







1. 基本门电路
- 在COMS电路中,最基本的三个门电路是非门、或非门、与非门。

- 传输门:
传输门实际由一对N沟道和P沟道的MOS管并联构成,NMOS的gate为高时导通,PMOS的gate为低时导通。上面的表示符号带非端的连接口即为PMOS的gate端,对面的为NMOS的gate端。当PMOS端为低电平,NMOS端为高电平时传输门导通,反之传输门关断。因此可以简单的理解传输门是一个电路开关。
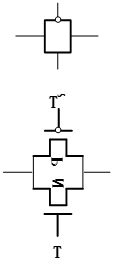
2. 触发器原理

- 当clk为低电平时红色传输门导通,蓝色传输门关断
- 当clk为高电平时红色传输门关断,蓝色传输门导通
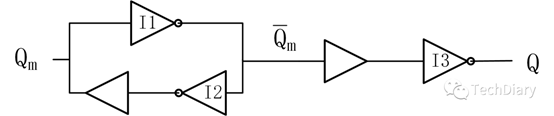
我们将整个过程分为clk为低电平、高电平、上升沿三个阶段分析: - clk为低电平时
根据上面的分析,T1、T4为导通状态,我们可以将其看作是一个具有延时效应的连线,T2、T3为关断状态,我们可以去除掉相关电路元件。此时,电路被划分为了两截,如下所示:
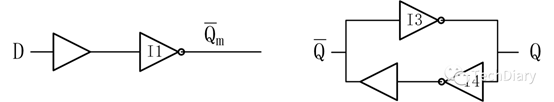
容易分析出,此时左边部分的电路将会随着D变化而延时变化,极性与D相反。右边部分的电路,由于T3传输门关断,右边部分的信号将会维持上一时态的不变,两个并联的方向相反的反相器起到了一个锁存的作用,此时电路的输出将仍旧保持上一个状态。 - clk为高电平时
clk为高电平时,分析方法与低电平时相似,可以得到下面的图:
此时左半部分的电路起到锁存信号的作用,锁存过程之后信号处于稳定状态,Q也将会随着的稳定趋于稳定。 - clk上升沿时
当clk上升沿时,即clk由低电平变为高电平的过程。此时我们来分析建立时间与保持时间具体是由什么原因产生的: - 建立时间
当时钟处于低电平时,将随着D输入的变化而变化,时钟高电平时将会对进行锁存。我们需要意识到的是,数据信号通过传输门以及反相器是需要消耗时间的,因此触发器的建立时间指的是数据通过T1、I1至的时间。这时建立时间的存在意义就大白天下了,我们需要在进入时钟高电平阶段前将稳定的数据送入到锁存处,由于电路延时的原因,才需要建立时间的存在。当然,上面的结论是忽略了时钟本身的偏移的,事实上建立时间也有时钟偏移的影响,因此也会出现负建立时间的情况 - 保持时间
当时钟进入高电平后,进行锁存,并经过T3、I3后输出到Q端,因此保持时间本质上是数据通过T3、I3的时间,保持时间过后,数据才能保证稳定。同样的,上面的结论也是忽略了时钟本身偏移的,只是保持时间发生于时钟沿之后,因此锁存时时钟沿必须到达,因此不会出现负的保持时间(即在时钟沿到达前数据稳定),最小的保持时间为0。
总结一下: - 建立时间是在时钟上升沿来临之前将数据锁存的时间
- 保持时间是在时钟上升沿来临之后将锁存的数据输出的时间
3. 建立时间和保持时间
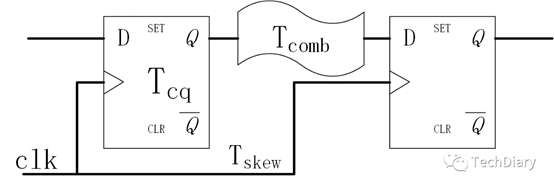

通过分析,得到下面这个经典的公式:
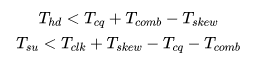
- 亚稳态

结合第三点建立时间和保持时间产生的原因,如果想要在这个时钟的上升沿采集到高电平,必须在时钟上升沿之前建立时间到达。如果不满足建立时间的要求,则经过延时之后,触发器锁存的值有可能是高电平,也有可能是低电平。

5. 跨时钟域传输
https://www.cnblogs.com/lyc-seu/p/12441366.html#控制信号多比特同步
- 跨时钟域,clock domain crossing(CDC)是一块非常重要的知识点,可分为单比特跨时钟和多比特跨时钟域传输。
- 所谓的跨时钟域概念,只有不同的晶振产生的时钟才是不同的时钟域吗?利用计数器产生的时钟属于同步时钟吗?
- 经过一个pll产生的时钟理论上属于同步时钟,但是为了提高系统的稳定性,还是需要做跨时钟的同步。
- 单比特跨时钟域
a) 从慢时钟到快时钟
在时钟域B下的脉冲pulse_b在时钟域A看来,是一个很宽的“电平”信号,会保持多个clk_a时钟周期,所以一定能被clk_a采到。经验设计采集过程必须寄存两拍。第一拍将输入信号同步化,同步化后的输出可能带来建立/保持时间的冲突,产生亚稳态。需要再寄存一拍,减少亚稳态带来的影响。一般来说两级是最基本要求,如果是高频率设计,则需要增加寄存级数来大幅降低系统的不稳定性。也就是说采用多级触发器来采样来自异步时钟域的信号,级数越多,同步过来的信号越稳定。

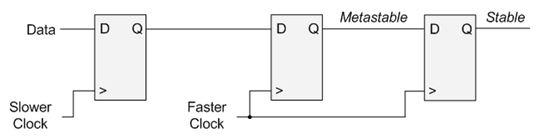
特别需要强调的是,此时pulse_b必须是clk_b下的寄存器信号,如果pulse_b是clk_b下的组合逻辑信号,一定要先在clk_b先用D触发器(DFF)抓一拍,再使用两级DFF向clk_a传递。这是因为clk_b下的组合逻辑信号会有毛刺,在clk_b下使用时会由setup/hold时间保证毛刺不会被clk_b采到,但由于异步相位不确定,组合逻辑的毛刺却极有可能被clk_a采到。一般代码设计如下:
always @ (posedge clk_a or negedge rst_n)
begin
if (rst_n == 1'b0)
begin
pules_a_r1 <= 1'b0;
pules_a_r2 <= 1'b0;
pules_a_r3 <= 1'b0;
end
else
begin //打3拍
pules_a_r1 <= pulse_b;
pules_a_r2 <= pules_a_r1;
pules_a_r3 <= pules_a_r2;
end
end
assign pulse_a_pos = pules_a_r2 & (~pules_a_r3); //上升沿检测
assign pulse_a_neg = pules_a_r3 & (~pules_a_r2); //下降沿检测
assign pulse_a = pules_a_r2;
最后如果也需要得到一个周期的脉冲,做一次时钟上升沿检测即可。
- 关于为什么打两拍可以减少亚稳态发生的概率:

b) 从快时钟到慢时钟
如果单bit信号从时钟域A到时钟域B,那么存在两种不同的情况,传输脉冲信号pulse_a或传输电平信号level_a。实际上,电平信号level_a的宽度足够宽才能被clk_b采集到才可以保证系统正常工作。那么对于脉冲信号pulse_a采取怎样的处理方法呢?可以用一个展宽信号来替代pulse_a实现垮时钟域的握手。
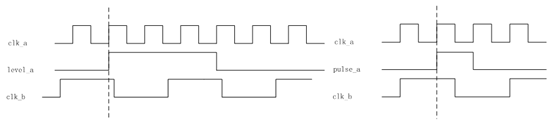
主要原理就是先把脉冲信号在clk_a下展宽,变成足够宽的电平信号signal_a,再向clk_b传递,当确认clk_b已经“看见”信号同步过去之后,再清掉signal_a。代码通用框架如下:
module Sync_Pulse(
input clka,
input clkb,
input rst_n,
input pulse_ina,
output pulse_outb,
output signal_outb
);
//-------------------------------------------------------
reg signal_a;
reg signal_b;
reg signal_b_r;
reg signal_b_rr;
reg signal_a_r;
reg signal_a_rr;
//-------------------------------------------------------
//在clka下,生成展宽信号signal_a
always @(posedge clka or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_a <= 1'b0;
end
else if(pulse_ina == 1'b1)begin
signal_a <= 1'b1;
end
else if(signal_a_rr == 1'b1)
signal_a <= 1'b0;
else
signal_a <= signal_a;
end
//-------------------------------------------------------
//在clkb下同步signal_a
always @(posedge clkb or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_b <= 1'b0;
end
else begin
signal_b <= signal_a;
end
end
//-------------------------------------------------------
//在clkb下生成脉冲信号和输出信号
always @(posedge clkb or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_b_r <= 'b0;
signal_b_rr <= 'b0;
end
else begin
signal_b_rr <= signal_b_r;
signal_b_r <= signal_b;
end
end
assign pulse_outb = ~signal_b_rr & signal_b_r;
assign signal_outb = signal_b_rr;
//-------------------------------------------------------
//在clka下采集signal_b_rr,生成signal_a_rr用于反馈拉低signal_a
always @(posedge clka or negedge rst_n)begin
if(rst_n == 1'b0)begin
signal_a_r <= 'b0;
signal_a_rr <= 'b0;
end
else begin
signal_a_rr <= signal_a_r;
signal_a_r <= signal_b_rr;
end
end
endmodule
- 多比特跨时钟域
- 通常使用异步FIFO或者异步双口ram的方式来实现同步。
- FIFO generator或者双口ram这两种方式的优缺点与使用场景?
当数据量较大的时候,使用FIFO的效率比较高。 - 假设我们现在有一个信号采集平台,ADC芯片提供源同步时钟60MHz,ADC芯片输出的数据在60MHz的时钟上升沿变化,而FPGA内部需要使用100MHz的时钟来处ADC采集到的数据(多bit)。在这种类似的场景中,我们便可以使用异步双口RAM来做跨时钟域处理。先利用ADC芯片提供的60MHz时钟将ADC输出的数据写入异步双口RAM,然后使用100MHz的时钟从RAM中读出。
- 在这个场景中,其实很多人都是使用直接用100MHz的时钟对RAM的写地址进行打两拍的方式,但RAM的写地址属于多bit,如果单纯只是打两拍,那不一定能确保写地址数据的每一个bit在100MHz的时钟域变化都是同步的,肯定有一个先后顺序。如果在低速的环境中不一定会出错,在高速的环境下就不一定能保证了。所以更为妥当的一种处理方法就是使用格雷码转换。
- 格雷码
对于格雷码,相邻的两个数间只有一个bit是不一样的如果先将RAM的写地址转为格雷码,然后再将写地址的格雷码进行打两拍,之后再在RAM的读时钟域将格雷码恢复成10进制。这种处理就相当于对单bit数据的跨时钟域处理了。
参考链接:https://blog.csdn.net/u014070258/article/details/90052281



-
静态时序分析
-
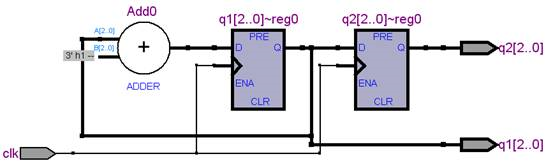
阻塞赋值和非阻塞赋值
这只是一种人为定义的语法,表面上来看一种是并行的,一种是串行的,其实质是使用阻塞赋值和非阻塞赋值会翻译出来不同的电路,理解到这种程度就行了。
https://blog.csdn.net/g360883850/article/details/91446388
- 阻塞赋值:
module blockingassignment (clk ,q1,q2);
input clk;
output [2:0] q1,q2;
reg[2:0] q1,q2;
always @ (posedge clk)
begin
q1=q1+3'b1;
q2=q1;
end
endmodule

- 非阻塞赋值:
module nonblockingassignment (clk ,q1,q2);
input clk;
output [2:0] q1,q2;
reg[2:0] q1,q2;
always @ (posedge clk)
begin
q1<=q1+3'b1;
q2<=q1;
end
endmodule
8. 边沿检测
https://blog.csdn.net/vivid117/article/details/90757350?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
对异步信号进行边沿检测应该先打两拍同步之后再检测,所以应该是打三拍。
9. 奇数和小数分频
- 奇数分频
奇数分频相对于偶数分频较为复杂,尤其是占空比为50%的奇数分频,可以采用错位相和的方法,即分别用上升沿和下降沿产生2:3占空比的N分频时钟,并将输出进行或运算得到。也可以产生3:2占空比的N分频时钟,并将输出进行与运算得到奇数分频时钟。
// 奇数分频器示例,5分频即N=5,占空比50%
module Fre_div_odd(
input clk,
input rst_n,
input [3:0] N, // N分频
output clk_out
);
reg clk_n;
reg clk_p;
reg [3:0] cnt_p;
reg [3:0] cnt_n;
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
clk_p <= 1'b0;
cnt_p <= 4'b0;
end
else
begin
if(cnt_p == N-1)
begin
clk_p <= ~clk_p;
cnt_p <= 4'b0;
end
else if(cnt_p == (N-1)/2)
begin
clk_p <= ~clk_p;
cnt_p <= cnt_p + 1;
end
else
begin
cnt_p <= cnt_p + 1;
clk_p <= clk_p;
end
end
end
always @(negedge clk or negedge rst_n)
begin
if(!rst_n)
begin
clk_n <= 1'b0;
cnt_n <= 4'b0;
end
else
begin
if(cnt_n == N-1)
begin
clk_n <= ~clk_n;
cnt_n <= 4'b0;
end
else if(cnt_n == (N-1)/2)
begin
clk_n <= ~clk_n;
cnt_n <= cnt_n + 1;
end
else
begin
cnt_n <= cnt_n + 1;
clk_p <= clk_p;
end
end
end
assign clk_out = clk_n | clk_p;
endmodule
仿真时序图:

- 小数分频
在实际工程中,经常遇到需要半分频的情况,例如时钟晶振为25MHz,而我们需要用到2MHz的时钟信号,就需要进行12.5分频。
半分频无法实现50%占空比,因为实现需要得到时钟信号的0.25周期,是无法实现的,因此只能使占空比尽量接近50%。
半分频可以在奇数分频器额基础上实现,利用已经得到的奇数分频时钟信号将原时钟信号的后半段翻转;然后再对翻转后的波形计数,得到的波形与奇数分频得到的波形进行异或后即可得到需要的半分频时钟信号。

// 半分频器示例,以2.5分频为例,即N=2
module Fre_div_half(
input clk,
input rst_n,
input [3:0] N, // 即实现N+0.5分频
output clk_out
);
wire clk_div_odd;
wire clk_rev;
/* 按照上文的实现方法搭建奇数分频
N_odd = 2 * N + 1
具体实现省略
奇数分频后得到clk_div_odd */
Fre_div_odd Fre_div_odd(
.clk(clk),
.rst_n(rst_n),
.N(2*N+1),
.clk_out(clk_div_odd)
);
assign clk_rev = clk_div_odd ? ~clk : clk;
reg [3:0] cnt_rev;
reg clk_rev_div;
always @(posedge clk_rev or negedge rst_n)
begin
if(!rst_n)
begin
clk_rev_div <= 0;
cnt_rev <= 0;
end
else
begin
if(cnt_rev == N/2)
begin
clk_rev_div <= ~clk_rev_div;
cnt_rev <= cnt_rev + 1;
end
else if(cnt_rev == N)
begin
cnt_rev <= 0;
end
else
begin
cnt_rev <= cnt_rev + 1;
clk_rev_div <= clk_rev_div;
end
end
end
assign clk_out = clk_div_odd ^ clk_rev_div;
endmodule
仿真时序图:

10. 组合逻辑和时序逻辑
11. 复位
异步触发,同步释放。
module sync_reset(
input clock,
input rst_asyn_n,
output reg rst_n
);
reg q;
// first DFF
always@(posedge clock or negedge rst_asyn_n)begin
if(!rst_asyn_n)
q <= 1'b0;
else
q <= 1'b1;
end
// second DFF
always@(posedge clock or negedge rst_asyn_n)begin
if(!rst_asyn_n)
rst_n <= 1'b0;
else
rst_n <= q;
end
endmodule
12. 格雷码
- 例如从十进制的3转换为4时二进制码的每一位都要变,能使数字电路产生很大的尖峰电流脉冲。而格雷码则没有这一缺点,它在相邻位间转换时,只有一位产生变化。它大大地减少了由一个状态到下一个状态时逻辑的混淆。
- 在数字系统中,常要求代码按一定顺序变化。例如,按自然数递增计数,若采用8421码,则数0111变到1000时四位均要变化,而在实际电路中,4位的变化不可能绝对同时发生,则计数中可能出现短暂的其它代码(1100、1111等)。在特定情况下可能导致电路状态错误或输入错误。使用格雷码可以避免这种错误。
- 二进制转格雷码:右移一位然后与原来的二进制数按位进行异或(^)。
module binary_to_gray#( parameter WIDTH = 4 )(
input [WIDTH:0] binary_value,
output [WIDTH:0] gray_value
);
assign gray_value = (binary_value >> 1) ^ binary_value;
endmodule
- 格雷码转二进制码:

module gray_to_binary #( parameter WIDTH = 4)(
input [WIDTH : 0] gray_value,
output [WIDTH : 0] binary_value
);
assign binary_value[WIDTH] = gray_value[WIDTH];
genvar i;
generate
for(i = 0; i <WIDTH - 1; i = i + 1) begin
binary_value[i] = gray_value[i] ^ binary_value[i + 1];
end
endgenerate
endmodule
13. FIFO
- FIFO的三大用处:
- 数据位宽转换
- 跨时钟域同步
- 提高传输效率,增加DDR带宽的利用率。
- 同步FIFO
module slave_fifo (
input clk_i, // Clock input
input rstn_i, // Reset signal
input [31:0] chx_data_i, // Data input ---->From outside
input a2sx_ack_i, // Read ack ---->From Arbiter
input chx_valid_i, // Data is valid From outside ---->From Outside
output reg [31:0] slvx_data_o, // Data Output ---->To Arbiter
output [5:0] slvx_margin_o, // Data margin ---->To Outside
output reg chx_ready_o, // Ready to accept data ---->To outside
output reg slvx_val_o, // Output data is valid ---->To Arbiter
output reg slvx_req_o // Request to send data ---->To Arbiter
);
//------------------------------Internal variables-------------------//
reg [5:0] wr_pointer_r;
reg [5:0] rd_pointer_r;
reg [31:0] mem [0:31]; //FIFO 32bits width and 32 deepth
//-----------------------------Variable assignments------------------//
wire full_s, empty_s, rd_en_s ;
wire [5:0] data_cnt_s;
assign full_s = ({~wr_pointer_r[5],wr_pointer_r[4:0]}==rd_pointer_r);
assign empty_s = (wr_pointer_r == rd_pointer_r);
assign data_cnt_s = (6'd32 - (wr_pointer_r - rd_pointer_r));
assign slvx_margin_o = data_cnt_s;
assign rd_en_s = a2sx_ack_i;
//-----------Code Start---------------------------------------------//
always @ (*) //ready signal
begin
if (!full_s) chx_ready_o = 1'b1; //If FIFO is not full then it is ready to accept data
else chx_ready_o = 1'b0;
end
always @ (*) //reset signal
begin
if (!rstn_i) slvx_req_o = 1'b0;
else if (!empty_s) slvx_req_o = 1'b1; //If FIFO is not empty then it is ready to send data
else slvx_req_o = 1'b0;
end
//write pointer increment
always @ (posedge clk_i or negedge rstn_i)
begin : WRITE_POINTER
if (!rstn_i) begin
wr_pointer_r <= 6'b0000;
end else
if (chx_valid_i && chx_ready_o) begin
wr_pointer_r <= wr_pointer_r + 6'b0001;
end
end
//read pointer increment
always @ (posedge clk_i or negedge rstn_i)
begin : READ_POINTER
if (!rstn_i) begin
rd_pointer_r <= 6'b0000;
end else
if (rd_en_s && (!empty_s)) begin
rd_pointer_r <= rd_pointer_r + 6'b0001;
end
end
//data output is vaild
always @ (posedge clk_i or negedge rstn_i)
begin
if (!rstn_i) slvx_val_o <= 1'b0;
else if (rd_en_s && (!empty_s))
slvx_val_o <= 1'b1;
else slvx_val_o <= 1'b0;
end
// Memory Read Block
always @ (posedge clk_i )
begin : READ_DATA
if (rstn_i && rd_en_s && (!empty_s)) begin
slvx_data_o <= mem[rd_pointer_r[4:0]];
end
end
// Memory Write Block
always @ (posedge clk_i)
begin : MEM_WRITE
if (rstn_i && chx_valid_i && chx_ready_o) begin
mem[wr_pointer_r[4:0]] <= chx_data_i;
end
end
endmodule
- 异步FIFO
参考链接:https://blog.csdn.net/u014070258/article/details/90052281 - FIFO深度计算
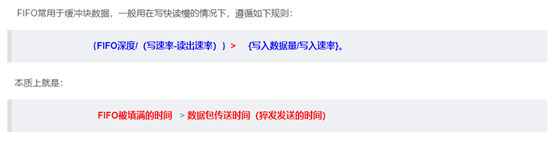
参考链接https://blog.csdn.net/qq_26652069/article/details/90720568#commentBox
14. 序列检测与序列产生
14.1 序列产生
先挖个坑
14.2 序列检测
序列检测一般有两种方式:第一是状态机,第二是移位寄存器。
15. 状态机
摩尔状态机和米莉状态机的区别:https://blog.csdn.net/CrazyUncle/article/details/88830654
三段式状态机:
https://reborn.blog.csdn.net/article/details/101852460
module seq_detect(
input clk,
input rst_n,
input seq_in,
output reg out
);
//detect sequence 01010
//first step: define parameter and state
parameter s0 = 6'b0000_01, s1 = 6'b0000_10, s2 = 6'b0001_00, s3 = 6'b0010_00,
s4 = 6'b0100_00, s5 = 6'b1000_00;
reg [5:0] cur_state, nxt_state;
//三段式状态机
//第一段:时序逻辑
always@(posedge clk or negedge rst_n) begin
if(~rst_n) cur_state <= s0;
else cur_state <= nxt_state;
end
//第二段:组合逻辑
always@(*) begin
nxt_state = s0;
case(cur_state)
s0: if(seq_in == 0) nxt_state = s1;
else nxt_state = s0;
s1: if(seq_in == 1) nxt_state = s2;
else nxt_state = s1;
s2: if(seq_in == 0) nxt_state = s3;
else nxt_state = s0;
s3: if(seq_in == 1) nxt_state = s4;
else nxt_state = s1;
s4: if(seq_in == 0) nxt_state = s5;
else nxt_state = s0;
s5: if(seq_in == 1) nxt_state = s0;
else nxt_state = s1;
default: nxt_state = s0;
endcase
end
//第三段:组合逻辑
always@(*) begin
if(cur_state == s5) out = 1; //这里使用的是cur_state
else out = 0;
end
//第三段:时序逻辑
/*
always@(posedge clk or negedge rst_n) begin
if(~rst_n) out <= 0;
else if(nxt_state == s5) out <= 1; //这里使用的是 nxt_state
else out <= 0;
end
*/
endmodule
16. 串并转换
17. 卡诺图化简
https://blog.csdn.net/hahasusu/article/details/88244155
18. 低功耗设计
https://my.oschina.net/iccer/blog/4389124?from=singlemessage
19. 同步电路和异步电路
20. 门控时钟
门控时钟(integrated clocking gating),简称ICG,是低功耗设计中的重要组成部分。
module ICG(
input clk,
input enable,
output clk_out
);
reg Q;
always @ (clk or enable) //latch,组合逻辑,没有else会生成锁存器
if( !clk )
Q <= enable;
assign clk_out = ~Q | clk; //与非门
endmodule
- 为什么要用latch,先用同步再用if可以吗?
应该是可以的,只是通过latch的方式综合出来的电路面积更小。
21. 无毛刺时钟切换
无毛刺时钟切换实际上是门控时钟的一部分。
22. 有符号数和无符号数
- 有符号数和无符号数数值运算:
https://blog.csdn.net/u014485485/article/details/79962316 - 算数右移>>>和逻辑右移>>的区别:https://blog.csdn.net/weixin_45764003/article/details/108022404
23. 时序分析与约束
参考链接:https://www.bilibili.com/video/BV1if4y1p7Dq?p=2&spm_id_from=pageDriver
- 对时序约束和时序分析的理解:
https://blog.csdn.net/qq_33486907/article/details/89392630
– 好的时序是设计出来的额,而不是约束出来的。
– 时序约束的作用:使工具优化综合和布局布线策略,以满足时序要求;为时序分析提供依据。 - 课程大纲:

- TCL
- Reference name 和instance name
- Port clock cell net pin design
- 正则表达式(regular expression)
2) 用脚本实现自动化Flow
3) PrimeTime
4) 四种时序路径: - Clk → D
- Clk → output port
- Input port →D
- Input port → output port
5) 全局异步,局部同步
Set_false_path -from [get_clocks USBCLK] -to [get_clocks MEMCLK],这条约束告诉时序分析器不用分析这条路径。
6)operation condition:Process,Voltage,Temperature(PVT)。
Ss → max → setup time
Ff → Min → hold time
7) slew_derate
8) launch clock 和 capture clock。
9) input delay 和 output delay。
10)setup time check

- hold time check

12)特殊时序路径检查:多周期、半周期和伪路径。
- 多周期

Hold time check:N-1(cycles)

- 半周期

在数字电路中,hold time违例是比较难解决的,所以当一个模块给另外一个模块打数据的时候,可以使用半周期(其实就是下降更新数据,然后用上升沿来采样),这样的话,hold time就会变得非常的容易满足,而建立时间会变得非常紧张,但是建立时间违例是比较好修正的。


- 伪路径:不可能发生的时序路径,通常出现在跨时钟域的情况下。
13) 特殊时序检查:多时钟域
- Slow to fast clock domains


In summary, if a setup time multicycle of N cycles is specified, then most likely a hold multicycle of N -1 cycles should also be specified。
- Fast to slow clock domains

一般都是针对快时钟来进行时序分析,所以注意-end和-start option的使用。另外注意多周期和多时钟域的区别和联系。前者是一个时钟,后者是多个时钟。
14) 特殊时序检查:多时钟
- Integer multiples


- Non-Integer Multiples
其实基本的思路就是选择最严苛的情况进行时序分析。

- Phase shifted

Hold time check 默认是在setup time check前一个cycle。
15) Robust Verification
- OCV(on-chip-variations)

Setup time check的思路就是将launch path的delay放大,将capture path的delay减小,这样是最严苛的情况。但是launch path和capture path的common path需要移除(CRPR)。


16)Time Borrowing

对于latch来说,高电平期间处于透明状态,低电平期间是保持的状态。Latch和dff都属于时序逻辑单元。



17)Data to Data Checks


- Clock Gating


- 先把这个EN信号同步一下,再做与运算可以吗?这个EN信号属于同步信号吗?

一般来说,工具会自动识别出门控时钟进行时序检查,但是对于一些复杂的门控时钟需要人为进行约束。





19)习题
-
习题1
-
习题2
-
习题3















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









