







支持向量机较其他传统机器学习算法的优点
-
小样本,并不是说样本的绝对数量少,而是说与问题的复杂度比起来,SVM算法要求的样本数是相对比较少的。SVM解决问题的时候,和样本的维数是无关的(甚至样本是上万维的都可以,这使得SVM很适合用来解决文本分类的问题,当然,有这样的能力也因为引入了核函数)。
-
结构风险最小。(对问题真实模型的逼近与问题真实解之间的误差,就叫做风险,更严格的说,误差的累积叫做风险)。
-
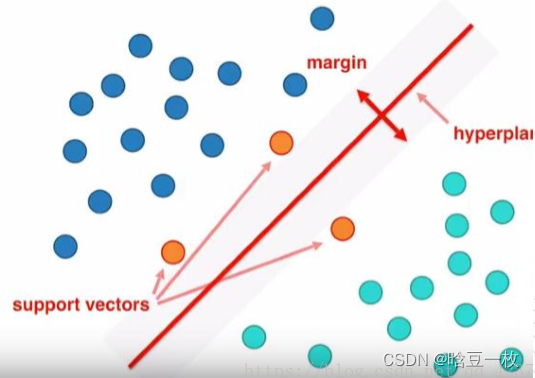
非线性,是指SVM擅长应付样本数据线性不可分的情况,主要通过松弛变量(也有人叫惩罚变量)和核函数技术来实现,这一部分是SVM的精髓
线性核函数:SVM::LINEAR,线性内核,没有高维空间映射,速度快;
多项式核函数:SVM::POLY,gamma>0,coef(),degree;
径向基核函数: SVM::RBF,比较好的选择,gamma>0;
SIGMOD核函数:这个核让人想起神经网络和深度学习。。gamma,coef();

车牌定位
void TestSVM1() {
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);
float labels[4] = { 1.0, 1.0, -1.0, -1.0 };
Mat labelsMat(4, 1, CV_32FC1, labels);
float trainingData[4][2] = { { 501, 10 }, { 255, 10 }, { 501, 255 }, { 10, 501 } };
Mat trainingDataMat(4, 2, CV_32FC1, trainingData);
CvSVMParams params; // set up SVM's parameters
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::LINEAR;
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);
CvSVM SVM; // train the svm
SVM.train (trainingDataMat, labelsMat, Mat(), Mat(), params);
Vec3b green(0, 255, 0), blue(255, 0, 0);
// show the decision region given by the SVM
for (int i = 0; i < image.rows; ++i) {
for (int j = 0; j < image.cols; ++j){
Mat sampleMat = (Mat_<float>(1, 2) << i, j);
float response = SVM.predict(sampleMat); // predict 函数使用训练好的SVM模型对一个输入的样本进行分类
image.at<Vec3b>(j, i) = (response == 1) ?Green : blue ;
}
}
int thickness = -1;
int lineType = 8;
circle(image, Point(501, 10), 5, Scalar(0, 0, 0), thickness, lineType);
circle(image, Point(255, 10), 5, Scalar(0, 0, 0), thickness, lineType);
circle(image, Point(501, 255), 5, Scalar(255, 255, 255), thickness, lineType);
circle(image, Point(10, 501), 5, Scalar(255, 255, 255), thickness, lineType);
thickness = 2; // show support vectors
lineType = 8;
// 获得当前的支持向量的个数
int c = SVM.get_support_vector_count();
for (int i = 0; i < c; ++i) {
const float* v = SVM.get_support_vector(i);
circle(image, Point((int)v[0], (int)v[1]), 6, Scalar(128, 128, 128), thickness, lineType);
}
//imwrite("result.png", image); // save the image
imshow("SVM Simple Example", image); // show it to the user
waitKey(0);
return;
}
SVM(Support Vector Machine)支持向量机
SVM算法是介于简单算法和神经网络之间的最好的算法。
只通过几个支持向量就确定了超平面,说明它不在乎细枝末节,所以不容易过拟合,但不能确保一定不会过拟合。可以处理复杂的非线性问题。
高斯核函数
缺点:计算量大
决策树(有监督算法,概率算法)
只接受离散特征,属于分类决策树。
条件熵的计算 H(Label |某个特征) 这个条件熵反映了在知道该特征时,标签的混乱程度,可以帮助我们选择特征,选择下一步的决策树的节点。
Gini和entropy的效果没有大的差别,在scikit learn中默认用Gini是因为Gini指数不需要求对数,计算量少。
把熵用到了集合上,把集合看成随机变量。
决策树:贪心算法,无法从全局的观点来观察决策树,从而难以调优。
叶子节点上的最小样本数,太少,缺乏统计意义。
从叶子节点的情况,可以看出决策树的质量,发现有问题也束手无策。
优点:可解释性强,可视化。
缺点:容易过拟合(通过剪枝避免过拟合),很难调优,准确率不高
g. 二分类,正负样本数目相差是否悬殊,投票机制h. 决策树算法可以看成是把多个逻辑回归算法集成起来。
训练数据——SVM、ANN模型















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









