










论文地址:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
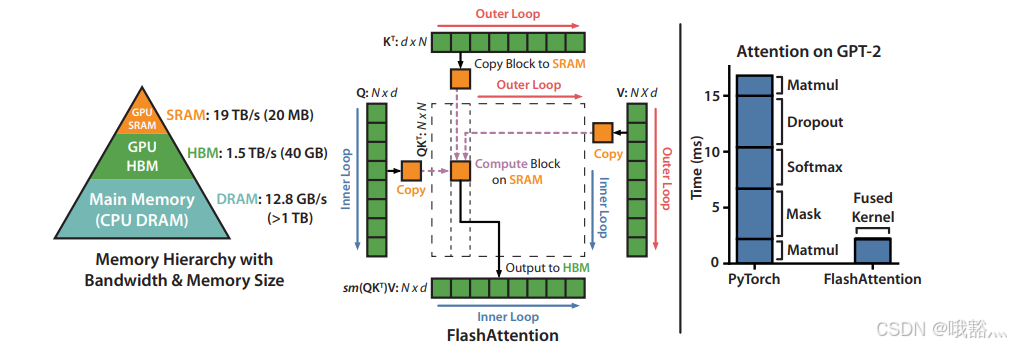
如上图所示,Flash-attention 采用了矩阵分块和算子融合(safe softmax reducetion)的方法,尽可能的减少内存的 IO 时间,最大化利用 GPU 硬件中的共享内存,减少去 HBM 中进行内存的搬运等操作。在长序列的 LLM 推理任务中,能够有效的减少推理的时间,尤其是 prefill 阶段。
1 计算复杂度分析
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax \left( \frac{QK^T}{\sqrt{d_k}} \right)V Attention(Q,K,V)=softmax(dkQKT)V
flashattention 计算注意力的 IO 复杂度为 O ( N 2 d 2 M − 1 ) O(N^2 d^2 M^{-1}) O(N2d2M−1),其中 d 是 head_dimension ,M是 SRAM 的大小,标准注意力的复杂度 O ( N d + N 2 ) O(Nd + N^2) O(Nd+N2), 考虑到 M 的值相比 d 通常大很多,因此前者的复杂度远远小于后者,且 SRAM 越大越明显。
1.1 Naive Attention 内存加载流程
- 从 HBM 加载 Q, K , 计算 S = Q K T S = QK^T S=QKT , 将 S 写回 HBM, N d + N 2 Nd + N^2 Nd+N2
- 从 HBM 读取 S, 计算 P = s o f t m a x ( S ) P = softmax(S) P=softmax(S), 将 P 写回 HBM, 这一步 2 N 2 2N^2 2N2
- 从HBM读取 P、V, 计算 O = P V O = PV O=PV, 将 O 写回到 HBM, 这一步的访问次数为 N 2 + 2 N d N^2 + 2Nd N2+2Nd,
- 返回计算结果 O
总的注意力访问次数为 3 N d + 4 N 2 3Nd + 4N^2 3Nd+4N2, 5 次 HBM 读取,3 次 HBM 写入。
FlashAttention 的总访问次数为 N 2 d 2 M \frac{N^2 d^2}{M} MN2d2。
2 Flash-attention 流程
flash attention 将 online-softmax 和矩阵分块结合起来计算 attention,将本来不能分块的 row 可以拆分成多个更细粒度的 Block。
算法思想:
- 减少 HBM 的访问,将 QKV 切分为小块后放入 SRAM 中
- tiling, recomputation
2.1 tiling(平铺): 分块计算
因为 Attention 计算中涉及 Softmax,所以不能简单的分块后直接计算。
softmax 计算方法:
s o f t m a x ( x j ) = e x j ∑ i = 1 k e x i softmax(x_j) = \frac{e^{x_j}}{\sum _{i=1} ^k e^{x_i}} softmax(xj)=∑i=1kexiexj
softmax 操作是 row-wise 的,即每行都算一次 softmax,所以需要用到平铺算法来分块计算 softmax。
注意力机制的计算过程是:
矩阵乘法 --> scale --> mask --> softmax --> dropout --> 矩阵乘法
矩阵乘法和逐点操作(scale,mask,dropout)的分块计算是容易实现的,难点在于 softmax 的分块计算。由于计算 softmax 的归一化因子(分母)时,需要获取到完整的输入数据,进行分块计算的难度比较大。
2.2 safe softmax
原始 softmax 数值不稳定。在实际硬件中,浮点数表示的范围是有限的,对于 float32 和 bfloat16 来说,当
x
≥
89
x \geq 89
x≥89 时,
e
x
e^x
ex 就会变得很大甚至变成inf,发生数据上溢的问题。为了避免发生数值溢出的问题,保证数值稳定性,计算时通常会减去最大值,称为safe softmax。
FlashAttention 采用 safe softmax:
m ( x ) = m a x ( [ x 1 , x 2 , ⋯ , x d ] ) m(x) = max([x_1, x_2, \cdots, x_d]) m(x)=max([x1,x2,⋯,xd])
s o f t m a x ( x j ) = e x j − m ( x ) ∑ i = 1 k e x i − m ( x ) softmax(xj) = \frac{e^{x_j - m(x)}}{\sum _{i=1} ^k e^{x_i - m(x)}} softmax(xj)=∑i=1kexi−m(x)exj−m(x)
这里通过引入 m ( x ) m(x) m(x),不仅能够一定程度上解决 softmax 的数值稳定性问题,还 使得在不同的 block 间汇总计算 softmax 成为了可能。
2.3 recomputation(重计算)
FlashAttention 算法的目标:在计算中减少显存占用,从 O ( N 2 ) O(N^2) O(N2) 大小降低到线性,把数据加载到 SRAM 中,提高 IO 速度。
传统 Attention 在计算中需要用到 Q,K,V 去计算 S,P 两个矩阵,FlashAttention 引入 softmax 中的统计量 ( m , l ) (m, l) (m,l) ,结合 output O 和在 SRAM 中的 Q,K,V 块进行计算。


















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









