







目录
2、Homography、Essential和Fundamental Matrix相关问题
2.1 Homography、Essential和Fundamental Matrix的区别
2.2 本质矩阵E、基础矩阵F,单应矩阵H,自由度分别是多少?为什么?
2.3 ORB-SLAM初始化的时候为什么要同时计算H矩阵和F矩阵
4、什么是紧耦合、松耦合?优缺点。引申问题:视觉与IMU进行融合后有何优势?
12、安装2D Lidar的平台匀速旋转的时候,去激光数据数据畸变,写代码。
18、给一张图片,知道相机与地面之间的相对关系,计算出图的俯视图。
20.1 什么是ORB特征?ORB特征的旋转不变性是如何做的?BRIEF算子是怎么提取的?
20.2 ORB-SLAM中的特征是如何提取的?如何均匀化的?
25.1 什么是RANSAC算法?该算法有什么用?假如数据中有一半数据都是错误的,使用RANSAC能够得到正确的结果吗?
26、如果对于一个3D点,我们在连续帧之间形成了2D特征点之间的匹配,但是这个匹配中可能存在错误的匹配。请问你如何区构建3D点?
27、SLAM后端有两种方法:滤波方法和非线性优化方法,这两种方法有什么优缺点?
1、室内SLAM与自动驾驶SLAM有什么区别?
这是个开放题,参考无人驾驶技术与SLAM的契合点在哪里,有什么理由能够让SLAM成为无人驾驶的关键技术?都属于SLAM的问题范畴,但应用场景不同,技术上的侧重点也不同。

参考https://www.bilibili.com/video/BV17X4y1w7yL高翔老师《智行者SLAM专家高翔博士:室内无人车和室外无人车有什么区别》
室内更倾向于叫机器人,室内的特点一是面积比较小,二是没有什么交通规则,也就是说室内大部分空的地方都可以过去,并不存在室内某条路必须沿着右边开这样的交通规则。
室外来讲,交通规则会限制车的实际运动走向。室外也会分结构化和非结构化两部分,结构化就是交通规则更加强一些,非结构化也会有交通规则,比方说有个门开着但是不能进。总体来说,室内的交通规则相对来说是可控的,室外乘用车走的结构化道路是目前为止最复杂的,园区相对简单但也有一些交通规则。
交通规则方面很难说让一个机器人去自动识别各种交通规则,只能人工指定在这部分地图中,机器人必须这么走。因此室内SLAM方案或者地图方案就会简单很多,甚至直接在线建立一个障碍物地图。
室外可能还需要支持线上的一些高精地图的东西,你的方案会从一个在线的方案变成离线的方案,很有可能还要带很多标注的方案。
1.1 无人驾驶技术与SLAM的契合点在哪里?
SLAM传统上还是面向室内等缺少GPS信号的应用,例如室内移动机器人导航,而在无人驾驶汽车上,它的意义和作用是什么,已经有高精度的地图和城市GPS信号了,那就是说SLAM只是为了感知么?
最初,SLAM的提出就是为了解决未知环境下移动机器人的定位和建图的问题。所以,笼统的说,SLAM对于无人驾驶的意义就是如何帮助车辆感知周围环境,更好的完成导航、避障、路径规划等高级任务。
现在已经有高精度的地图,暂且不去考虑这个地图的形式、存储规模和如何用它的问题。首先,这个构建好的地图真的能帮助无人驾驶完成避障或者路径规划等的类似任务吗?至少环境是动态的,道路哪里有一辆车,什么时候会出现一个行人,这些都是不确定的。所以从实时感知周围环境这个角度来讲,提前构建好的地图是不能解决这个问题的。
另外,GPS的定位方式是被动的、依赖信号源的,这一点使得其在一些特殊场景下是不可靠的,比如城市环境中GPS信号被遮挡,野外环境信号很弱,还有无人作战车辆作战中信号被干扰以及被监测等。
所以像视觉SLAM这种主动的并且无源的工作方式在上述场景中是有优势的。从硬件角度讲,目前主流的视觉SLAM方案,在构建低成本,小型化,易于搭载的硬件平台方面也是有优势的。
1.2 有什么理由能够让SLAM成为无人驾驶的关键技术?
- 我个人不是很赞同这个逻辑。SLAM作为一个很庞杂的系统,其本身也有很多关键环节和实际应用中会遇到的难题,作为一种应用场景越来越广泛的技术(如自动机器人,无人机,无人驾驶,AR),它可能永远不会成为无人驾驶的关键技术,与其思考这个问题,不如关注SLAM本身,即围绕定位和建图这两个基本任务,来想想
- 里程计是不是可以估计的更准确,
- 环境地图信息是不是可以建立得更丰富(比如有用的语义信息),
- 场景识别/闭环检测是不是能保证更高的准确率和召回率,
- 是不是可以借助其他传感器完善SLAM系统,
接下来在想想SLAM能帮助无人驾驶做些什么?只有技术越来越完善和成熟,才能被应用到更多的实际场景中。
2.我想SLAM真正能发挥作用的区域是last mile或者一些高精度地图覆盖不到的非结构化环境。
2、Homography、Essential和Fundamental Matrix相关问题
2.1 Homography、Essential和Fundamental Matrix的区别
Homography Matrix可以将一个二维射影空间的点变换该另一个二维射影空间的点,如下图所示,在不加任何限制的情况下,仅仅考虑二维射影空间中的变换,一个单应矩阵H可由9个参数确定,减去scale的一个自由度,自由度为8。
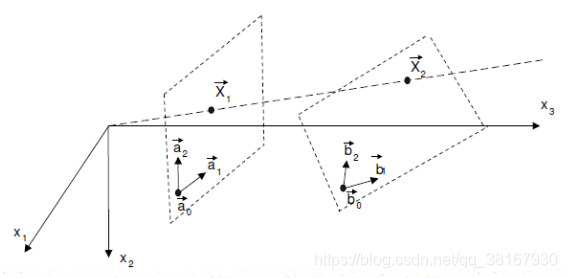
Fundamental Matrix对两幅图像中任何一对对应点x 和x′,基础矩阵F都满足条件:
![]()
秩只有2,因此F的自由度为7。它自由度比本质矩阵多的原因是多了两个内参矩阵。
Essential matrix:本质矩是归一化图像坐标下的基本矩阵的特殊形式,其参数由运动的位姿决定,与相机内参无关,其自由度为6,考虑scale的话自由度为5。
参考多视图几何总结——基础矩阵、本质矩阵和单应矩阵的自由度分析。
2.2 本质矩阵E、基础矩阵F,单应矩阵H,自由度分别是多少?为什么?
先说结论,基础矩阵F有7个自由度,本质矩阵E有5个自由度,单应性矩阵H有8个自由度。
矩阵的自由度是指:想要解矩阵中的未知参数,需要通过列几个线性方程组才能完全解出参数?对于n*n的矩阵,如果该矩阵存在k个约束,那么其自由度为n*n-k。
- 本质矩阵E=t^R:6-1=5,尺度等价性。怎么理解这里的尺度等价性?本质矩阵是由对极约束定义的。由于对极约束是等式为零的约束,所以对E乘以任意非零常数后,对极约束依然满足。我们把这件事情称为E在不同尺度下是等价的。此外,本质矩阵E的奇异值是[σ,σ,0]T的形式,这是本质矩阵的内在性质。
- 单应性矩阵H:9-1=8,单应矩阵Homography,通常我们说它都是说二维平面到二维平面的映射,其实Homography是n维射影空间之间最通常的变换的统称,这类变换的一个特征是在齐次坐标的基础上进行,因此它的维数是(n+1)^2,它是最通常的,所以我们能想到自由度就是(n+1)^2,而齐次坐标存在尺度模糊,所以要在此基础上减掉1,放在2维空间的话就是(2+1)^2 - 1 = 8。
- 基础矩阵F:9-2=7,尺度等价性 + 秩为2(不满秩),
,其中p是像素点坐标。一般解释F是有7个自由度,是说它有个约束秩为2/行列式为0,所以在单应基础上再减1。
2.3 ORB-SLAM初始化的时候为什么要同时计算H矩阵和F矩阵
简单地说,因此初始化的时候如果出现纯旋转或者所有特征点在同一个平面上的情况,F矩阵会发生自由度的退化,而这个时候H矩阵会有较小误差,因此要同时计算H矩阵和F矩阵,那么这里补充两个问题:
(1)ORB SLAM是怎样选用哪个矩阵去恢复旋转和平移的呢?
这部分代码是这样的:
// Compute ratio of scores
float RH = SH / (SH + SF);
// Try to reconstruct from homography or fundamental depending on the ratio (0.40-0.45)
if (RH > 0.40)
return ReconstructH(vbMatchesInliersH, H, mK, R21, t21, vP3D, vbTriangulated, 1.0, 50);
else //if(pF_HF>0.6)
return ReconstructF(vbMatchesInliersF, F, mK, R21, t21, vP3D, vbTriangulated, 1.0, 50);计算SF和SH的公式如下:
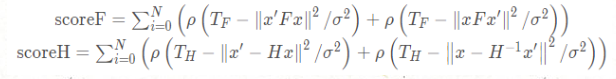
其中:
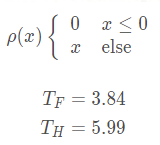
然后SH和SF的比值公式如果结果大于0.4的话就选择H矩阵,如果小于0.4的话就选择F矩阵来进行初始化。
(2)F矩阵退化会发生在哪些情况下?
F矩阵会在两种条件下发生退化,准确地说是三种,第一种是发生在仅旋转的情况下,第二种是发生在所有空间点共面的情况下,第三种是所有空间点和两个摄像机中心在一个二次曲面上,有可能发生退化(第三种情况暂时不予讨论,可参看《多视图几何》一书),下面我们来看下他们为什么会退化:
第一种情况:仅发生旋转,这个比较好理解,基础矩阵满足:
![]()
在这种情况下,t 是零向量,此时求得的基础矩阵是零矩阵,因此无法通过下面的公式求得基础矩阵:![]()
第二种情况:所有空间点在一个平面上,这种情况下,匹配点的点集X i ↔ X i ′满足射影变换,即xi′=Hxi,这时基础矩阵的方程变为:
![]()
,注意这时只要FH^(−1)是一个任意的反对称矩阵都满足这个方程,因此F 矩阵可以写成:
![]()
S为任意的反对称矩阵,因此这种情况下只能求出来的F矩阵是一个三参数簇,而不是一个具体的解。
这里再补充一点,我们还要区分好退化和简化的区别,什么情况下会发生F矩阵的简化呢?
第一种情况:纯平移运动(就是沿着相机坐标系的z轴运动),这种情况下F矩阵简化成了一个反对称矩阵,并且只有两个自由度(反对称矩阵并且尺度不变性),因此两组匹配点就可以求解这种情况,因此这种情况下,上面退化的第二种情况就不会发生了,因为两组匹配点构成的两个空间点肯定都是共面的。
第二种情况:纯平面运动(就是沿着相机坐标系的x轴运动),这种情况下F矩阵的对称部分秩为2(具体为什么可能需要查资料推导了),所以会在原本的F矩阵上再添加一个约束,使得自由度变成六个自由度。
第三种情况:标定之后的情形,其实就是F矩阵在把内参获得之后就变成了E矩阵,自由度变成五个自由度,这个没什么好说的。
2.4 计算H矩阵和F矩阵的时候有什么技巧呢?
第一个是RANSAC操作,第二个是归一化操作,RANSAC操作前面已经解释过了,这里主要来分析下归一化操作,在《多视图几何》中提到了一种归一化八点法,方法是先用归一化矩阵对图像坐标进行平移和尺度缩放,然后利用八点法求解单应或者基础矩阵,最后再利用归一化矩阵恢复真实的单应或者基础矩阵,归一化具体操作和优势如下:
具体操作:又称各项同性缩放(非同性缩放有额外开销,但是效果并未提升),步骤如下:
(1)对每幅图像中的坐标进行平移(每幅图像的平移不同)使点集的形心移至原点
(2)对坐标系进行缩放使得点x = ( x , y , w ) 中的x , y , w总体上有一样的平均值,注意,对坐标方向,选择的是各向同性,也就是说一个点的x 和y 坐标等量缩放
(3)选择缩放因子使得点x \mathbf{x}x到原点的平均距离等于√2
优势:
(1)提高了结果的精度;
(2)归一化步骤通过为测量数据选择有效的标准坐标系,预先消除了坐标变换的影响,使得八点法对于相似变换不变。
2.5 附代码计算H和F矩阵
代码如下,参见《SLAM 14讲》pose_estimation_2d2d.cpp:
// 使用对极约束计算变换关系R,t
void pose_estimation_2d2d( std::vector<KeyPoint> keypoints_1,
std::vector<KeyPoint> keypoints_2,
std::vector< DMatch > matches,
Mat& R, Mat& t )
{
// 相机内参, TUM Freiburg2
Mat K = ( Mat_<double> (3,3) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );
// 把匹配点转换为vector<Point2f>的形式
vector<Point2f> points1;
vector<Point2f> points2;
for ( int i=0; i<(int)matches.size(); i ++ ) // 81组匹配点
{
points1.push_back( keypoints_1[matches[i].queryIdx].pt );
points2.push_back( keypoints_2[matches[i].trainIdx].pt );
}
// queryIdx : 查询点的索引(当前要寻找匹配结果的点在它所在图片上的索引).
// trainIdx : 被查询到的点的索引(存储库中的点的在存储库上的索引)
// imgIdx : 有争议(常为0)
// 计算基础矩阵:基础矩阵是根据 像素坐标系 下的像素直接计算
//! the algorithm for finding fundamental matrix
// enum { FM_7POINT = 1, //!< 7-point algorithm
// FM_8POINT = 2, //!< 8-point algorithm
// FM_LMEDS = 4, //!< least-median algorithm. 7-point algorithm is used.
// FM_RANSAC = 8 //!< RANSAC algorithm. It needs at least 15 points. 7-point algorithm is used.
// };
Mat fundamental_matrix;
fundamental_matrix = findFundamentalMat( points1, points2, CV_FM_8POINT ); // FM_RANSAC
// fundamental_matrix = findFundamentalMat( points1, points2, FM_RANSAC );
cout << "fundamental_matrix is " << endl << fundamental_matrix << endl;
// 计算本质矩阵 :根据 相机坐标系 下的 坐标 计算,需要像素坐标转换
Point2d principal_point(325.1, 249.7); // 相机光心, TUM dataset标定值,内参矩阵K中的cx和cy
double focal_length = 521; // 相机焦距, TUM dataset标定值
Mat essential_matrix;
essential_matrix = findEssentialMat( points1, points2, focal_length, principal_point );
cout << "essential_matrix is " << endl << essential_matrix << endl;
// 计算单应矩阵:单应矩阵描述处于共同平面上的一些点在两张图像之间的变换关系,作为基础矩阵的补充
Mat homography_matrix;
homography_matrix = findHomography( points1, points2, RANSAC, 3 );
cout << "homography_matrix is " << endl << homography_matrix << endl;
// 从本质矩阵中恢复旋转和平移信息
recoverPose( essential_matrix, points1, points2, R, t, focal_length, principal_point );
cout << "R is " << endl << R << endl;
cout << "t is " << endl << t << endl;
}注意两个矩阵的解法不同,一个是8点法,一个是RANSAC。
3、为什么协方差矩阵是半正定的?

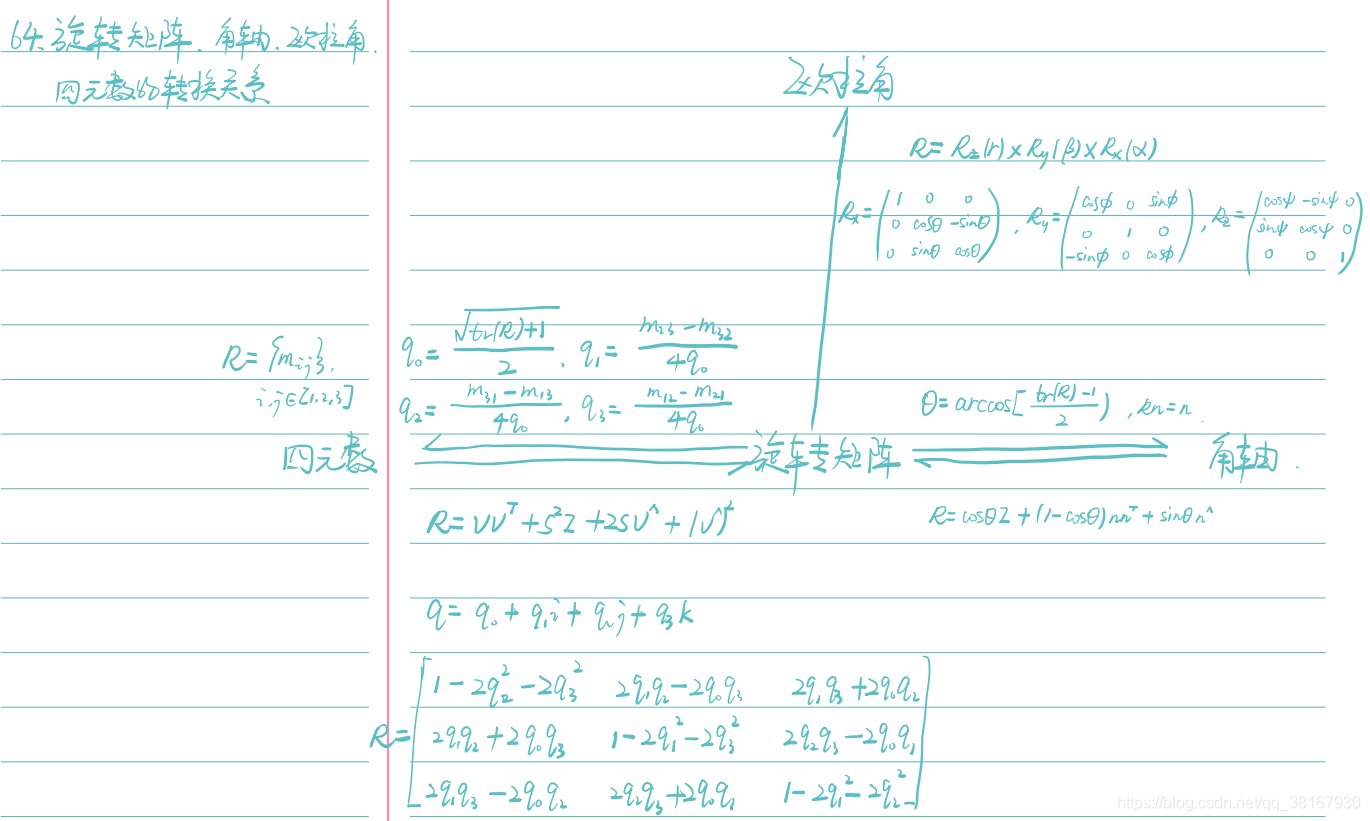
4、什么是紧耦合、松耦合?优缺点。引申问题:视觉与IMU进行融合后有何优势?
这里默认指的是VIO中的松紧耦合,这里参考深蓝学院的公开课里面介绍:
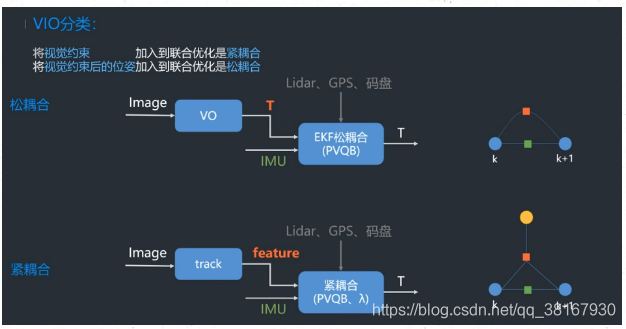
4.1 松耦合
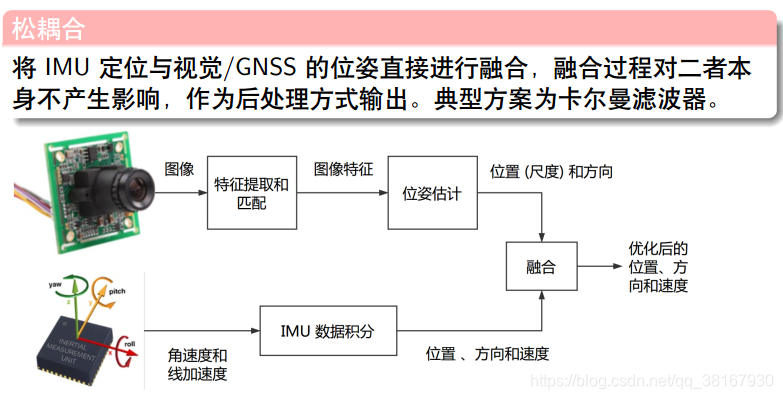
松耦合是把VO处理后获得的变换矩阵和IMU进行融合,这样做优点是计算量小但是会带来累计误差。
4.2 紧耦合
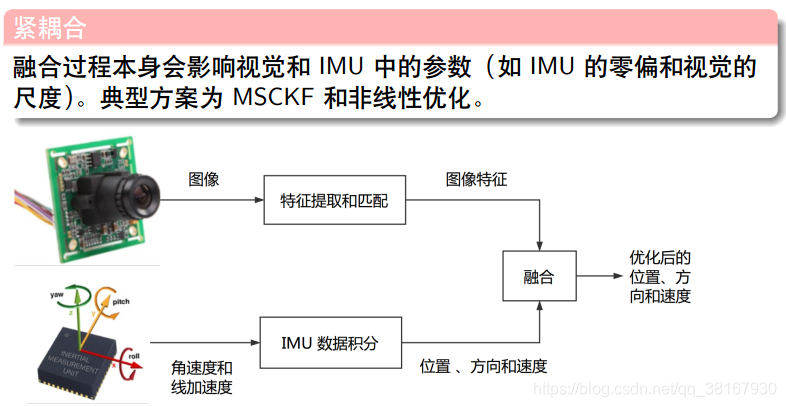
紧耦合是把图像的特征加到特征向量中去,这样做的优点是可以免去中间状态的累计误差,提高精度,缺点是系统状态向量的维数会非常高,需要很高的计算量。
4.3 为什么要使用紧耦合?
- 单纯凭(单目)视觉或IMU都不具备估计Pose的能力:视觉存在尺度不确定性、IMU存在零偏导致漂移;
- 松耦合中,视觉内部BA没有IMU信息,在整体层面来看不是最优的。
- 紧耦合可以一次性建模所有的运动和测量信息,更容易达到最优。
也可以说:视觉和IMU融合后有什么好处?

综上:
- IMU适合计算短时间、快速的运动
- 视觉适合计算长时间、慢速的运动
- 可利用视觉定位信息来估计IMU的零偏、减少IMU由零偏导致的发散和累计误差
- IMU可以为视觉提供快速运动时的定位
4.4 VIO框架分类

MSCKF:紧耦合,FAST+光流前端;后端用重投影误差,无回环检测
OKVIS:紧耦合,前端使用多尺度Harris提取特征点,使用BRISK作为描述子,后端使用ceres进行非线性优化完成状态估计。
ROVIO:紧耦合,基于稀疏图像块的EKF滤波实现VIO,基于单目的,前端是用FAST+光流,后端是EKF滤波。
VINS:紧耦合,前端Harris+光流,有回环检测,通过非线性优化一个滑窗内的KF等。
5、求导∂R1R2 / ∂R1
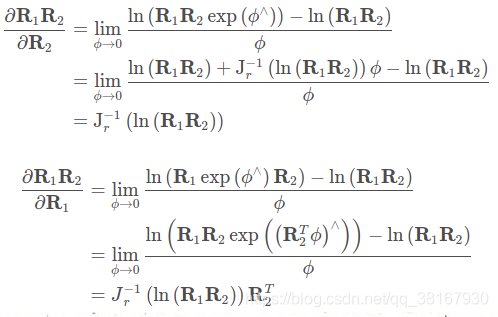
6、李群和李代数的关系
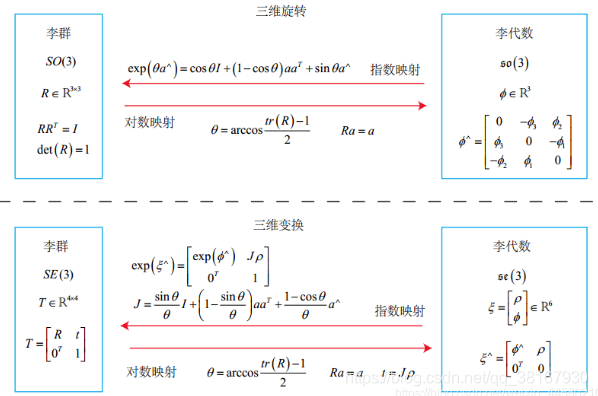
如上图所示(摘自《视觉SLAM十四讲》),从李群到李代数是对数映射,形式上是先取对数,然后取∨,从李代数到李群是对数映射,形式上先取∧ ,再取指数,下面具体说:
三维旋转:李群就是三维旋转矩阵,李代数是三维轴角(长度代表旋转大小,方向代表旋转轴方向),从李群到李代数是分别求轴角的角θ(通过矩阵的迹求反余弦)和向量 a(旋转矩阵特征值1对应的特征向量),从李代数到李群就是罗德罗杰斯公式。
三维变换:李群是四元变换矩阵,李代数是六维向量(前3维平移
,后3维旋转
),从李群到李代数同样先求角和向量,然后需要求 t,从李代数到李群的话通过上面的公式计算。
7、介绍一下你熟悉的非线性优化库
7.1 g2o
7.2 ceres
8、PnP算法相关
8.1 描述PnP算法
已知空间点世界坐标系和其像素投影,公式如下:
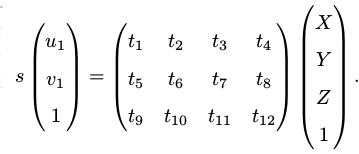
目前一共有两种解法,直接线性变换方法(一对点能够构造两个线性约束,因此12个自由度一共需要6对匹配点),另外一种就是非线性优化的方法,假设空间坐标点准确,根据最小重投影误差优化相机位姿。
目前有两个主要场景场景,其一是求解相机相对于某2维图像/3维物体的位姿;其二就是SLAM算法中估计相机位姿时通常需要PnP给出相机初始位姿。
在场景1中,我们通常输入的是物体在世界坐标系下的3D点以及这些3D点在图像上投影的2D点,因此求得的是相机坐标系相对于世界坐标系(Twc)的位姿。
在场景2中,通常输入的是上一帧中的3D点(在上一帧的相机坐标系下表示的点)和这些3D点在当前帧中的投影得到的2D点,所以它求得的是当前帧相对于上一帧的位姿变换。
PnP是求解3D到2D点对运动的方法,即问题描述为,我们的已知条件是n个3D空间点以及它们作为特征点的位置(以归一化平面齐次坐标表示),我们求解的是相机的位姿R , t ,如果3D空间点的位置是世界坐标系的位置,那么这个R , t 也是世界坐标系下的。特征点的3D位置可以通过三角化或者RGBD相机的深度图确定。
PnP从n个3D空间点及其投影位置中估计相机的位置,可以在很少的匹配点中获得较好的运动估计,求解方法有DLT、P3P、EPnP,UPnP等。
a. DLT是通过定义包含旋转与平移信息的增广矩阵,最少通过6对匹配点求解,求解后的结果要投影到SE(3)流形上。
b. P3P是通过3对3D-2D匹配点和一对验证点,利用三角形相似性质,求解投影点在相机坐标系下的3D坐标,转为3D-3D的位姿估计问题。
(1)直接线性变换方法
根据推导,一对特征点(一个3D点加一个2D点)可以提供两个线性约束,因此12维的齐次变换矩阵需要6对特征点。 《SLAM14讲》 P158
(2)P3P算法
P3P的作用是将利用三对特征点,讲空间点在世界坐标系下的坐标,转换到像极坐标系中的坐标,将PnP问题转化为ICP问题,推导过程是利用三角形特征完成的。
(3)Bundle Adjustment方法
其本质是一个最小化重投影误差的问题,公式如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











