三个训练损失,也是用了query,只不过QFormer是传统的Transformer层,QLLaMA是直接用了LLaMA的权重初始化,QLLaMA相当于是用了现有能力的QFormer,参数量更大了
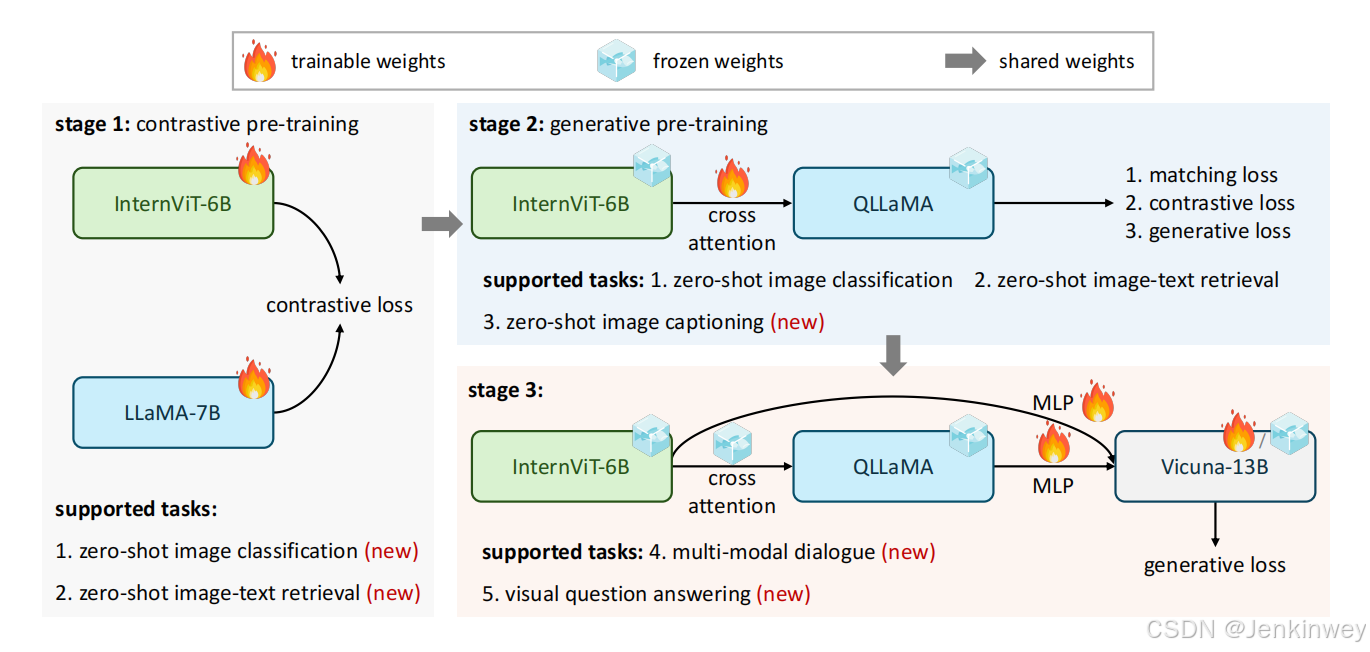
训练三个阶段
- Vision-Language Contrastive Training:用了5B的数据,通过对比学习训练InternViT-6B(完全随机初始化) 和 LLaMA-7B(pretrained weight初始化)
- Vision-Language Generative Training:用了1B的数据,通过类似于QFormer的三个损失来训练,QLLaMA就是通过第一步预训练得到的LLaMA-7B初始化,训练cross-attention层和query
- Supervised Fine-tuning:在QLLaMA后面加一个LLM,例如vicuna,类似于BLIP-2的第二阶段训练,可以只训练MLP,也可以MLP和QLLaMA一起训
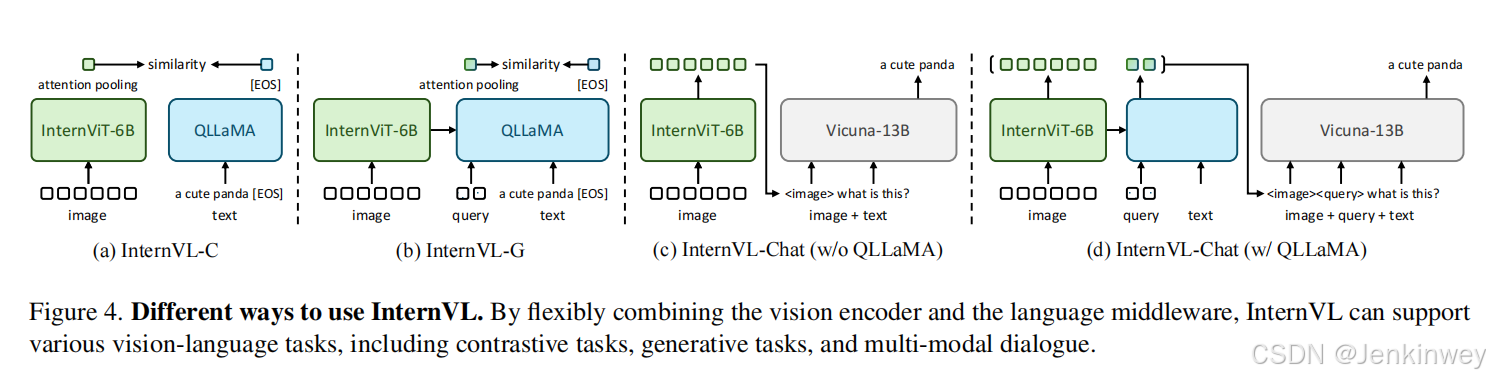
下游任务使用
InternVL1.5

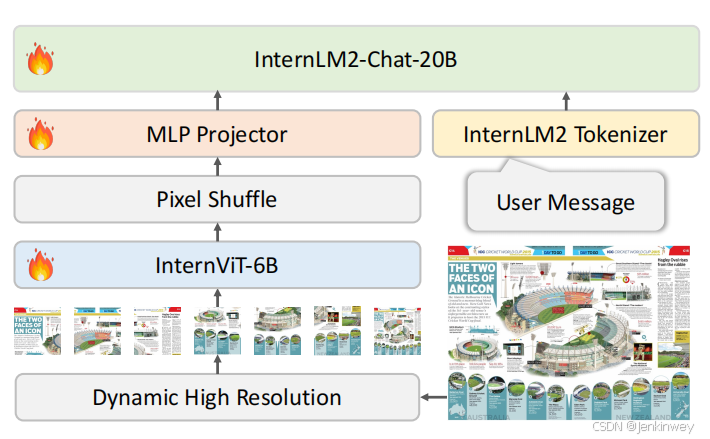
上面左图是InternVL1.5主要创新点,右图是模型结构。
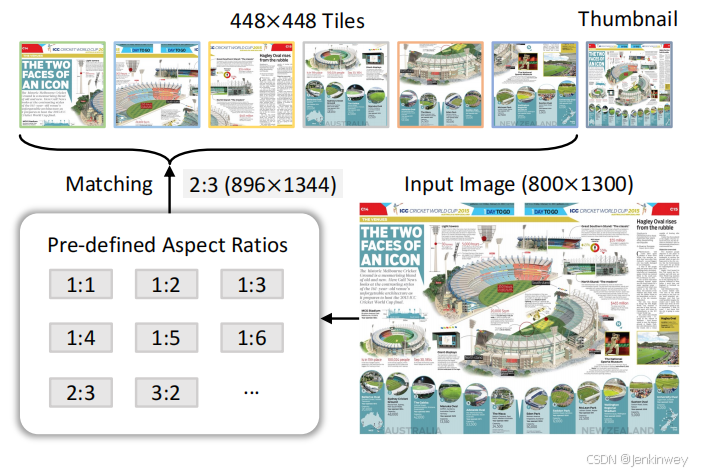
基于InternViT-6B和InternLM2-20B,通过MLP连接,和InternVL不是一个路子;为了解决之前开源方法多采用固定分辨率的图像做训练带来的问题,采用动态高分辨率策略,将图像分成1-40个448*448的块
动态分辨率
训练分为两个阶段
- 第一阶段预训练:训练InternViT-6B和MLP,用来优化视觉提取
- 第二阶段微调:微调整个26B的参数,用来增强多模态能力
有两个版本:InternVL1.2使用的是Nous-Hermes-2-Yi-34B作为LLM,InternVL1.5是InternLM2-20B
InternVL2
https://internvl.github.io/blog/2024-07-02-InternVL-2.0/
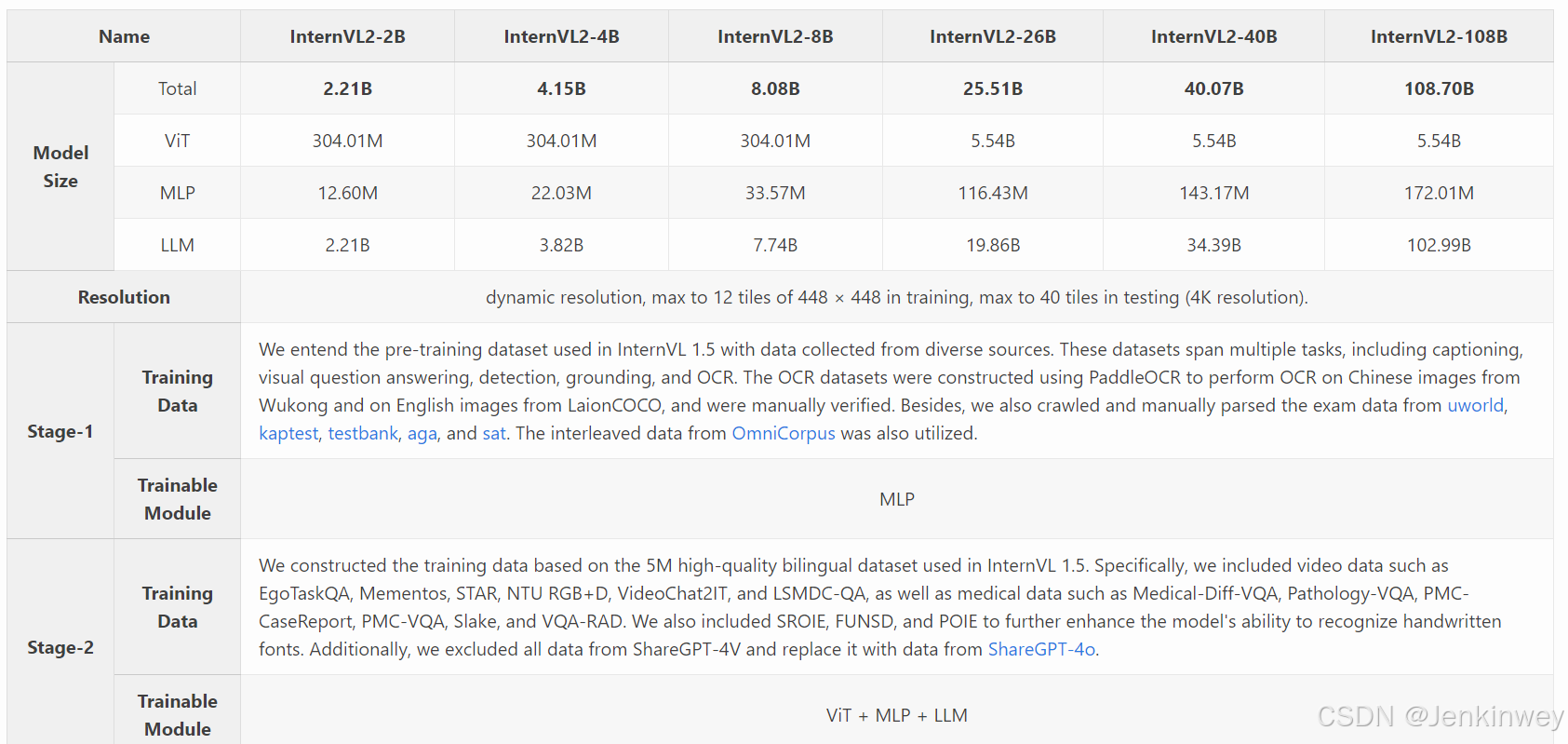
模型结构还是类似于InternVL1.5
第一阶段训练MLP,第二阶段 ViT + MLP + LLM


















 2099
2099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











