






🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【数据可视化-30】Netflix电影和电视节目数据集可视化分析
一、引言
1. 简述数据可视化的重要性
数据可视化是将数据以图形或图像的形式表示出来,使得复杂的数据更容易被人类理解和分析。在数据分析、商业智能、科学研究等领域,数据可视化都扮演着至关重要的角色。它不仅能够直观展示数据的分布、趋势和关联,还能帮助我们发现隐藏在数据中的模式和洞见,从而做出更明智的决策。
Netflix电影和电视节目数据集可视化分析
一、引言
数据可视化是探索和理解复杂数据集的强大工具。通过可视化分析,我们可以揭示Netflix平台上电影和电视节目的分布特征、内容趋势以及用户可能的观看偏好。本文将基于包含丰富信息的Netflix数据集,从多个维度进行可视化探索,帮助大家更直观地了解Netflix内容生态。
二、数据探索
2.1 数据集介绍
本数据集包含以下变量:
- show_id:每部电影或电视节目的唯一标识符
- type:内容类型(电影或电视节目)
- title:电影或电视节目的标题
- director:电影导演
- cast:参与的演员
- country:内容制作国家
- date_added:在Netflix上的上架日期
- release_year:内容的实际发布年份
- rating:内容的电视分级
- duration:时长(分钟)或季数
2.2 数据清洗与探索
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
df = pd.read_csv('netflix_titles.csv') # 请替换为实际文件路径
# 查看数据基本信息
print(df.info())
# 查看各列唯一值数量
print(df.nunique())
# 缺失值情况
df.isnull().sum()
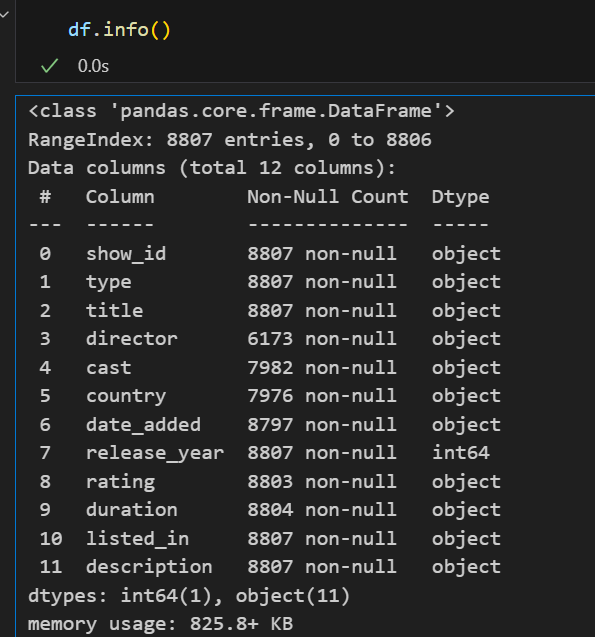
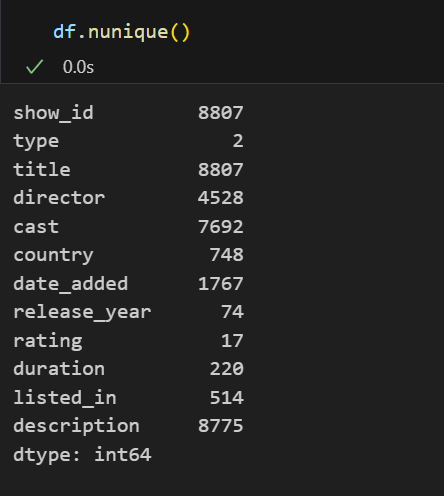
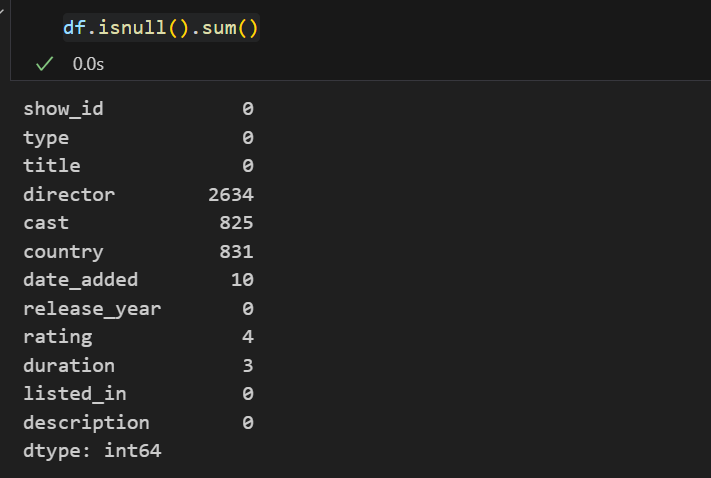
从数据的基本信息中,我们可以发现:
- 数据集包含多种类型变量,包括类别型(如type、rating)和一个数值型(release_year)
- 一共有8807行数据,数据中存在缺失值,director导演列的缺失值最多,达到2634个,近缺失30%
三、单维度特征可视化
3.1 内容类型分布
plt.figure(figsize=(10, 6))
sns.countplot(x='type', data=df)
plt.title('Content Type Distribution')
plt.xlabel('Content Type')
plt.ylabel('Count')
plt.tight_layout()
plt.show()
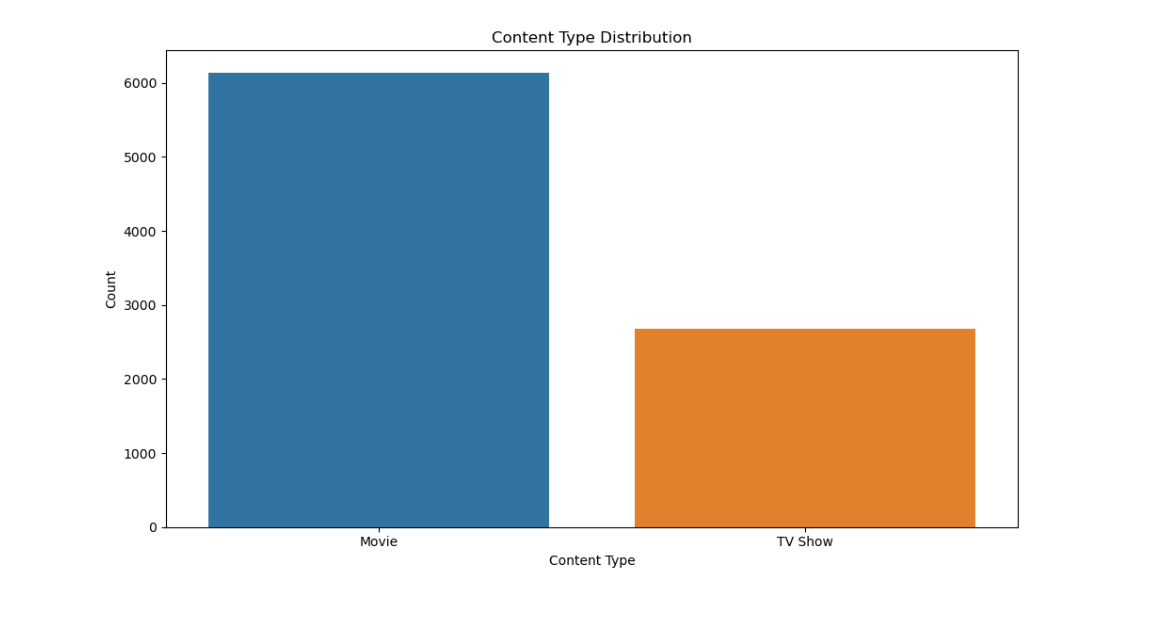
观察结果:电视节目和电影的数量差异显著,电视节目占比较高。
3.2 上映年份分布
plt.figure(figsize=(15, 6))
sns.countplot(x='release_year', data=df, palette='viridis')
plt.title('Content Release Year Distribution')
plt.xlabel('Release Year')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
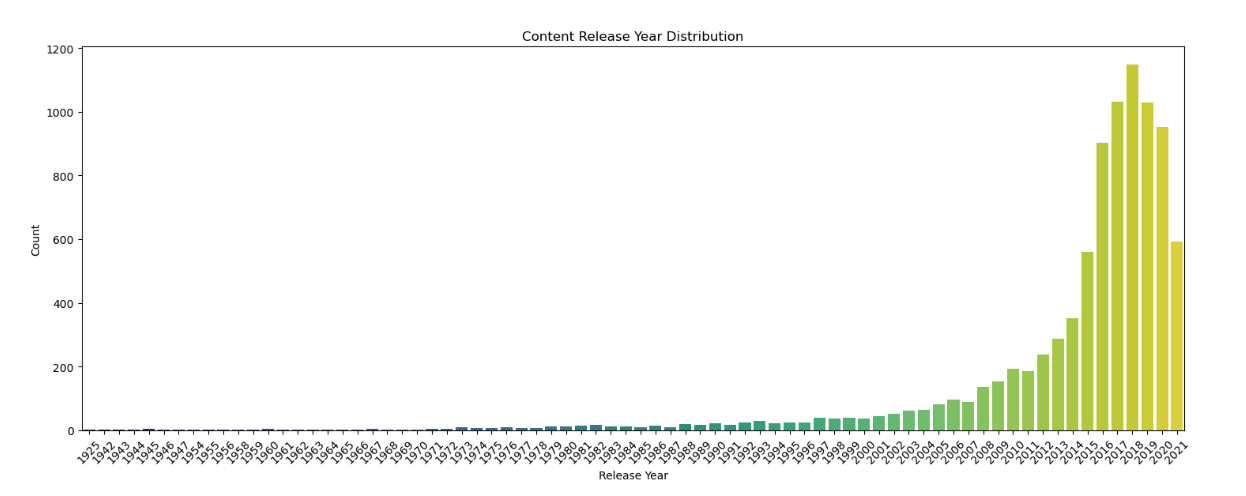
观察结果:内容发布年份集中在近几年,反映出Netflix内容产量的增长趋势。
3.3 电视节目季数分布
# 提取电视节目的季数信息
tv_shows = df[df['type'] == 'TV Show']
tv_shows['duration'] = tv_shows['duration'].apply(lambda x: int(x.split(' ')[0]) if pd.notnull(x) else 0)
plt.figure(figsize=(12, 6))
sns.histplot(tv_shows['duration'], bins=30, kde=True, color='teal')
plt.title('TV Show Seasons Distribution')
plt.xlabel('Number of Seasons')
plt.tight_layout()
plt.show()
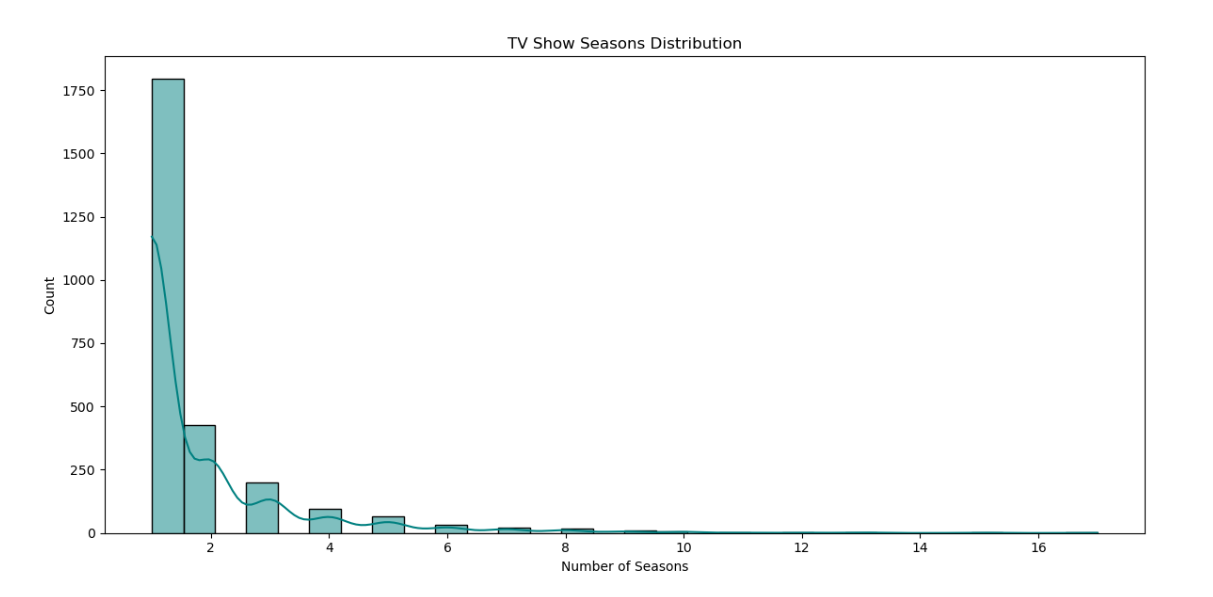
观察结果:大部分电视节目季数集中在1到5季,少数节目拥有较长的系列。
3.4 电影时长分布
# 提取电影的时长信息
movies = df[df['type'] == 'Movie']
movies['duration'] = movies['duration'].apply(lambda x: int(x.split(' ')[0]) if pd.notnull(x) else 0)
plt.figure(figsize=(12, 6))
sns.histplot(movies['duration'], bins=50, kde=True, color='coral')
plt.title('Movie Duration Distribution')
plt.xlabel('Duration (minutes)')
plt.tight_layout()
plt.show()
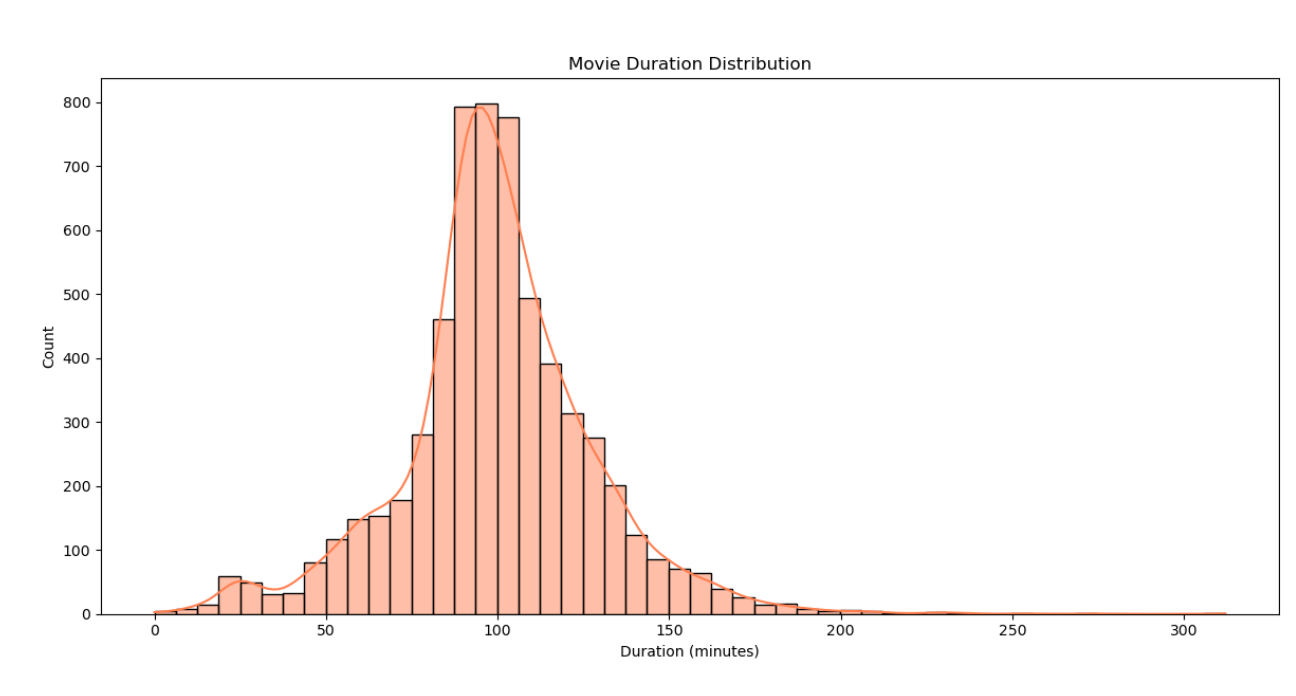
观察结果:电影时长主要集中在90到120分钟之间,符合典型电影的时长范围。
四、多维度关系可视化
4.1 top15国家与内容类型的关系
country = df['country'].value_counts()[:15].index.tolist()
df1 = df[df['country'].isin(country)]
plt.figure(figsize=(15, 8))
sns.countplot(x='country', hue='type', data=df1, palette='Set2')
plt.title('Content Type Distribution by Country')
plt.xlabel('Country')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.legend(title='Content Type')
plt.tight_layout()
plt.show()
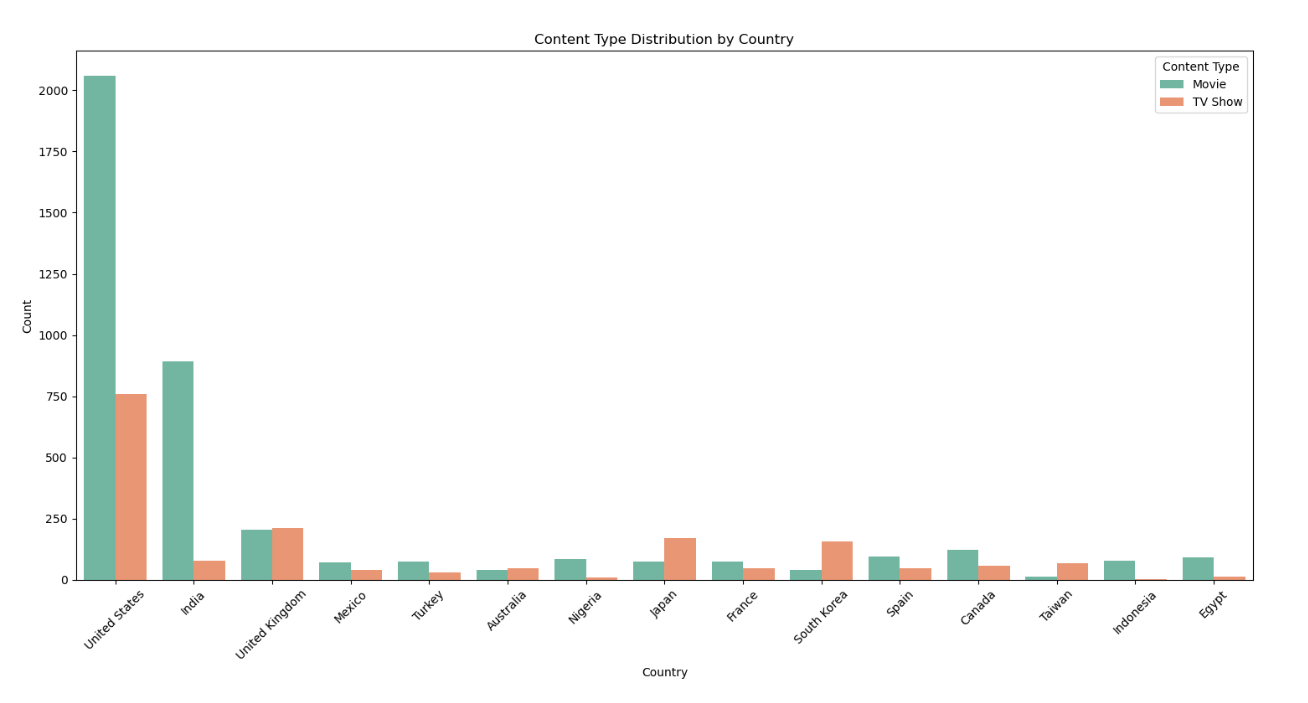
观察结果:美国制作的内容最多,且电影和电视节目分布较为均衡,其他国家则各有侧重。
4.2 年份与内容类型的关系
plt.figure(figsize=(15, 8))
sns.countplot(x='release_year', hue='type', data=df, palette='husl')
plt.title('Content Type Distribution Over Years')
plt.xlabel('Release Year')
plt.ylabel('Count')
plt.legend(title='Content Type', bbox_to_anchor=(1, 1), loc='upper left')
plt.tight_layout()
plt.show()
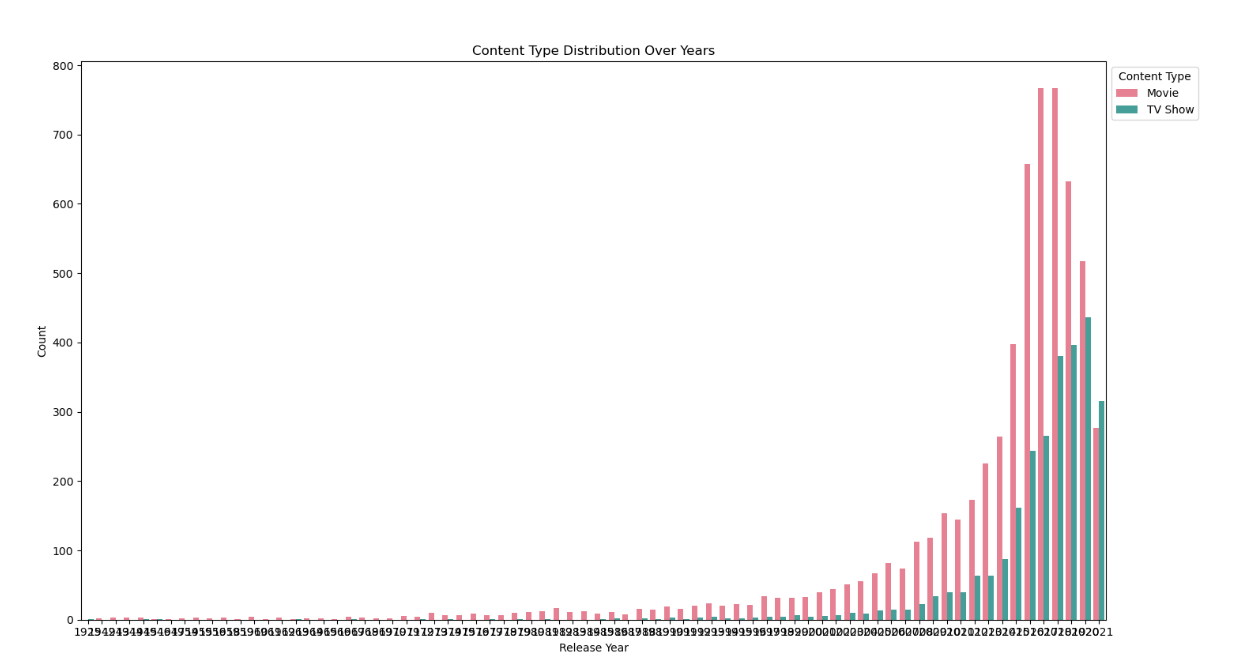
观察结果:近几年电影和电视节目数量均呈现增长趋势,但电视节目增长更为显著。
4.3 评级与内容类型的关系
plt.figure(figsize=(15, 8))
sns.countplot(x='rating', hue='type', data=df, palette='muted')
plt.title('Content Distribution by Rating and Type')
plt.xlabel('Rating')
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.legend(title='Content Type', bbox_to_anchor=(1, 1), loc='upper left')
plt.tight_layout()
plt.show()
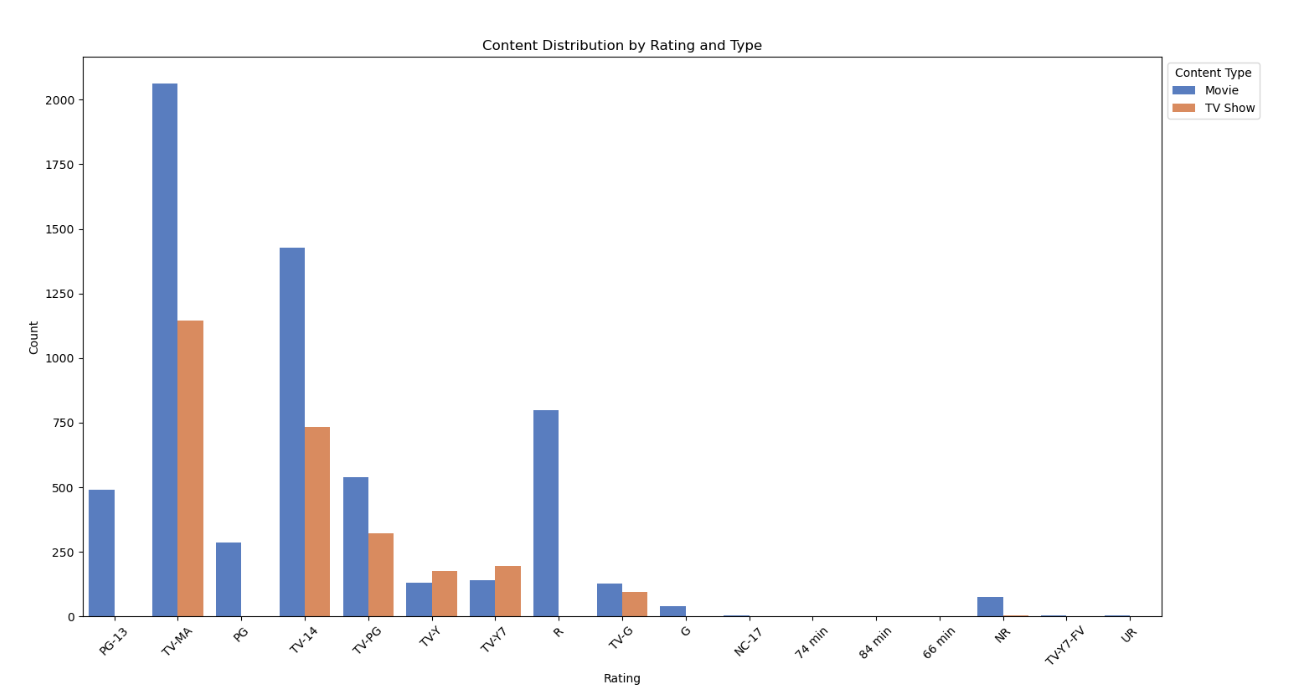
观察结果:不同评级的内容类型分布差异明显,TV-MA(成人级)和TV-14(青春期少年级)分级的内容较多,涵盖电影和电视节目。
4.4 内容时长与上映年份的关系(以电影为例)
plt.figure(figsize=(15, 8))
sns.scatterplot(x='release_year', y='duration', data=movies, alpha=0.6, color='purple')
plt.title('Movie Duration vs Release Year')
plt.xlabel('Release Year')
plt.ylabel('Duration (minutes)')
plt.tight_layout()
plt.show()
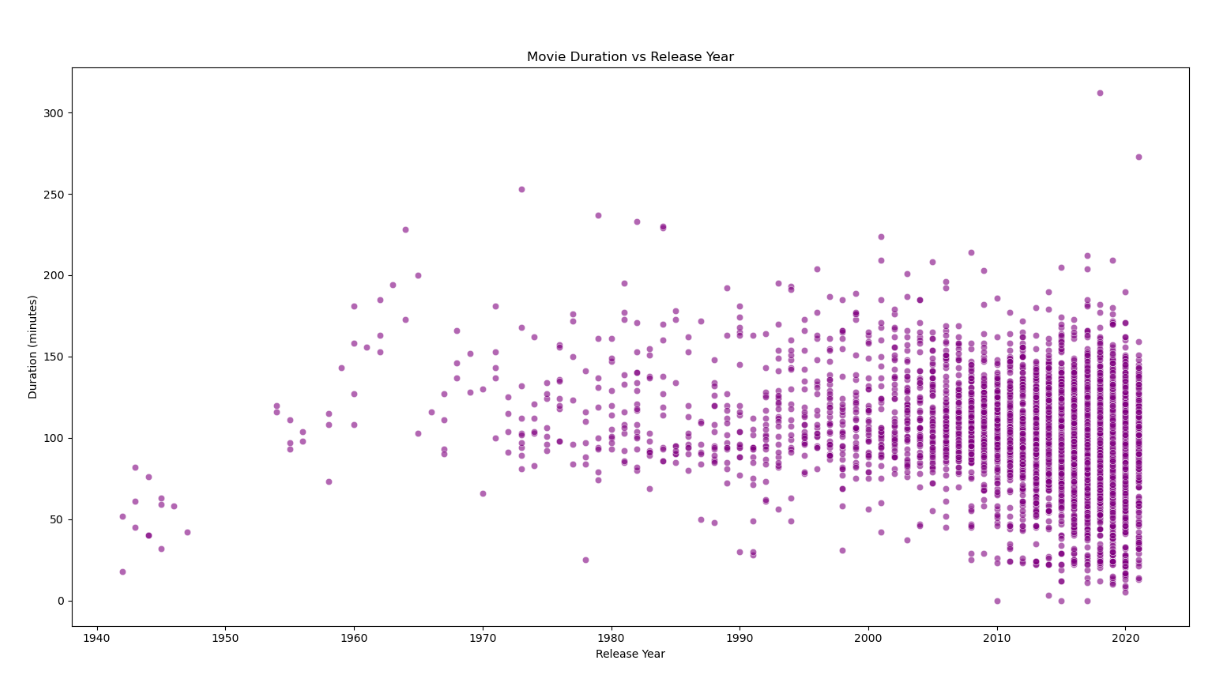
观察结果:电影时长与上映年份无明显线性关系,但可见不同时期电影时长的分布特征。
五、总结与洞察
通过以上多维度的可视化分析,我们得出以下关键洞察:
-
内容类型分布不均:电视节目数量多于电影,且增长趋势更为明显。
-
国家制作差异显著:美国是内容制作的主力军,其他国家制作内容较少,但各有特色。
-
分级与内容类型关联紧密:成人级和青春期少年级内容占比较大,涵盖电影和电视节目。
-
电影时长稳定:电影时长多集中在90到120分钟,符合观众常规观影习惯。
以上分析为理解Netflix平台内容生态提供了多维度视角,揭示了各变量之间的潜在关系,为进一步的内容策略制定和用户研究提供了数据支持。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











