






目录
5、数据预处理:构造关于X的高次项特征 + 特征归一化 + 调整维度
一、理论知识
假如我们需要拟合的数据如下图所示,该数据显然不服从Y关于X的一次函数。此时,一元线性回归模型不再适用,我们可以考虑多元线性回归模型,建立Y关于X的高次函数。

具体地,我们首先构造关于X的高次项特征:
然后,我们建立多元线性回归模型:
其中,表示输入,
表示输出,
和
表示可学习的权重参数。
最后,多元线性回归模型下的损失函数、梯度计算、梯度下降的矩阵表达式与一元线性回归模型一致:机器学习:一元线性回归(梯度下降法)
二、代码实现
1、导入Python包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
plt.rcParams['font.sans-serif'] = ['Times New Roman']2、训练数据可视化
train_data = pd.read_csv('./data/sinc_train.txt',names=['Y','X'])
plt.figure(dpi=100)
plt.scatter(train_data['X'], train_data['Y'])
plt.xlabel('X')
plt.ylabel('Y')
plt.show()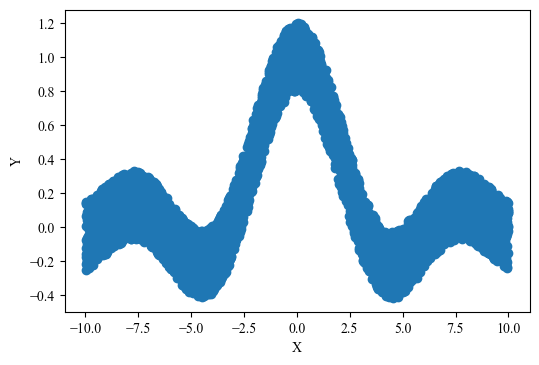
3、测试数据可视化
test_data = pd.read_csv('./data/sinc_test.txt',names=['Y','X'])
plt.figure(dpi=100)
plt.scatter(test_data['X'], test_data['Y'])
plt.xlabel('X')
plt.ylabel('Y')
plt.show()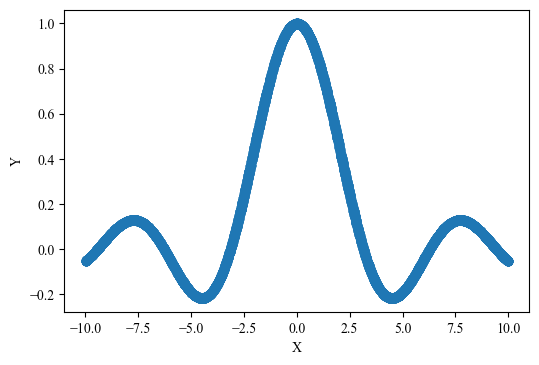
4、定义前向传播函数、损失函数、反向传播函数
def forward(X, weights, bias):
Y_hat = np.dot(X, weights) + bias
return Y_hat
def Loss_fuction(Y, Y_hat):
N = Y.shape[0]
cost = 1 / (2 * N) * np.sum((Y_hat - Y) ** 2)
return cost
def backward(X, Y, Y_hat, weights, bias, lr):
# 梯度计算
N = Y.shape[0]
dw = 1 / N * np.dot(X.T, (Y_hat - Y))
db = 1 / N * np.sum(Y_hat - Y)
# 权重更新
weights -= lr * dw
bias -= lr * db
return weights, bias5、数据预处理:构造关于X的高次项特征 + 特征归一化 + 调整维度
M = 10 # 多次项最高项系数
X = np.concatenate([train_data['X'].to_numpy(),test_data['X'].to_numpy()])[:,None]
Y = np.concatenate([train_data['Y'].to_numpy(),test_data['Y'].to_numpy()])[:,None]
X_bar = []
for i in range(M):
X_bar.append(X ** (i+1))
X_bar = np.concatenate(X_bar, axis=-1)
X_bar = (X_bar - np.mean(X_bar, axis=0, keepdims=True)) / (np.std(X_bar, axis=0, keepdims=True) + 1e-8)
X_train, X_test, Y_train, Y_test = X_bar[:5000], X_bar[5000:], Y[:5000], Y[5000:]
print(X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)6、定义并初始化权重参数 W 和 b
weights = np.zeros((M, 1))
bias = 07、模型训练
lr = 0.3 # 学习率
epochs = 6*10**4 # 迭代次数
train_loss = []
for _ in range(epochs):
# 前向传播
Y_hat = forward(X_train, weights, bias)
# 损失计算
loss = Loss_fuction(Y_train, Y_hat)
train_loss.append(loss)
# 反向传播
weights, bias = backward(X_train, Y_train, Y_hat, weights, bias, lr)
plt.figure(dpi=100)
plt.plot(train_loss)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss")
plt.show()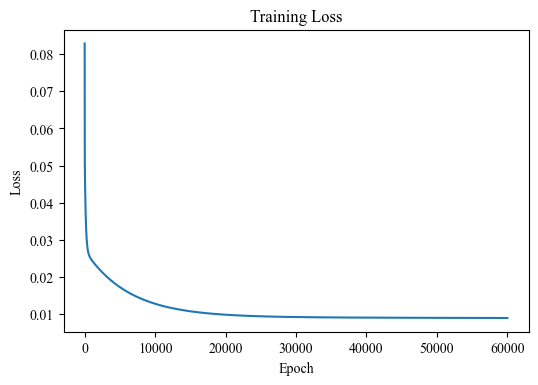
8、模型测试
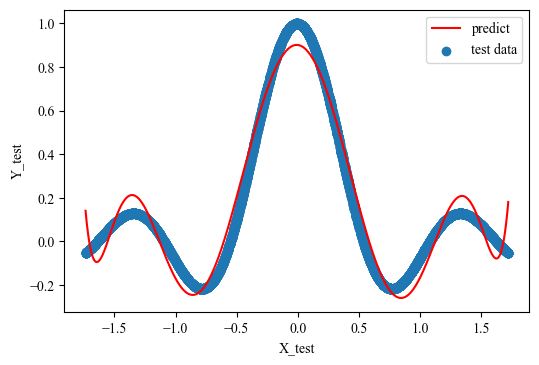
y_predict = forward(X_test, weights, bias)
plt.figure(dpi=100)
plt.scatter(X_test[:,0], Y_test[:,0], label='test data')
plt.plot(X_test[:,0], y_predict, 'r', label='predict')
plt.legend()
plt.xlabel('X_test')
plt.ylabel('Y_test')
plt.show()
# y_predict = forward(X_test, weights, bias)
print(f"Test MSE: {mean_squared_error(y_predict, Y_test)}")
Test MSE: 0.00451366589809465
(数据集请自行构造,不方便提供)















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









