







论文介绍
题目:Learning Temporal Consistency for Low Light Video Enhancement From Single Images
DOI:10.1109/CVPR46437.2021.00493
会议:2021-CVPR
机构:北京工业大学
论文链接:https://ieeexplore.ieee.org/document/9578889/
代码链接:https://github.com/zkawfanx/StableLLVE
参考笔记:https://blog.csdn.net/tj21z/article/details/120997098提出问题
1、没有时间信息的单幅图像的微光增强方法在处理微光视频时,会遭受严重的时间不一致性(帧间闪烁)。
2、暗光视频增强任务最难的地方在于质量较好的训练视频对(暗光视频和对应的亮光视频)难以获取。
解决方案
提出利用自一致性的单图像方法来增强微光视频,并通过在网络上施加一致性来解决时间不一致性问题。首先从单个图像中学习和推断运动场(光流),然后将光流图像扭曲为相邻帧,并对深层模型施加一致性。
创新点
1、不需要视频作为训练数据,仅使用单帧图像数据。
2、在显示单个图像的潜在运动之前使用光流,从而使建模时间一致性。
网络模型
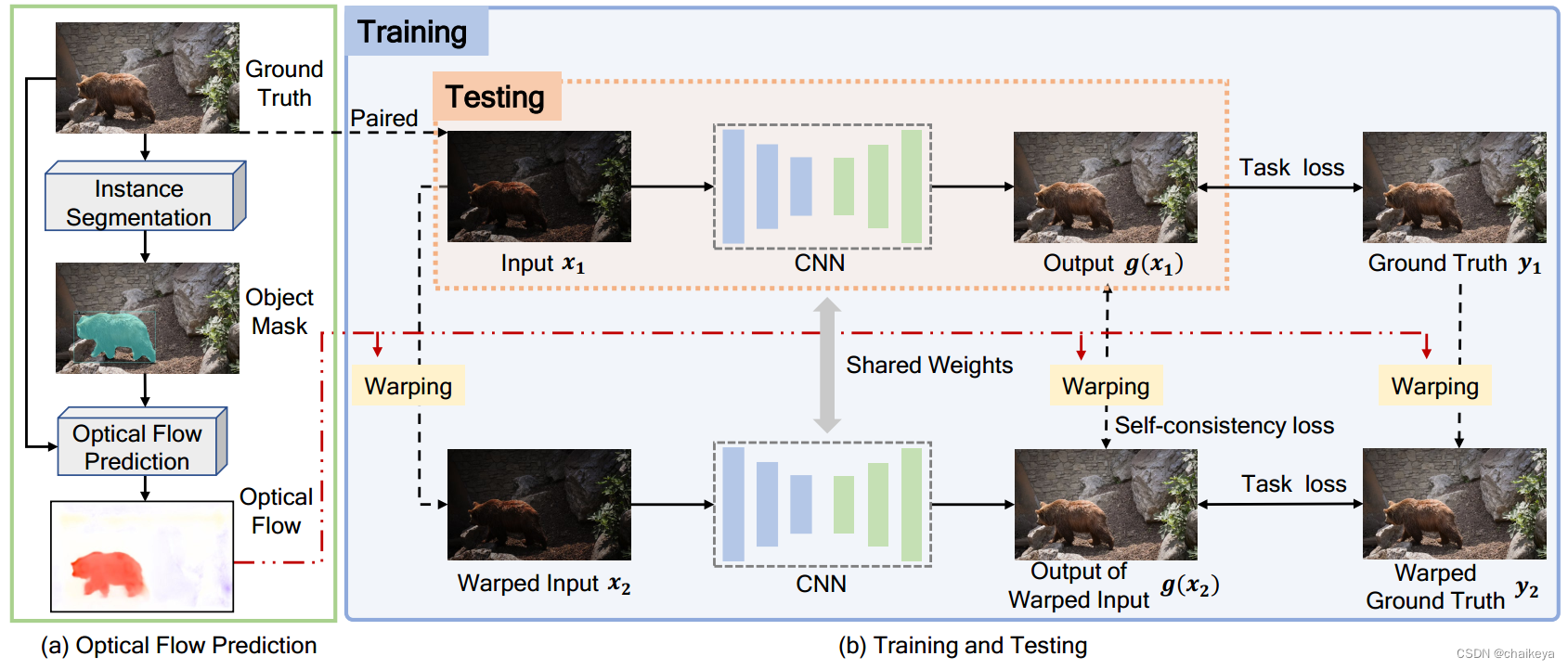
(a)光流预测。首先利用实例分割[31]将对象从通常发生局部运动的背景中分离出来,并在每个对象区域上随机采样10个引导运动向量。通过将明亮的图像和矢量输入光流预测网络[32],改变方向和大小以获得不同的光流。
(b)训练和测试。由两个分支组成,其中上面一个分支在训练和测试阶段都起作用,而另一个分支仅在训练期间起作用,作为辅助分支对网络施加时间一致性。第二分支中的图像与具有相同光流的主分支中的图像进行扭曲。
原始数据x1,y1根据光流信息进行Warp得到第二遍输入和真值x2,y2。
总的来说:利用光流来表示动态场景的视频帧之间发生的运动。通过用相应的光流扭曲图像来模拟相邻帧。给定原始图像和扭曲图像的图像对,以Siamese的方式训练网络(为了搭配consistency-loss),将它们一个接一个地输入网络。通过在输出对之间施加一致性,帮助网络在时间上保持稳定。
训练和测试模型:上部是网络的第一个通道,与常规培训程序相同。将来自训练数据集的微光图像x1输入网络g(·),并预测增强结果g(x1)。该网络在相应照明良好的地面真值y1的监督下学习恢复正常光照图像。为了提供更多的时间信息,我们将输入图像x1与基于地面真值预测的随机光流f进行扭曲。扭曲图像x2用作第二遍的输入。还将输出g(x2)与相应的扭曲地面真值y2进行比较,以进行监控。最后,输出g(x1)以相同的光流f扭曲,并与输出g(x2)进行比较。
通俗说法:输入输出只有一张图像,作者使用语意分割的mask当作引导,产生光流,从而生成各种对齐后的输入图像,再将这张对齐后的输入通过同一个网络,计算输出与原始输出对齐后的loss。
用途:可以考虑用在单帧降噪的时序一致性上。
1、单帧图像对中没有动态场景,那么缺失的运动信息该怎么弥补回来?
利用光流来模拟运动信息,使得单帧图像”动“起来。不过值得注意的是,这里提到的光流模型不能计算多帧之间的差异,只能依赖单帧图像来进行预测。2、单帧模型在处理视频时,往往出现十分严重的闪烁问题,该如何避免?
使用了consistency-loss来约束网络的训练过程,缓解帧间闪烁问题。不过在光流的帮助下,作者能用更加”科学“地使用consistency-loss。
1、光流预测
光流能够同时表示全局运动和局部运动。本文尝试从单个图像预测随机光流。
首先使用一个在COCO上预训练好的FPN网络对图像进行分割,得到代表对象区域的粗糙对象遮罩,保留所有置信度高于85%的物体区域。然后,我们在每个区域上采样多个运动矢量,并基于它们预测光流:
![]()
其中,CMP表示光流预测模型,y和V分别表示地面真实图像和制导运动矢量。
为图像中的每个对象随机抽取10个向量,以获得最终预测。直接调用CMP,生成光流信息,然后再将原图根据光流进行Warp,得到临近帧,完成数据的增广。(预测的光流作为初始起点,通过增强生成各种光流情况。)
![]()
其中f表示预测光流,x1和x2分别为原始图像和扭曲图像。
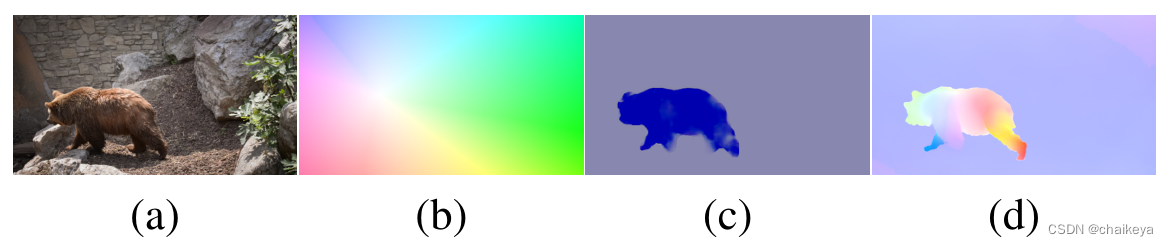
图2:光流结果示例。(a)普通光视频帧。(b)来自全局仿射变换的光流。(c)本文的实例感知光流模拟进行光流预测。(d)从相邻的正常光视频帧估计光流。
与全局变换(b)相比本文(c)预测的光流是实例感知的,更接近相邻视频帧之间的真实光流(d)。
2、consistency-loss
L = Le(增强损耗)+ Lc(一致性损耗)
![]()
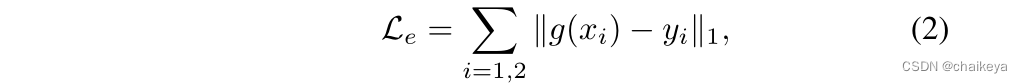
![]()
式中的x2就是x1根据某些"变换"得到的,g(x)代表将x送入CNN得到的输出,f是光流信息,W代表Warp变换。
而之前的文献的做法,没有使用f,而W也往往是简单的翻转、平移等操作。作者认为本文这样的使用方法更加多样化,也更加合理。
3、低光照图像合成
使用伽马校正和线性缩放将DA-VIS视频数据集上对应的明亮图像变暗:
![]()
其中γ是均匀分布U(2, 3.5)中采样的γ校正。α和β表示线性比例因子,分别从U(0.9, 1)和U(0.5, 1)中采样。
4、噪声数据
从高斯分布和泊松分布中采样噪声,然后将其添加到弱光图像中,然后再将其送入网络。
![]()
其中σp,σg分别表示泊松噪声和高斯噪声的参数。它们都是从U(0.01, 0.04)中取样的。
评价指标
1、评价单帧图像质量的指标:PSNR和SSIM
PSNR峰值信噪比:值越大,就代表失真越少。
SSIM结构相似性:范围为0到1。当两张图像一模一样时,SSIM的值等于1。
SSIM基于样本x和y之间的三个比较衡量:亮度 (luminance)、对比度 (contrast) 和结构 (structure)。用均值作为亮度的估计,标准差作为对比度的估计,协方差作为结构相似程度的度量。
2、评价视频Temporal-Consistency的指标:AB、MABD、WE
三个指标中的值越低,表示时间稳定性越好。
AB(var)(Average Brightness(Variance),出自BMVC2018的MBLLEN)
AB(var)的计算方式应该就是先计算增强后的视频与原始视频每帧图像的AB值差异,然后所有帧的AB值差异在求取一个方差,方差越小,则可以侧面说明算法生成的结果帧间一致性越好。
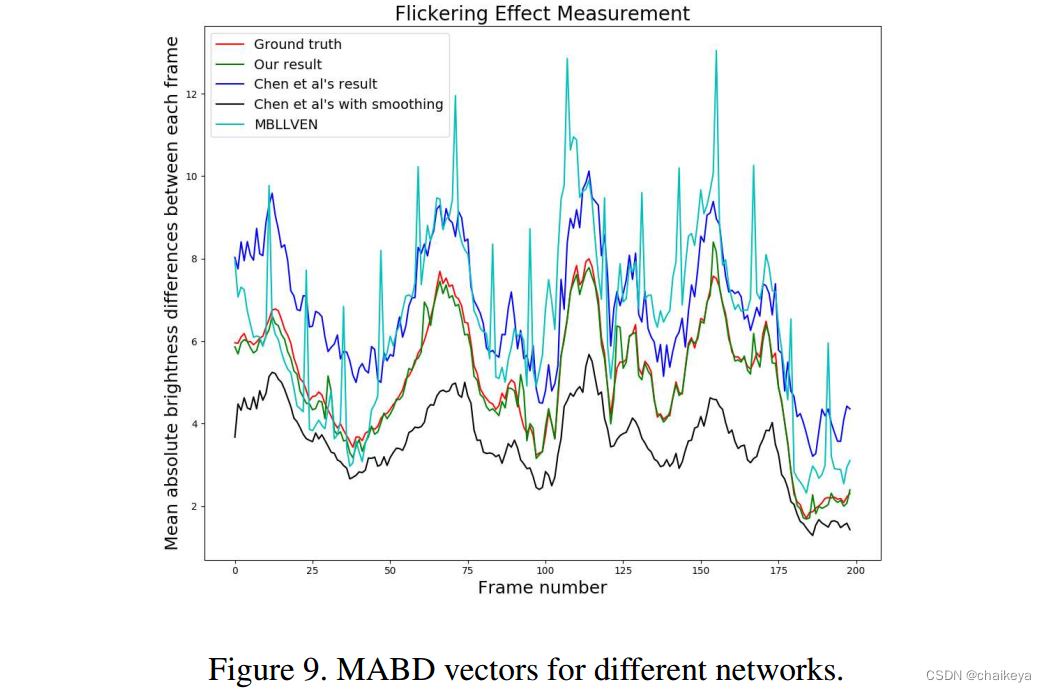
MABD(Mean Absolute Brightness Difference,出自ICCV2019的Learning to See Moving Objects in the Dark)
在《Learning to See Moving Objects in the Dark》这篇文章中,作者将MABD定义如下:
对于一个视频来说,MABD可以近似地堪称对时间(帧)的导数,其计算结果应该是一条如下图所示的曲线:
但是MABD的提出者觉得曲线并不好进行量化的比较,于是直接对增强后视频和原始视频的MABD"向量"计算了MSE,将曲线之间的比较转化为了标量之间的比较(越小越好),方便进行量化比较。
WE(Warping Error,出自ECCV2018的Learning Blind Video Temporal Consistency)
在《Learning Blind Video Temporal Consistency》这篇文章中,作者将Warping Error定义如下:
这里面有两个点需要说明一下:
1、上标(i)代表像素点的位置,相当于遍历一张图的所有像素;
2、为什么要有代表非遮挡位置的掩码的M MM呢?是因为在文章中,光流信息使用FlowNetv2生成的,而遮挡会严重影响生成光流的质量,因此需要有这个掩码。但是对于本文来说,笔者觉得应该不需要这个掩码。

实验结果
合成数据集上结果对比:
表1-无噪声情况下的单帧图像定量结果:
自上而下的三组是基于图像的方法、基于视频的方法和利用自一致性的单图像方法
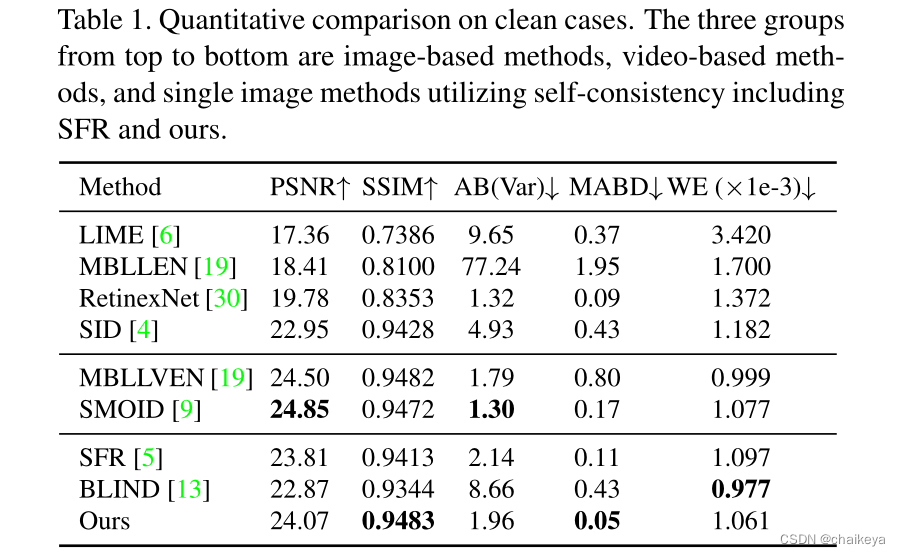
表2-有噪声情况下的单帧图像定量结果:
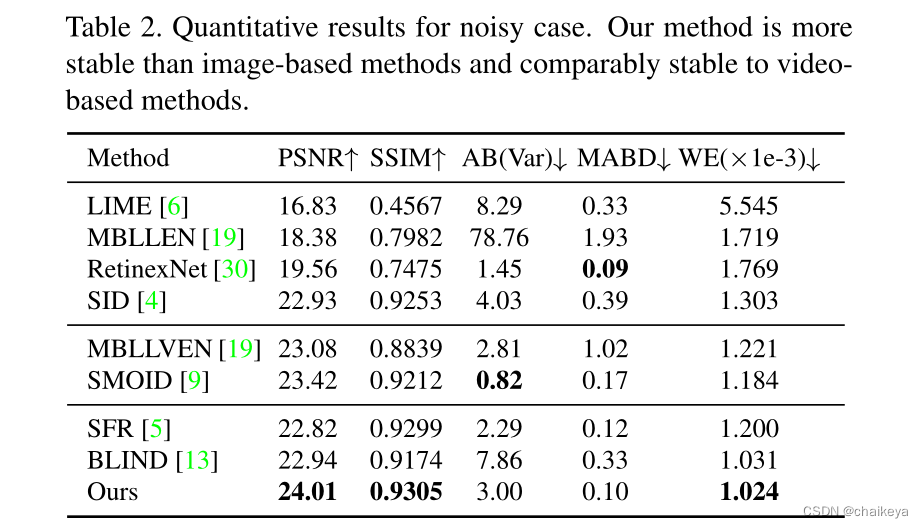
图3-单帧图像增强视觉质量对比。
LIME遭受过饱和,而RetinexNet得到了不真实的结果。MBLLEN在恢复亮度方面表现不佳。SID[4]由于反褶积而遭受棋盘伪影。SFR[5]和本文方法在时间上更稳定。

图4-微光视频增强视觉质量对比。
LIME、MBLLEN和RetinexNet都无法恢复正确的微光视频。MBLLEN的亮度远低于地面真值,导致AB值较大。RetinexNet增强了具有不真实颜色和太多平滑度的图像,从而提高了时间稳定性。由于噪声的存在,SID实际上得到了更重的伪影。SFR和我们的表现更好,而我们的仍然比另一个更好。与上述方法相比,基于视频的方法都能获得令人愉悦的视觉质量。

结论:定量度量结果和视觉质量都表明,该方法可以在不需要视频训练数据的情况下提高深层模型的时间稳定性,缓解闪烁问题。
真实数据集上结果对比:
图7-多帧视频用于实际数据测试。

消融实验
表3-图5-探索重建loss和一致性loss之间的权重λ值的变化的影响;
随着分支权重的增加,网络的时间稳定性比权重较小的网络更高,PSNR和SSIM也有所提高。当权重到达某一点时,改善增强质量的好处消失了,网络的峰值信噪比和SSIM开始下降,以进一步改善时间稳定性。我们可以发现最佳参数设置在λ=20左右。
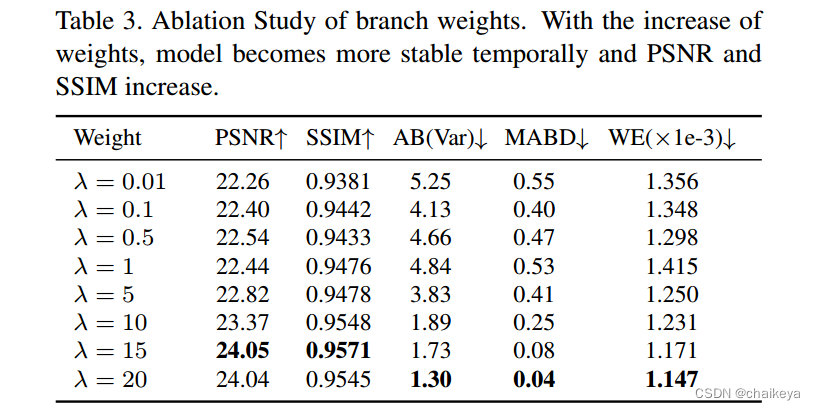

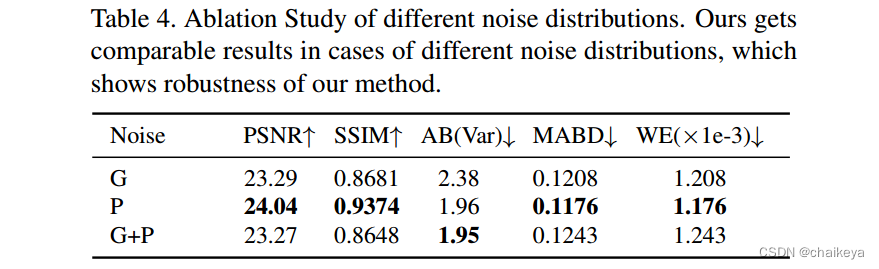
表4-合成的不同噪声种类对于最终结果的影响;
包括仅高斯噪声、仅泊松噪声和混合噪声。对于各种噪声成分,我们的模型都工作正常。
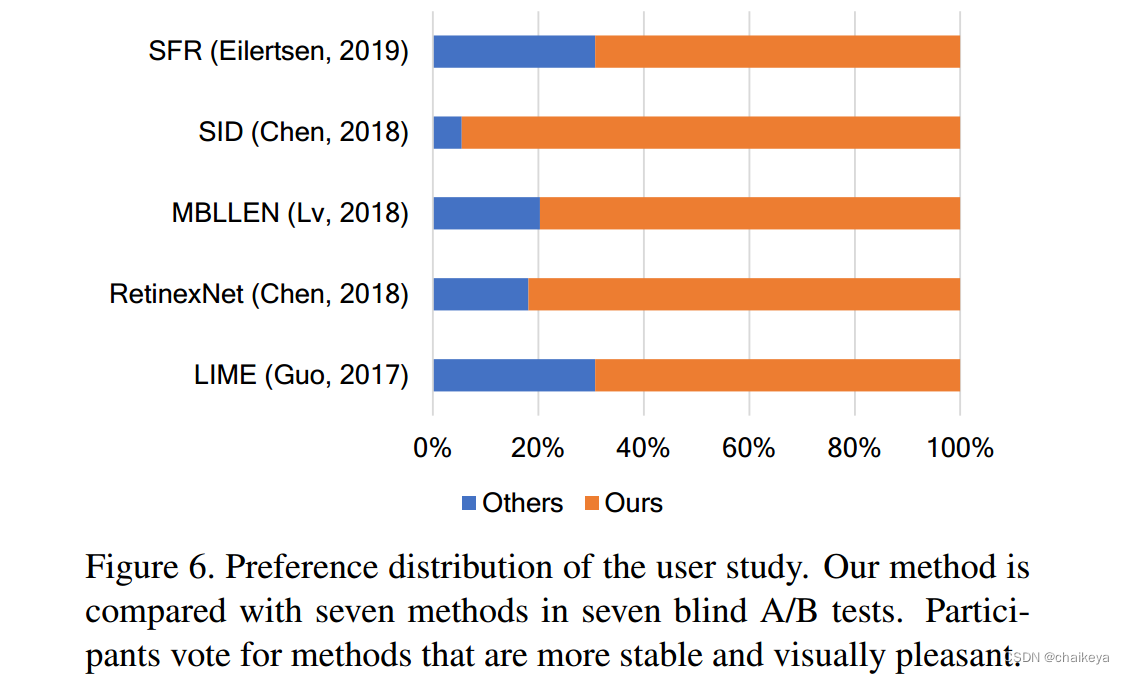
用户的偏好分布研究
在七个盲A/B测试中,我们的方法与七种方法进行了比较。参与者投票选择更加稳定和视觉愉悦的方法。
代码复现
input(左图)—result(右图)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









