






科研记录——keras
Pytorch是可以实现正则化的,其中
optimizer = torch.optim.SGD(model.parameters(), lr=lr, weight_decay=1e-4)
其中,权重衰减系数weight_decay就是一种正则方法。
具体而言:权重衰减等价于 L2 范数正则化(regularization)。
但Pytorch无法实现嵌套的正则化,只能单纯重写写
# 定义L1正则化函数
def l1_regularizer(weight, lambda_l1):
return lambda_l1 * torch.norm(weight, 1)
# 定义L2正则化函数
def l2_regularizer(weight, lambda_l2):
return lambda_l2 * torch.norm(weight, 2)
Pytorch正则化
import torch
import torch.nn as nn
#定义网络结构
class CNN(nn.Module):
pass
# 实例化网络模型
model = CNN()
# 定义损失函数
criterion = nn.MSELoss()
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 迭代训练
for epoch in range(1000):
#训练模型
model.train()
for i, data in enumerate(train_loader, 0):
#1 解析数据并加载到GPU
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
#2 梯度清0
optimizer.zero_grad()
#3 前向传播
outputs = model(inputs)
#4 计算损失
#4.1 定义L1和L2正则化参数
lambda_l1 = 0.01
lambda_l2 = 0.01
#4.2 计算L1和L2正则化
l1_regularization = l1_regularizer(model.weight, lambda_l1)
l2_regularization = l2_regularizer(model.weight, lambda_l2)
#4.3 向loss中加入L1和L2
loss = criterion(outputs, labels)
loss += l1_regularization + l2_regularization
#5 反向传播和优化
loss.backward()
optimizer.step()
在keras框架实现正则化
kernel_regularizer:施加在神经元权重w上的正则项,为keras.regularizer.Regularizer对象。
bias_regularizer:施加在神经元偏置向量b上的正则项,为keras.regularizer.Regularizer对象。
activity_regularizer:施加在输出(激活函数)上的正则项,为keras.regularizer.Regularizer对象。
#其中0.01为上面2.1小节提到的常数系数C,自己设置
keras.regularizers.l1(0.01)#L1正则项
keras.regularizers.l2(0.01)#L2正则项
keras.regularizers.l1_l2(0.01)#结合了L1和L2的正则项
from keras import regularizers
model.add(Dense(2, input_dim=10,#输入数据唯独10,输出唯独为2
kernel_regularizer=regularizers.l1(0.01),#在权重参数w添加L1正则化
bias_regularizer=regularizers.l2(0.01),#在偏置向量b添加L2正则化
activity_regularizer=regularizers.l1_l2(0.01),#在输出部分添加L1和L2结合的正则化
activation='relu'#激活函数采用ReLU
))
输出层添加L1 L2正则化?
keras可以在隐藏层和偏置上分开调价正则化项
正则项在优化过程中层的参数或层的激活值添加惩罚项,这些惩罚项将与损失函数一起作为网络的最终优化;
这个网络层的作用是对输入的损失函数更新正则化。
神经网络的激活值添加惩罚项
python函数修饰符@ 修饰符 ‘@’符号用作函数修饰符是python2.4新增加的功能,修饰符必须出现在函数定义前一行,不允许和函数定义在同一行。也就是说@A def f(): 是非法的。 只可以在模块或类定义层内对函数进行修饰,不允许修修饰一个类。一个修饰符就是一个函数,它将被修饰的函数做为参数,并返回修饰后的同名函数或其它可调用的东西。本质上讲,装饰符@类似于回调函数,把其它的函数(暂且称为目的参数,后面紧接着的函数)作为自己的入参,在目的函数执行前,执行一些自己的操作,比如:计数、打印一些提示信息等,然后返回目的函数。下面列举一个简单的例子。
参考链接:
https://zhuanlan.zhihu.com/p/470782515
回调函数 callbacks
存储模型,实时监控数据集的变化,
ModelCheckpoint,中途训练效果提升,训练每一轮结束的模型,保存下来;
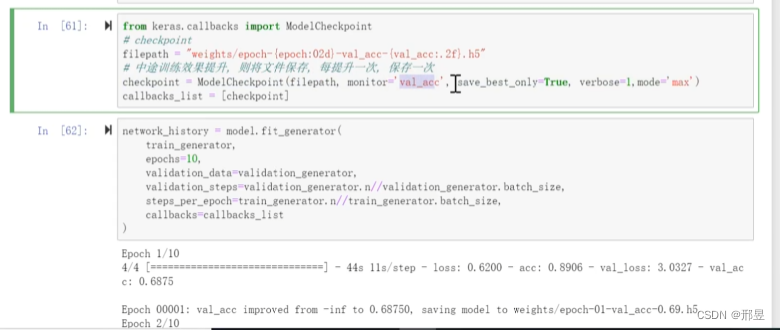
checkpoint模型集成;
投票后进行决定;
EarlyStopping:模型早停止;
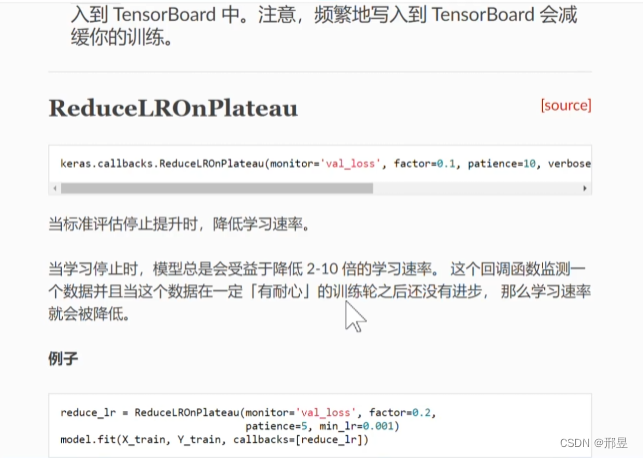
ReduceLROnPlateau:精调数据















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









