







一 摘要
通过研究对抗攻击可以更好的了解神经网络,并且提高深度学习模型的鲁棒性。在这篇论文中,提出了一个cooling-shrinking攻击,可以攻击最新的SiamRPN网络。通过本文设计的对抗扰动,可以在冷却目标所在位置的热力图的同时,收缩预测的边界框,让被追踪物体无法被追踪。本文攻击模型可以在OTB100,VOT2018以及LaSOT这几个数据集上取得很好的效果。并且,本文的方法有着很好的迁移性,也可以很好的欺骗DaSiamRPN,DaSiamRPN-UpdateNet和DiMP。论文提供了源码:https://github.com/MasterBin-IIAU/CSA 后面可能会认真对比源码看看论文的整体思路。
二 知识点补充
1.原始追踪算法
原始的追踪算法包括生成式模型和判别式模型。生成式模型首先建立目标模型或者提取目标特征, 在后续帧中进行相似特征搜索.逐步迭代实现目标定位.但是这类方法也存在明显的缺点, 就是图像的背景信息没有得到全面的利用。判别式模型是指, 将目标模型和背景信息同时考虑在内, 通过对比目标模型和背景信息的差异, 将目标模型提取出来, 从而得到当前帧中的目标位置。
传统的目标跟踪算法存在两个致命的缺陷:
(1)没有将背景信息考虑在内, 导致在目标遮挡, 光照变化以及运动模糊等干扰下容易出现跟踪失败。
(2)跟踪算法执行速度慢(每秒10帧左右), 无法满足实时性的要求。
2.相关滤波算法
之后出现了基于核相关滤波的跟踪算法。相关滤波器(Correlation Filter)通过MOSSE(Minimum Output Sum of Squared Error (MOSSE) filter)算法实现,基本思想:越是相似的两个目标相关值越大,也就是视频帧中与初始化目标越相似,得到的相应也就越大。本文的SiamRPN系列就是这种基于相关滤波的。
3.深度学习算法
随着深度学习方法的广泛应用, 人们开始考虑将其应用到目标跟踪中。人们开始使用深度特征并取得了很好的效果。在大数据背景下,利用深度学习训练网络模型,得到的卷积特征输出表达能力更强。
相比于光流法、Kalman、Meanshift等传统算法,相关滤波类算法跟踪速度更快,深度学习类方法精度高.
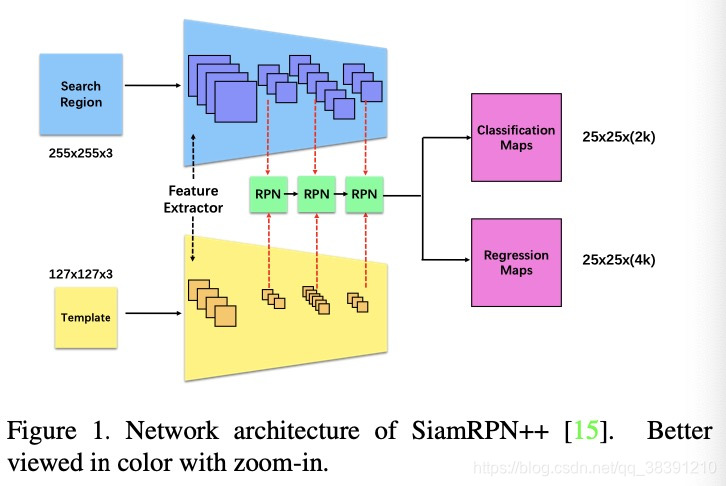
4.SiamRPN++网络
初始帧中的template是模板T,SiamRPN++可以检测到搜索区域SR中的目标。template指的是从初始帧中crop出来的图片patch,从而可以提供目标的外观信息。现在大部分的追踪器都只会对上一帧中目标物体所在位置的搜索区域内进行定位,而不会对整张图片进行定位,因为被追踪的物体在两帧之间不会有太大的移动。当前帧的搜索区域的size与当前帧的比例是跟初始帧中的比例相同(意思是只保持比例相同)。在每一帧中,模板T和搜索区域SR都会先通过一个共享的backbone网络,例如ResNet50,但是特征处理是会分别通过一个不共享的layer,并且后面通过DepthWise做互相关操作。基于这些提取出来的特征,RPN头部layer会预测出来分类图Mc和回归图MR。SiamRPN++存在的问题就是,如果Mc和MR被受到干扰,追踪器就会丧失定位目标的能力并且产生不准确的结果,从而导致追踪失败。
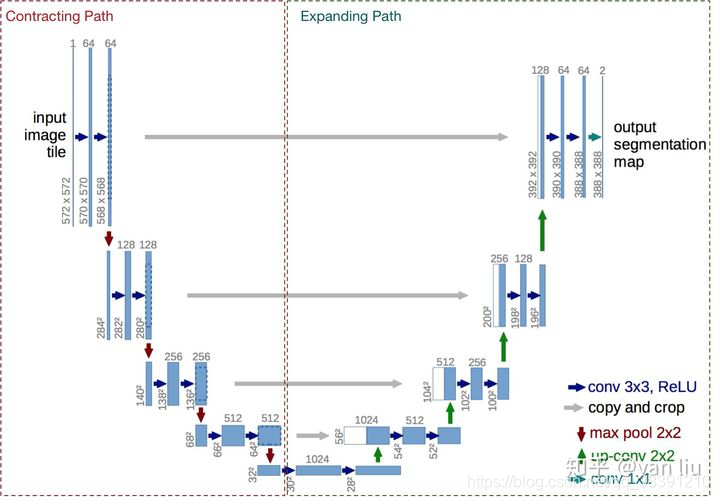
5.U-Net网络
U-Net是比较早的使用全卷积网络进行语义分割的算法之一。因为网络结构很像一个U,所以叫做U-Net网络。
左边的压缩路径由4个block组成,每个block使用了3个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2,因此有了图中所示的Feature Map尺寸变化。最终得到了尺寸为32*32的Feature Map。
网络的右侧部分(绿色虚线)在论文中叫做扩展路径(expansive path)。同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即图中左侧虚线部分)。
三 Contribution
(1)判别器是非必须的,因为L2 loss和fooling loss已经可以达到攻击的目标了。
(2)本文的方法有迁移性,可以迁移到DaSiamRPN等。
四 Introduction
基于SiamRPN的追踪器把追踪当作是one-hot检测问题,对于每一帧中的与初始帧中搜索区域的外观最相近的物体进行定位。因为权衡到了准确率和速度,所以SiamRPN系列的追踪算法比判别式的追踪器受到了更多关注。
现在的对抗攻击可以总结成两种:基于迭代优化攻击和基于深度学习攻击。基于迭代优化攻击的方法多次使用梯度下降算法来最大化欺骗深度网络的对抗攻击函数,但是这种方法是很耗费时间的。基于深度学习攻击需要使用很多数据来训练一个对抗扰动生成器。基于深度学习攻击是比基于迭代优化的方法更快,因为每次攻击只需要一次前向传播。
五 相关工作
(1)单目标追踪
单目标追踪主要是在每一帧中对目标物体进行定位。与目标检测需要识别的物体是已经确定好的一些类别中的一个不同,单目标追踪是one-shot learning,需要追踪任何可能的物体。随着深度学习的繁荣与大规模目标追踪数据集的引入,单目标追踪逐渐发展。现有的追踪器主要分为:Siam系列追踪器和基于判别器的模型如ATOM和DiMP。
SiamRPN网络将单目标追踪任务看作是one-shot的检测问题。通过RPN网络,SiamRPN移除了厚重的multi-scale相关性操作,可以取得更高的准确率和更快的速度。
但是使用图片填充(image padding)会存在问题,使得SiamRPN和DaSiamRPN只能使用不需要图片填充的AlexNet作为backbone网络,但是AlexNet没有完全的利用到当今深度神经网络的一些优势。SiamRPN++为了改进SiamRPN,提出了自裁的残差单元(cropping- inside residual unit),从而消除了图片填充带来的中心偏置问题(center bias)。
ATOM是由目标评估和分类组成的。
(2)对抗攻击
对抗攻击方法可以分成两种:基于迭代优化和基于深度网络。基于迭代优化的主要有FGSM,Deepfool以及DAG。基于深度网络的方法包括advGAN和UEA,可以使用大量数据去训练一个对抗样本生成器。AdvGAN是第一个使用GAN的对抗攻击方法,在inference推断阶段可以有效的运行。
真实世界的物理攻击比digital对抗攻击要更困难,因为已经有人证明,使用通用的方法产生的对抗样本是不能满足真实世界的情况的,因为真实世界中有相机噪声等诸多噪声。所以为了解决这个问题,EOT方法就不仅训练原始的图像,还会训练数据增强后的图像。
(3)Cooling-Shrinking攻击
这篇文章的攻击目标是使得目标消失,从而导致tracking drift。基于SiamRPN的追踪算法是基于初始帧中的搜索区域来对每一帧中的目标进行定位,本文设计了两种对抗扰动生成方式:攻击搜索区域和攻击模板template。
1)整体的pipeline
攻击搜索区域的整体pipeline如下图所示:
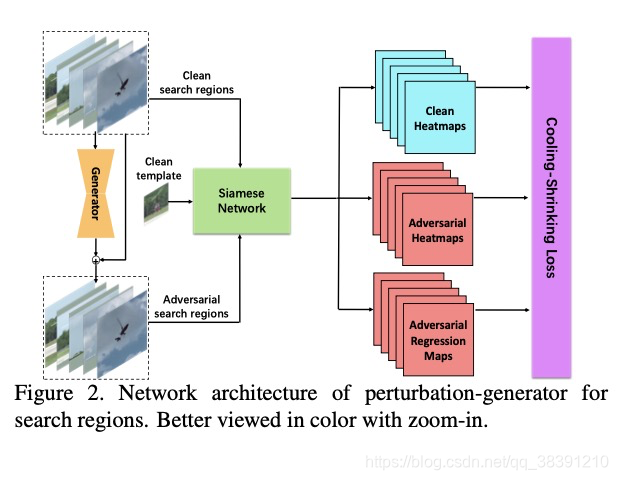
在训练阶段,首先会feed N个已经crop好的未加对抗扰动的搜索区域到对抗扰动生成器中,会添加不可感知的噪声在搜索区域中。并且将扰动后的搜索区域和模板一起输入到SiamRPN++追踪器中。所以本文的攻击思路是使得分类图中存在目标的那部分的对抗热力图获得较低的响应值。
整个的算法流程如下:

Lc和Ls是两部分损失值,cooling loss也即是Lc就是用来对热力图中可能存在目标的那部分区域进行降温,从而导致追踪器丢失目标物体。shrinking loss也就是Ls就是用来让预测的边界框收缩,从而导致错误积累,并且最终导致追踪失败。作者会设置一个margin mc把它放在损失函数中从而避免损失值的降低。同时,在shrinking loss中会添加Rw和Rh这两个缩放因子;而在cooling loss中会设置mw和mh这两个值。其中的P+和P-分别指的是目标物体的概率值和背景的概率值,以及一个预定义的阈值T。因此,首先就是计算一个二元的attention map图A,这样就可以得到我们感兴趣的位置。之后,会对正类别f+和负类别f-区域中A>0的部分定义一个cooling loss(cooling loss就是为了缩小正类别f+和负类别f-之间的距离,从而让目标不容易被识别出来)。同时会设定一个阈值mc,来避免loss的无限下降(意思应该是限制扰动的大小吧)。同时会设置两个缩放因子Rw和Rh来对宽度和长度进行缩放,mw和mh是两个阈值。

(4)实现细节
1)网络架构
扰动的生成器是使用的U-Net架构,可以在像素(pixel)级别上获得很好的表现。U-Net首先会对输入的特征图做很多次下采样,然后再做上采样从而使得输入图片的size被scale到2的幂次方。现在的很多基于SiamRPN的追踪器的template模板的size都是127127。但是在不同的场景中,搜索区域的size是不同的,可能是255255或者是831831。这个搜索区域的size如果太大就会带来很大的计算量,但是太小又会损失很多的具体信息。这篇论文中是把输入模板的size设置成128128,将搜索区域的size设置成512512.如果是127127的size的template,就会通过填充0将其变成128128的template,从而产生对抗的template。然后再将其crop成127127从而再输入到Siamese网络中。类似的,在攻击搜索区域的时候,首先将255255的图片插值到512512,然后再喂入到生成器中去得到对抗的搜索区域,最后也恢复到255*255的大小从而输入到Siamese网络中。
2)训练数据集
这篇论文采用的训练数据集是GOT-10K。GOT-10K数据集包括了超过10000个序列,以及超过500个目标类别,从而可以展现追踪的多样性。在每一个训练迭代过程中,同一个视频序列会产生一个template模板和N个搜索区域,其中N一般是不超过15的。
3)训练损失函数
损失函数是cooling loss,shrinking loss和L2 loss的简单的线性组合。这三个损失值的权重是可以被tune的。例如可以增大L2损失的权重或者降低对抗损失的权重,从而使得这个攻击不容易被察觉。这篇论文中的cooling loss,shrinking loss和L2 loss的权重值分别设定成0.1,1和500.mc,mw和mh三个阈值设定成-5.
(5)实验
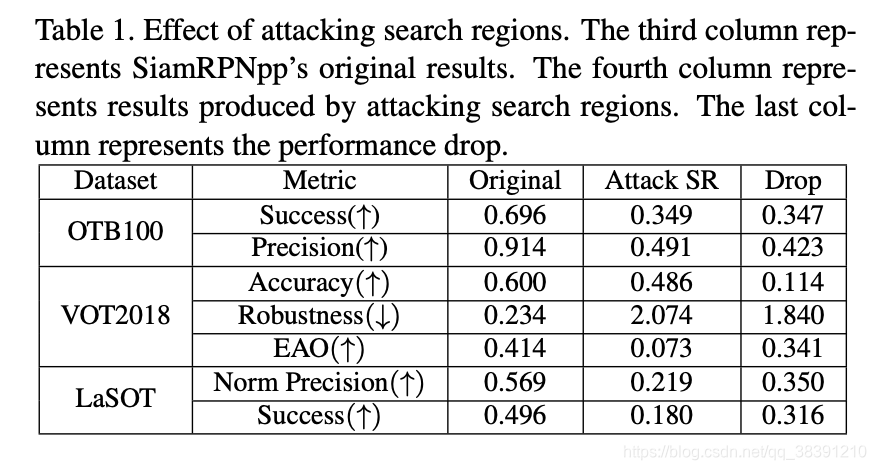
1)对于SiamRPNpp的对抗攻击
只攻击搜索区域的结果如下:
只攻击模板的结果如下:
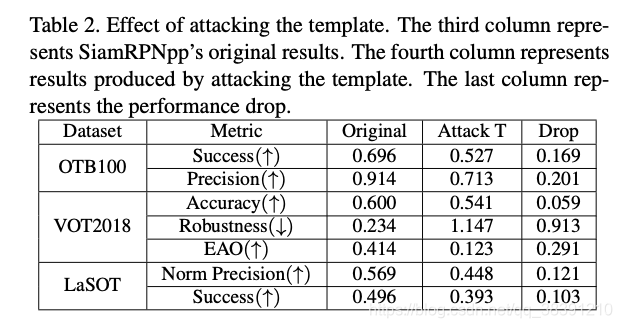
同时攻击搜索区域和模板的结果如下:

从实验结果来看,貌似攻击搜索区域的攻击成功率要更高一些。
(6)消融实验
1)shrinking loss的影响
shrinking loss的作用是攻击分类的分支,从而让目标物体不可见invisible,还可以影响追踪器的scale estimation的功能,从而使得追踪器产生不准确的bounding box框的预测。但是在攻击template模板的时候,shrinking loss会产生负面的影响,会使得misclassification这个过程变得比较局部。通俗一点讲就是,就是攻击模板的时候,就很难在所有帧都欺骗到追踪器(相当于是只能欺骗一部分的视频帧,而不是所有的视频帧,但是这里是为什么呢??后面或许可以找找原因)。在只攻击template模板的时候,生成器很难均衡cooling loss和L2 loss。在这个时候,添加shrinking loss反而会降低攻击的性能。总的来说,就是shrinking loss在攻击搜索区域的时候是有用的,但是攻击template模板的时候就会有一点危害。
2)Discriminator的影响
之前大部分的基于神经网络的对抗攻击都是会使用GAN这个网络结构,会使用一个判别器discriminator来对于生成器generator的输出结果进行评估和判别,从而使得生成器的输出结果可以接近于原始的输入(目的应该是为了让对抗样本图片可以尽可能接近原始图片吧)。但是,这篇论文的作者认为判别器discriminator其实是没有必要的。因为L2 loss和discriminator的使用就是为了使得加了对抗扰动的图片可以尽可能的接近于原始的图片。但是在GAN的结构中,生成器generator和判别器discriminator是必须要被同步的,但是在有很多任务的过程中,这种同步性是很难保证的。所以,因为GAN的架构的不稳定性,作者抛弃了判别器,而是直接采用cooling loss和L2 loss。
(7)Discussion
1)speed速度
本文的方法有很高的准确性。在攻击搜索区域的时候,只需要9ms以下就可以产生一个对抗的视频帧,有接近100fps的帧率。在攻击template模板的时候,作者的方法只需要3ms以下的时间就可以攻击到整个的视频序列。从时间损耗上来看,这篇论文的方法的对抗样本生成速度是比一般的实时追踪器更快的(这样是不是就可以实现对实时的追踪器的攻击,因为每次追踪器在进行追踪的时候就可以实时的生成对抗样本,不会影响到追踪的速度。)
2)Noise Pattern

从上面这张图可以看到对抗扰动在图片上的具体呈现。放大原始图片和对抗图片,就可以看到二者的区别,对抗图片上添加了一些蜂巢一样的东西,就可以实现隐藏攻击。
3)可迁移性Transferability
作者将基于SiamRPNpp的对抗扰动迁移到其他的追踪器DaSiamRPN,DaSiamRPN-UpdateNet和DiMP中,也可以取得好的效果。所以这里迁移过去的三个追踪器的结构应该都和SiamRPNpp比较类似,都有template和搜索区域。
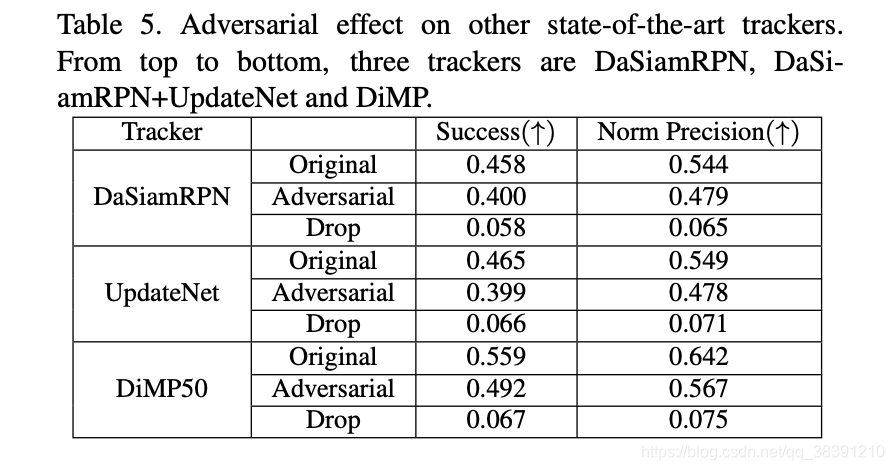
不过,可以发现,从基于SiamRPNpp的对抗样本迁移到另外三个追踪器,其实并不能产生十分好的攻击效果,基本没有效果,只是降低了一点点。
(8)Conclusion
这篇文章对SiamRPN++网络的攻击可以达到很高的攻击成功率,并且添加的噪声还是不可感知的,也就是比较小的。并且作者发现discriminator在对抗攻击中并不是必须的,因为L2 loss和对抗损失已经可以实现discriminator的功能(让对抗扰动尽可能不可见)。并且还有迁移性。
(9)存在的问题
1)为什么对于template模板的攻击的效果没有搜索区域的攻击效果好。
2)为什么cooling loss 的添加反而会对template模板的攻击产生负面的影响。
3)怎么解决迁移性的问题。
4)是否可以通过调整三个损失的权重来提高对于template模板的攻击效果。














 918
918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









