







1、前情分析
在现实世界的预测问题中,试图共同学习多个时间序列时经常遇到的一个挑战是,时间序列的数量级差异很大,而且数量级的分布具有很强的倾斜性。这个问题如图1所示,图中显示了亚马逊销售的数百万件商品的销售速度(即平均每周销售一件商品)的分布情况。分布在几个数量级上,近似幂律。
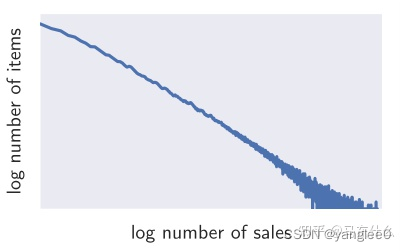
据我们所知,这一发现是新的(尽管可能并不令人惊讶),并且对试图从这些数据集学习全局模型的预测方法具有基本意义。由于该分布的无标度特性,很难将数据集划分为具有一定速度带的时间序列子组,并为它们学习单独的模型,因为每个速度子组都会有相似的偏态。此外,基于分组的正则化方案,比如Chapados[4]提出的方案,可能会失败,因为每个分组的速度将有很大的不同。最后,这种偏态分布使得使用某些常用的标准化技术,如输入标准化或批标准化[14],效果较差。
这里说的是最常见的多序列预测问题,web traffic,rossman store forecasting等比赛以及电商的商品销量预测的都是典型的多序列预测问题,不同商品的base level(时序数据四分量之一)差异很大,整体也呈现幂律分布,常规标准化处理无效,因为常规的标准化基于全局的统计特征无法改变不同商品之间的相对大小关系,使得不同商品的base level差异仍旧很大,冷门商品的销量和热门商品的销量相差成千上万倍,这导致输入数据的量纲差异极大(一般基本是做分组标准化),即不同的商品自己内部做标准化,从而使得不同商品的序列数据具有可比性。
2、deepar模型说明部分
为了便于说明,这里我们以电商销量预测的问题为例:
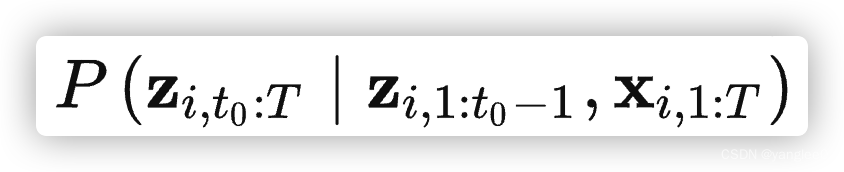
其中已有从时刻1~时刻t0 -1的商品的销量数据,
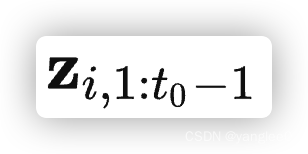
而Xi,1:T表示从时刻1到时刻T的所有的协变量

这里需要说明,我们假设[1, t0− 1]为已知销量的时间区间,[t0, T]为我们需要预测的时间区间,而Xi,1:T是横跨了[1, t0− 1]和[t0, T]两个时间区间的,这意味着X 必然是 静态特征(例如商品的大类,商品所在的省,城市或商品的历史销量的统计值)或者是可以推断的动态特征,time varying known features,例如月份,年份,随着时间变化,但是他们未来的值是可以直接推算出来的,而销量这种数据属于不可推断的动态特征(同时也是标签),即time varying unknown features。

模型结构图如上,在理解上图之前,需要了解两个背景知识:
1、时间序列预测中的自回归模型:
时间序列预测中进行自回归式的预测本质上是把多步预测转化为多个递归式的单步预测,一个典型的例子就是基于RNN的seq2seq结构。seq2seq的结构有两种形式:
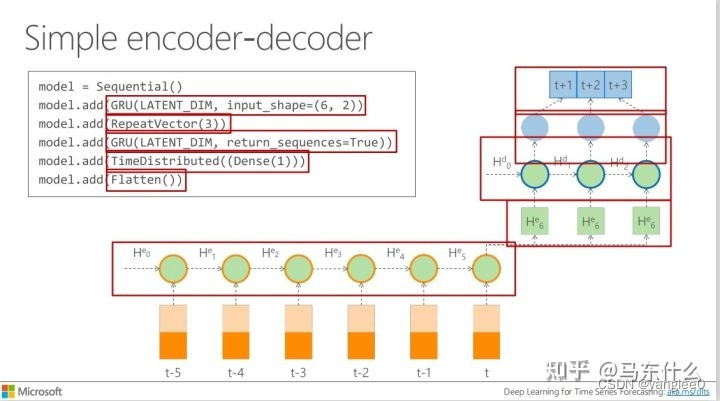
简单的seq2seq的结构是无法使用预测的数据的特征,仅仅是将t时刻的隐层输出作为decoder部分的共同输入。
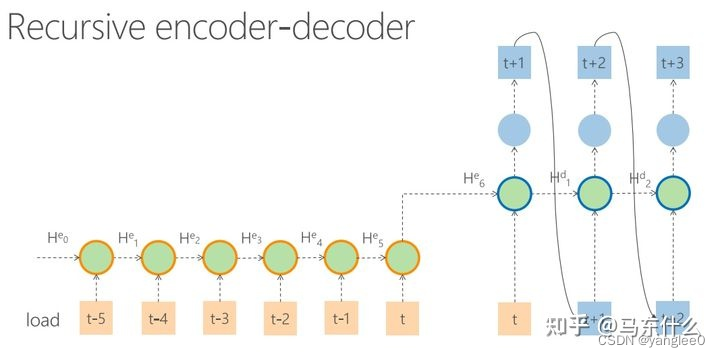
实际上上图的seq2seq结构才算是在做真正意义上的自回归,t+1时刻的预测结果被用于帮助预测t+2时刻的结果,t+2时刻的预测结果被用于帮助预测t+3时刻的结果。
当然,在这个过程中,外生变量是可以放进来的,假设我们的encoder部分的输入的序列数据是[5,4,3,2,1,0]对应t-5到t,外生变量是[a5,b5,c5]…[a0,b0,c0],则encoder部分的输入数据的形式就是[5,a5,b5,c5]…[0,a0,b0,c0],decoder部分的初始输入是t时刻的特征即[0,a0,b0,c0],我们在decoder的t时刻部分产生了t+1时刻的预测 t+1_pred,然后我们将t+1_pred和t+1时刻的可推断特征(例如城市,省份,店铺,品类,月份,星期等)合并得到了[t+1_pred,a-1,b-1,c-1],作为t+2时刻的输入特征帮助预测t+2,依次类推。
由于这种递归式的训练很容易产生误差累积的问题,即如果t+1的预测误差大,则后续的decoder都是在错误的预测结果上继续训练的,所以更常见的训练方式是使用teacher forcing:
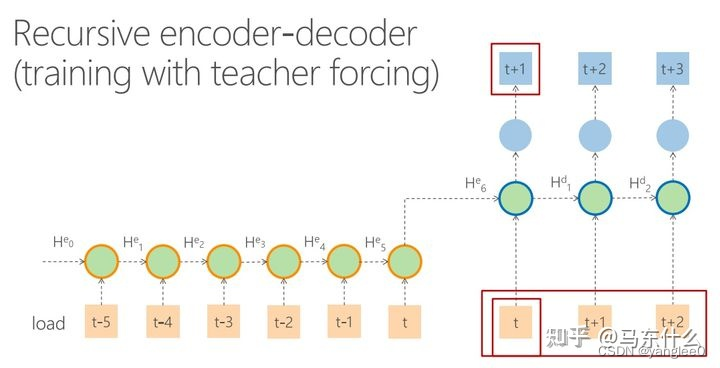
decoder的时候直接使用真实的值帮助模型训练。
而常规的LSTM是直接做的向量输出:
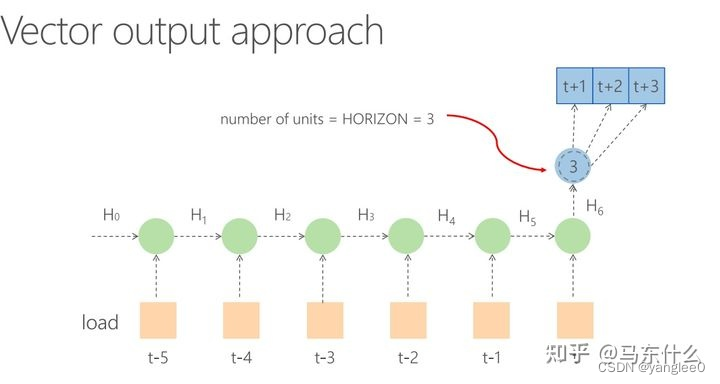
seq2seq式的encoder-decoder结构相对于LSTM这样单一的encoder的结构有两个好处:
-
1、seq2seq可以支持不定长的输入和输出,而单一的encoder结构只能支持不定长输入无法支持不定长的输出,因为单一的encoder结构最终是通过一个固定的dense层完成预测任务的,dense层的size是固定不变的;
-
2、seq2seq的训练过程可以使用到未来的特征,当然这些特征必须是可以推断的(前面描述过过了),这可能可以帮助模型更好的学习。

即deepar中,encoder和decoder使用的是同一个RNN模型,这个RNN模型就是常规意义上的RNN模型,可以是单层的LSTM或多层的LSTM。
那么deepar的模型是怎么训练的?和使用teacher forcing的seq2seq一样,deepar的训练和预测过程是不一样的,基于teacher forcing训练策略的seq2seq训练的时候用到了真实的标签,但是预测的时候我们是没有真实标签可用的,因此这类seq2seq预测的行为退化为了普通的recursive seq2seq:
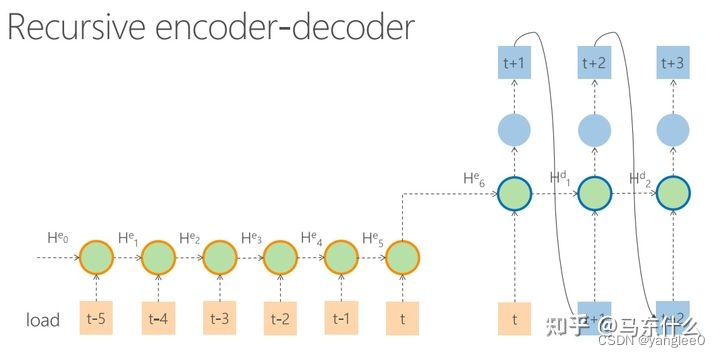
在代码实现上也比较麻烦,我们需要手动写decoder部分的循环(不知道有没有什么方便的开源可以实现这个功能,没有找过)
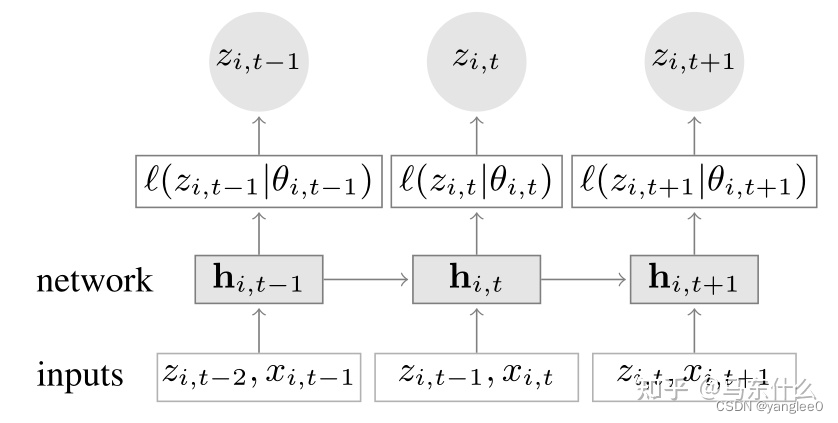
deepar的训练过程如上,其实去掉中间L的部分,deepar看起来就是一个LSTM,为了方便描述,中间部分暂时先不考虑,看一下deepar的输入和输出是什么
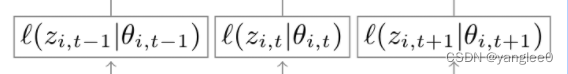
输入部分:Xi,(t-1),即t-1时刻的外生变量,即可推断的特征,比如前面说过的城市,省份,店铺,品类,月份,星期等,Zi,(t-2),即t-2时刻的标签,比如商品的销量(也就是我们想要预测的目标),通过一个RNN cell得到 t-1时刻的表征,然后接一个dense(1)的层得到Zi,(t-2),依次类推。其中t-1,t和t+1都是我们需要预测的标签,和teacher forcing seq2seq一样,训练的过程中,待预测的标签被放进来用于模型训练了。
然后在预测阶段:
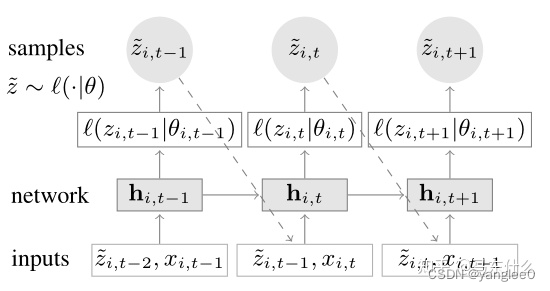
和recursive seq2seq一样,进行迭代预测,这种预测方式可以预测无限长的序列,只不过当预测的序列变长之后精度往往很差,这也是时序预测问题的一个挑战,长时序的预测如何保证精度的问题,和本文无关,不废话。
2、概率部分
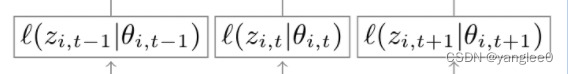
当然deepar没这么简单,deepar的设计本身不是针对点预测,而是针对概率预测的。主要问题在于,怎么用nn来对标签的概率分布直接进行建模。
如果熟悉贝叶斯深度学习,对这一套操作应该会比较熟悉了:


总结一下,对于一个时序样本来说,这个时序样本包含了n个time step的时间切片,进入了network(这个network是可以处理序列数据的网络结构例如LSTM,CNN,seq2seq的网络机构或者Transformer)处理之后,吐出了n个新的序列,然后这个序列分别接两个dense层,两个dence层的神经元数量均为1,一个dense层用于拟合人为指定的高斯分布的u均值,一个用于拟合认为指定的高斯分布的标准差sigma,然后为了避免sigma小于0,使用softplus,即log(1+e**x)来保证sigma大于0。这里的两个dense层被封装到一个layer,我们称这个layer为gaussian layer,专门用于拟合高斯分布的特殊网络层。
3、模型训练:
原文的实验设计有几个地方需要注意:
第一:缺失值用0填充
第二:在nlp中,seq2seq使用teacher forcing有一个问题,就是模型训练和预测行为的不一致会导致模型的泛化性能下降,但是deepar的论文里提到他们没有遇到这个问题。
第三:关于缩放的问题,考虑到模型的输入是多个时间序列,这些时间序列的量级可能并不一样,因此我们需要对它们做放缩,对于每一个时间序列i,都对应有一个放缩因子(from 段易通:概率自回归预测——DeepAR模型浅析)
可以看到,这里的处理其实就是每个时间序列做分组标准化,每个时序数据除以自己的均值,为了避免均值为0,所以对均值+1避免除0的问题。
原文中还提到了关于负二项似然的分布假设,没怎么用过,所以不想看了。。到时候有需要再看好了,问题不大。
第四:关于采样的问题
这个工程技巧很有意思,原文中的意思是,我们对于销量数据比较全,也就是比较热门,上了比较久的商品的预测更看重,而对于冷门商品,销量数据很少或者是新商品则其重要性相对低一些,所以选择有权采样的方式进行采样,关于时序数据的采样,文中的意思是这样的,比如假设我们的training window是100,prediction window是20,那么实际上每一次入模的样本总的长度是120,正常的操作是我们要从某个商品的历史数据中对数据进行切分,比如某个商品的时序数据的长度一共是1000,则这个商品的序列数据可以拆分为多条样本,按照文中加权采样的意思,对于热门的商品采样的权重更大,即这种商品的序列数据会更频繁的出现在训练数据中。
第五:特征工程
特征工程这块儿就没什么特别的,日期特征,一些静态特征的处理之类的和常规的时序数据的特征工程没有太大区别,最后都进行了standardscaler标准化
第六:损失函数是啥?
我们前向传播,将每一个样本映射为了 u和sigma两个值,那么怎么和实际的标签y关联起来,显然我们这个时候没有办法使用常规的用于回归的loss,比如mae,mape,mse之类的,因为这类损失函数无法处理 u,sigma,y_true 三个输入的关系。这块儿的loss设计也非常直观,我们高中的时候,高斯分布的均值和方差是有公式的,其推导过程如下

就是最大似然估计,如果从nn的角度来看,我们就是希望能够让:
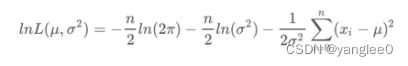
这个式子越小越好,那好办,我们直接带入这个公式就可以了,于是就有

最后,前向传播和损失函数都已经完事儿了,来看下模型是怎么预测的。
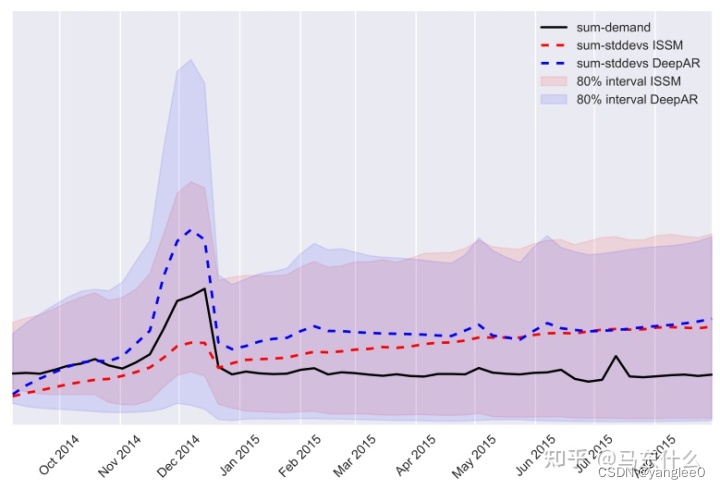
现在我们直接进行predict一个样本a1,得到的不是y1,而是y1所在的高斯分布的u和sigma(对于每一个y,其所在的高斯分布都是不同的,这一点非常重要,我们是认为每一个观测点服从的高斯分布都是不同的,(学完deepar,对贝叶斯统计和贝叶斯深度学习的理解会有一定的帮助),如果某个y的sigma很大,则这个y的预测的不确定性很高,我们可以很容易画出不确定性的预测结果如下图:
一般来说,我们得到了高斯分布的均值和方差,则直观的思路是用高斯分布的期望值,
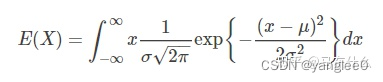
但是实际上,我们的所谓的高斯分布的估计都仅仅是建立在一个样本上的而已,无论是训练还是预测都一样,一个样本就对应一个mu和一个sigma,即一个样本就对应一个特定的基于该样本的高斯分布,直接使用均值会一个问题:
这个均值不准,根据期望公式可以知道,高斯分布的期望的计算其实就是采样一个x,计算这个x的概率密度,然后相乘,然后累加进来,其实就是加权求和,因为x的取值是无限的在正负无穷之间,所以通过积分公式来计算,但是实际上我们不必高斯分布的取值范围里所有的点,我们只需要使用置信度高的点就可以了,那么实现的方法也很简单:
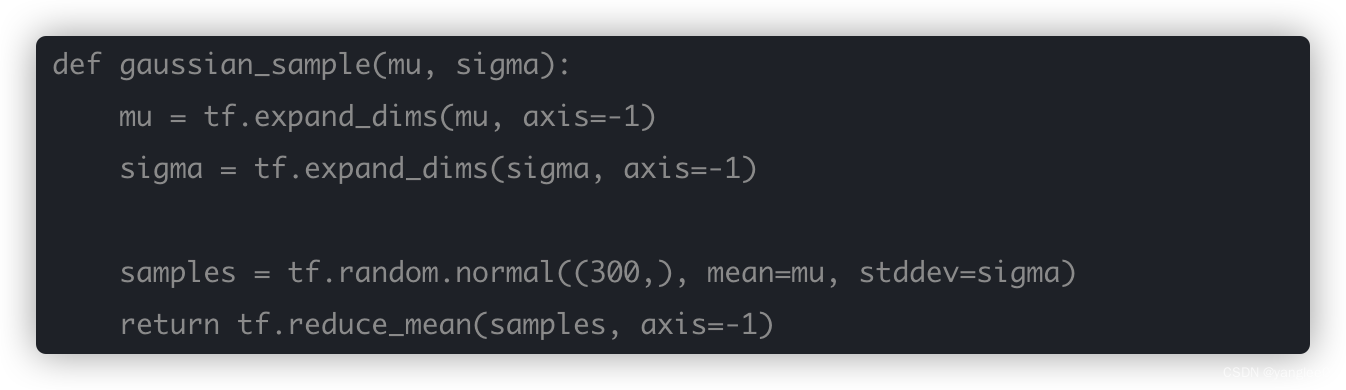
既然有了均值和方差,那么就从这个分布里随机采样出一些点直接做平均。这里的代码设计是采样300个点。实际使用的话,可以调整。
注意:
deepar的设计是非常灵活的,但是局限的地方在于,比如上面,我们优化的是gaussian_loss,并不是直接优化mape,rmse这类的损失函数,所以相对来说,没有办法直接去优化我们的业务指标。除此 之外,如果假定的其它分布,则最终的输出层需要做修改,比如possion分布,tweetie 分布,需要实现了解这些分布的参数,然后相应地去设计输出层。

















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









