







本系列博客包括6个专栏,分别为:《自动驾驶技术概览》、《自动驾驶汽车平台技术基础》、《自动驾驶汽车定位技术》、《自动驾驶汽车环境感知》、《自动驾驶汽车决策与控制》、《自动驾驶系统设计及应用》,笔者不是自动驾驶领域的专家,只是一个在探索自动驾驶路上的小白,此系列丛书尚未阅读完,也是边阅读边总结边思考,欢迎各位小伙伴,各位大牛们在评论区给出建议,帮笔者这个小白挑出错误,谢谢!
此专栏是关于《自动驾驶汽车环境感知》书籍的笔记
1.障碍物检测
1.1 基于激光雷达的障碍物检测
1.1.1 基于几何特征和网格
- 几何特征包括:直线、圆和矩形等;基于几何特征的方法首先对激光雷达的数据进行处理,采用聚类算法将数据聚类并与障碍物的几何特征进行对比,对障碍物进行检测和分类;
- 为了提高对不同点云数据检测的可靠性,基于几何特征的方法与光谱特征结合,将几何和影像特征综合考虑,从多个维度对障碍物进行识别,同时引入权重系数来反映不同的特征对识别的影响;
- 对于非结构化的道路,需要用基于网格的方法进行识别此类障碍物,基于网格方法将基于激光雷达的数据投影到网格地图中,利用无向图相关方法对点云数据进行处理;网格大小和结构可自定义,用网格分布图像来表示障碍物,分辨率越高的网格,表示的障碍物越复杂,同时需要较高的计算复杂度和内存;
1.1.2 VoxelNet障碍物检测
为了减少人力去处理激光雷达扫描到较远物体的数据,在VoxelNet的研究中,消除了对点云进行手动提取特征的过程,提出了统一的端到端的三维检测网络;
VoxelNet将原始点云作为输入,由于现有激光雷达返回的点云数据包含的坐标点数量较大,多为数万到数十万,对计算量和内存的需求过大,VoxelNet除了减少人力标注外,同时着重解决了如何让网络高效处理更多的激光点云数据;
VoxelNet主要由三个模块组成:特征学习网络、中间卷积层和区域建议网络;
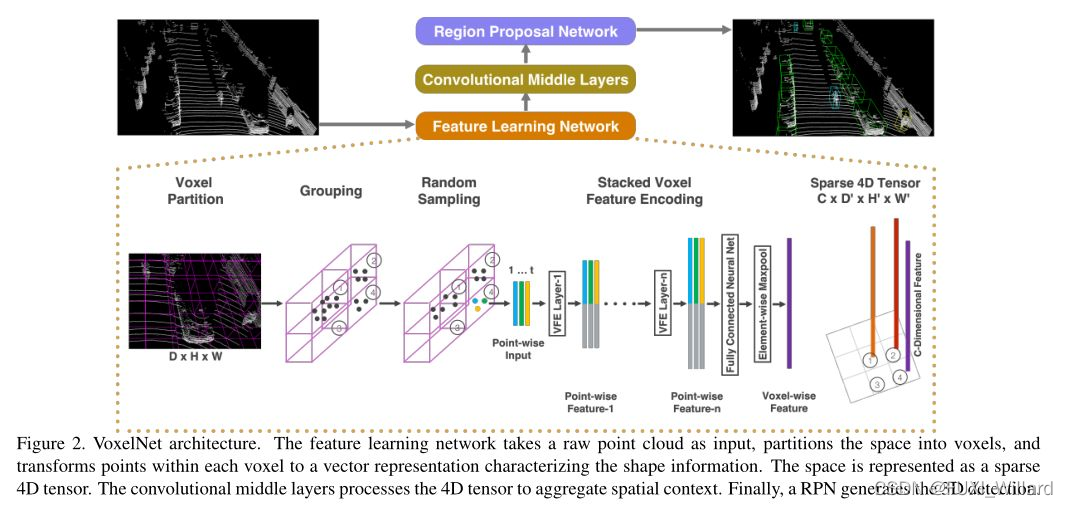
特征学习网络将点云划分为体素Voxel形式,通过VFE层提取特征,得到体素级的特征向量,包括:
- 体素划分:给定输入点云,将空间划分成均匀的体素Voxel,假设点云对应的 x 、 y 、 z x、y、z x、y、z坐标信息分别代表 W 、 H 、 D W、H、D W、H、D的三维空间, V w 、 V h 、 V d V_w、V_h、V_d Vw、Vh、Vd分别为每个体素的大小,可以得到 D ′ × H ′ × W ′ D'\times{H'}\times{W'} D′×H′×W′个体素网格,其中 D ′ = D / V d , H ′ = H / V h , W ′ = W / V w D'=D/V_d,H'=H/V_h,W'=W/V_w D′=D/Vd,H′=H/Vh,W′=W/Vw;
- 分组:将点云根据空间位置划分到相对应的体素中,由于距离、遮挡、物体相对姿态和采样不均匀等原因,激光雷达获取的点云在空间中的分布不均匀,所以分组时会造成不同的体素中包含的点云数量不同;
- 随机抽样:VoxelNet采用随机抽样的策略,具体方法:随机从拥有多于T个点的体素中随机采样T个点云,随机抽样策略从一定程度上减少了体素之间点云分布不平衡,减少了采样的偏移,更有利于训练,节省计算量;
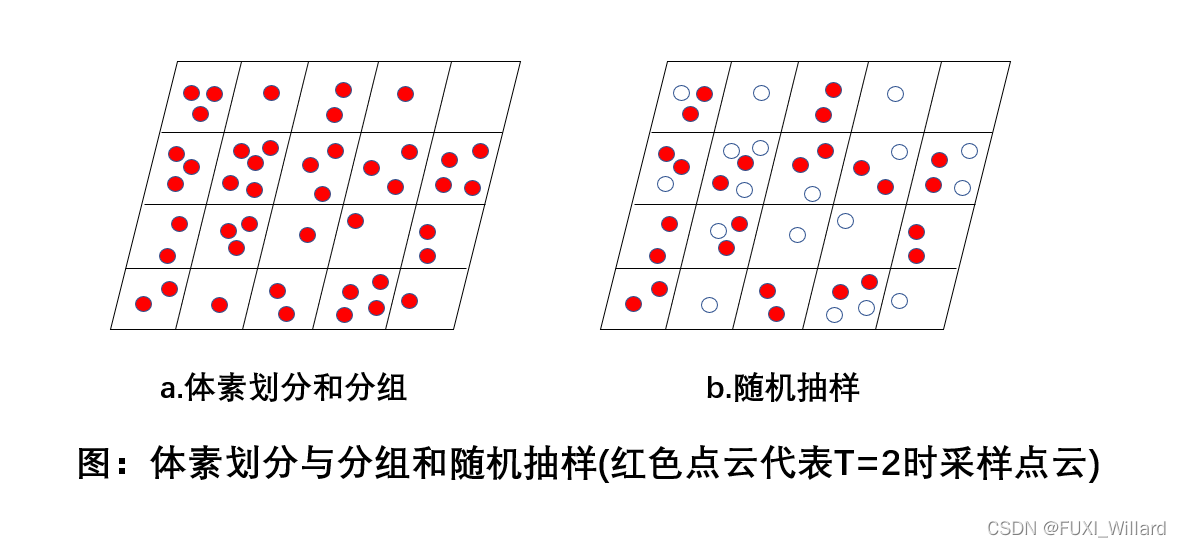
- 堆叠体素特征编码:通过级联VFE层实现基于点的点特征和局部特征的融合,以第一层VFE层为例,流程如下:
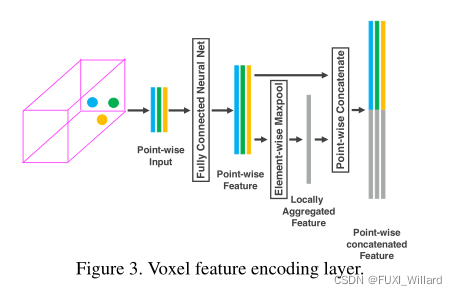
- 首先对每个网格的点云进行去中心化,得到每个点的VFE层的输入;
- 每个点经过包含ReLU函数和BN(Batch Normal)运算的全连接网络,得到点特征;
- 对每个点特征进行最大池化运算,得到局部聚合特征;
- 最后,将点特征和局部聚合特征进行结合运算,得到最后的特征向量;
- 对每个体素进行处理,得到特征提取层的输出;
- 稀疏张量表示:在体素划分时,许多体素是空的,只需要对非空体素进行VFE处理,将其表示为稀疏张量,可以有效节省资源;
中间卷积层负责将特征向量进行三维卷积,提取特征,获取全局特征;
区域建议网络(RPN)将特征进行整合,输出预测概率,给出预测结果等;
1.2 基于视觉和激光雷达融合的障碍物检测
几种方案的特点:
- 摄像头方案:成本低,可以识别不同的物体,在物体高度与宽度测量、车道线检测、行人识别准确度等方面有优势,是实现车道偏离预警、交通标志识别等功能不可缺少的传感器,但作用距离和测距精度不如毫米波雷达,且容易受光照、天气等因素的影响;
- 毫米波雷达:受光照和天气因素影响较小,测距精度高,但难以识别车道线,交通标志等元素;毫米波雷达通过多普勒偏移原理能够实现更高精度的目标速度探测,同时通过视觉可以获得充分的语义信息;
- 激光雷达:可以获得准确的位置信息;
1.2.1 空间融合
- 实现多传感器数据空间融合的关键:建立精确的雷达坐标系、三维世界坐标系、摄像机坐标系、图像坐标系、像素坐标系之间的坐标转换关系;
- 雷达和视觉传感器空间融合:将不同传感器坐标系的测量值转换到同一个坐标系中;
- 将雷达坐标系下的测量点通过坐标转换到摄像机对应的像素坐标系下实现多传感器的空间同步;
- 得到雷达坐标系和摄像机像素坐标系间的转换关系,即可完成空间上雷达检测目标匹配到视觉图像,在此基础上,将雷达检测对应目标的运动状态信息输出;
1.2.2 时间融合
- 雷达和视觉信息在空间上进行融合时,需要传感器在时间上同步采集数据,实现时间融合;
- 毫米波雷达采样周期为50ms,即采样帧速率为20帧/秒,摄像机采样帧速率为25帧/秒;以摄像机采样速率为基准,摄像机每采样一帧图像,选取毫米波雷达上一帧缓存的数据,即完成共同采样一帧雷达与视觉融合的数据,保证毫米波雷达数据和摄像机数据时间上的同步;


















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











