







 本文介绍了如何使用R语言进行随机森林分类分析,展示变量重要性,并结合物种丰度差异检验进行绘图。内容涵盖随机森林模型构建、参数调整、变量重要性评估以及通过kruskal-Wallis检验分析显著性差异,最后利用patchwork包整合图形。
本文介绍了如何使用R语言进行随机森林分类分析,展示变量重要性,并结合物种丰度差异检验进行绘图。内容涵盖随机森林模型构建、参数调整、变量重要性评估以及通过kruskal-Wallis检验分析显著性差异,最后利用patchwork包整合图形。
此文主要涉及随机森林组间变量重要性和物种丰度差异检验绘图,包含以下几部分内容:
1)随机森林分类;
2)随机森林分类变量重要性绘图;
3)物种丰度差异检验绘图
4)随机森林分类变量重要性及物种丰度差异组合图
1. 数据准备
此处使用包含分类信息的虚构微生物otu数据,用于构建随机森林分类模型。
# 1.1 导入数据
setwd("D:\\EnvStat\\公众号文件\\随机森林分析") # 设置工作路径
##后续合并数据表时,物种名必须一样,
##所以导入的数据表尽量不要有特殊符号。
#dir()
#file.show("otu.csv")
otu = read.csv("otu.csv",row.names = 1,header = TRUE,check.names = FALSE,stringsAsFactors = FALSE) # 微生物组数据
dim(otu)
head(otu)
图1|原始otu表,otu.csv。前两列为分类信息,后面分析只使用depth分类信息。
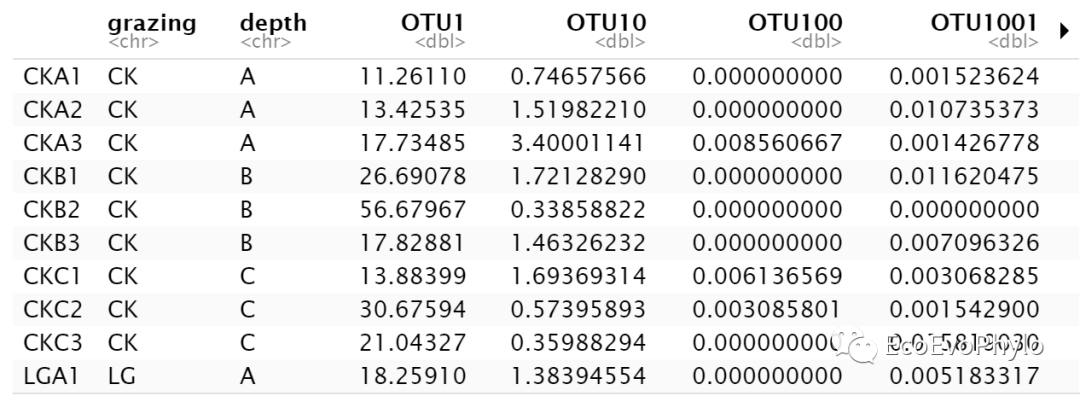
图2|相对丰度otu表,spe。
2. random forest随机森林分类分析
ntree(构建决策树数量),mtry(用于构建决策树的变量数)和maxnodes(最大终端节点数)是随机森林分析中影响分析结果的重要参数。这些参数的值都不是越大越好,都需要找到一个合适的值,调参的最终目的就是要降低分类或回归错误率。调整过程在机器学习-分类随机森林分析(randomForest模型构建、参数调优、特征变量筛选、模型评估和基础理论等)中写了。这篇推文主要讲绘图过程。
# 随机森林分类模型
library(randomForest)
set.seed(12345) #保证结果可重复
RF.best = randomForest(x = spe[-c(1:2)], # 此处需要替换为自己的数据
y= factor(spe[,2]),# 此处需要替换为自己的数据
importance=TRUE,# 输出变量重要性排序时必须设置
maxnodes = 5,# 此处设置数值是之前调参的结果。
mtry = 80,# 此处设置数值是之前调参的结果
ntree = 3,# 此处设置数值是之前调参的结果
Perm = 999)
#RF.best
rfPermute::confusionMatrix(RF.best)
summary(RF.best) # 会同时绘制分类准确率折线图。3. 随机森林变量重要性图
# 3.1 提取每个变量对样本分类的重要性
##RF1$importance #包含分类数+2列数据,
##每个自变量对每个分类的平均正确性降低值(mean descrease in accuracy),
##后两列分别为变量对所有分类的MeanDecreaseAccuracy和MeanDecreaseGini(节点不纯度减少值)。
##两个值越大,变量的重要性越大。
#RF.best$importanceSD # 变量重要值的置换检验的标准误,最后一列为MeanDecreaseAccuracy置换检验的p值。
imp = data.frame(importance(RF.best),MDA.p = RF.best$importanceSD[4])
head(imp) # 提取变量重要性值及置换检验p值.
# 3.2 将变量按MeanDecreaseGini重要性降序排列
library(dplyr)
imp = arrange(imp,desc(MeanDecreaseGini))
head(imp)
## 输出重要性排序结果到本地
write.csv(imp,"importance.csv",quote = FALSE)
# 3.3 提取重要性top10变量绘制条形图
## top10
imp = imp[1:10,]
imp
## 随机森林变量重要性条形图
##变量按MeanDecreaseGini降序排列:reorder(rownames(imp),MeanDecreaseGini)
library(ggplot2)
p1= ggplot(imp,aes(x=MeanDecreaseGini,y=reorder(rownames(imp),MeanDecreaseGini)))+
geom_bar(position = position_dodge(),
width = 0.5,
stat = "identity",
fill="steelblue")+ # 柱子的宽度与位置要保持一致,拼图时左/右才能时柱子对齐。
theme_minimal() +
xlab("Mean Decrease in Gini Index")+
scale_y_discrete(expand=c(0,0))+
scale_x_continuous(expand=c(0,0))+
theme(axis.text.y = element_text(size = 16,colour = "black"),
axis.text.x = element_text(size=14,color="black"),
axis.title.x.bottom = element_text(size=16,color="black"),
axis.ticks.y = element_blank(),
axis.title.y = element_blank(),
#panel.grid = element_blank() # 去除网格线
)
p1
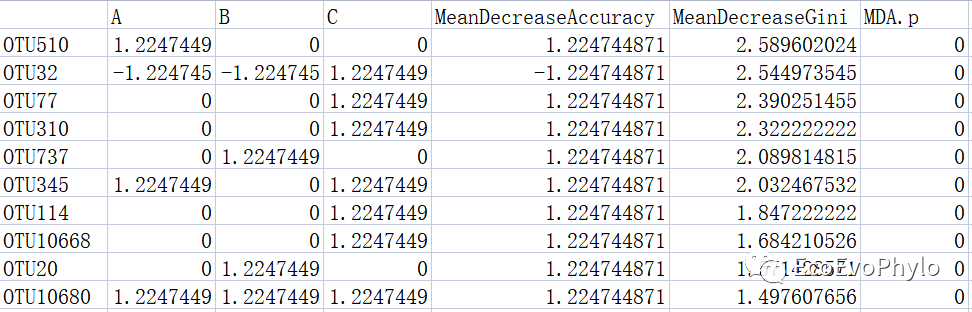
图3|MeanDecreaseGini降序排列的特征变量重要性top10。
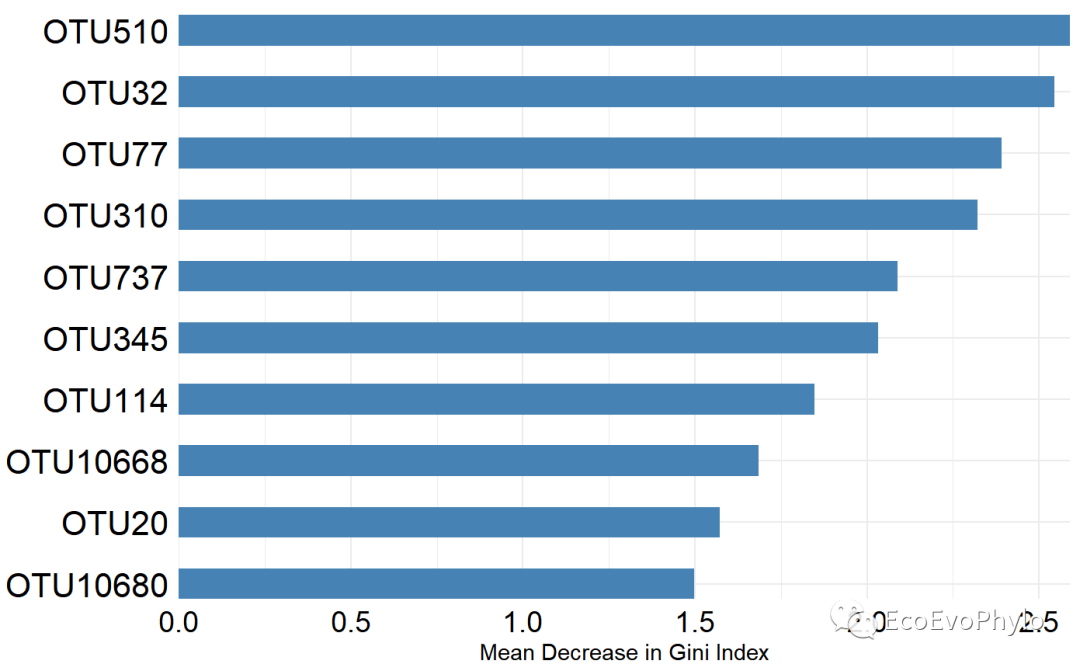
图4|特征量重要性top10条形图,p1。
4. 单因素非参数差异检验及绘图
对随机森林分析重要性变量top10进行kruskal-Wallis检验并提取显著性标记。这里只标记单因素kruskal-Wallis差异检验结果,后面再写如何标记多重比较的结果。可以参考R统计绘图-多变量单因素非参数差异检验及添加显著性标记图,自行修改代码。
# 4.1 单因素非参数差异检验
library(rstatix)
library(dplyr)
## 提取top10变量丰度数据
BC = spe[c("depth",rownames(imp))]
BC
## 批量对10个变量进行kruskal-Wallis检验及提取显著性标记
sig = matrix(data=NA,nrow = 10,ncol = 2,dimnames = list(names(BC[2:11]),c("species","sig")))
for (i in 2:11){
assign(paste(names(BC[i]),"kw",sep="."),kruskal.test(BC[,i],as.factor(BC[,1])));
tmp = get(paste(names(BC[i]),"kw",sep="."))
sig[i-1,] = c(names(BC[i]),ifelse(tmp$p.value >0.05,"ns","*"));
} # assign()将kruskal.test()的运行结果赋予指定变量名
kw = mget(paste(names(BC[2:11]),"kw",sep=".")) # mget()提取变量值到kw对象
kw$OTU510.kw # 列表对象
##将结果输出到本地
capture.output(kw,file = "kw.list.txt",append = FALSE)
## 提取显著性标记
sig = as.data.frame(sig)
head(sig)
图5|OTU510的单因素差异检验结果。

图6|top10单因素差异检验显著性标记表,sig。
# 4.2 计算数据均值与标准误
BC1 = data.frame(name = rownames(BC),BC[c(1:11)])
BC1
## 数据形式由"宽"变“长”
BC1 = gather(BC1,key="species","abundance",-name,-depth)
BC1
## 计算均值和标准误
BC2 = BC1 %>% group_by(depth,species) %>%
get_summary_stats(abundance,type = "mean_se") # 标准差用"mean_sd"计算
BC2
# 4.3 合并均值数据、显著性标记和imp值
da = merge(BC2,sig,by.x = c("species"),by.y = c("species"))
da$group = factor(da$depth,levels = c("A","B","C"))
da[da$depth %in% c("A","B"),"sig"] = NA # 组件差异检验显著性标记,保留再一个处理中。
da2 = merge(da,imp,by.x = c("species"),by.y = "row.names")
da2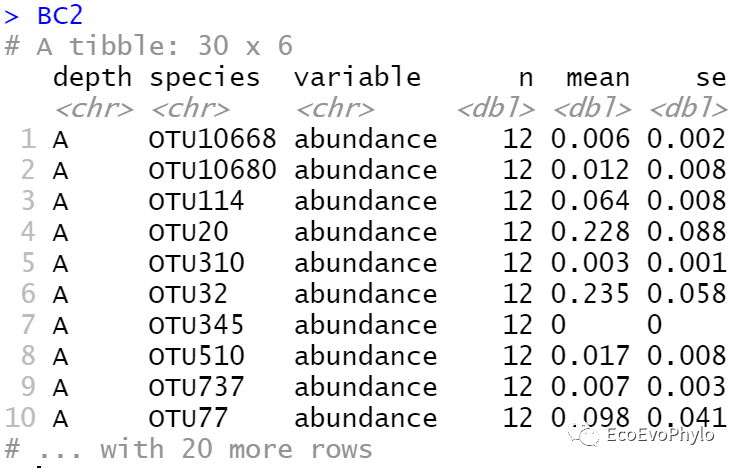
图7|top10均值与标准误表,BC2。

图8|top10的均值、标准误、差异显著性标记和重要性值合并表,da2。
# 4.4 绘制物种丰度条形图
p2 = ggplot(da2,
aes(x=mean,y=reorder(species,MeanDecreaseGini),fill=depth))+
geom_bar(position = position_dodge(),
width = 0.5,
stat = "identity")+
geom_errorbar(aes(xmin=mean-se,xmax=mean+se),
width=0.3,
color="black",size=0.5,
position = position_dodge(0.5))+
geom_text(aes(x=(mean+se),label=sig,group=depth),
hjust =0,nudge_x=0.5, # 显著性标签水平调整
nudge_y=0.075, # 显著性标签垂直调整,hjust/vjust:0(right/bottom)和1(top/left) 。
angle = -90, # 逆时针旋转90°
size=4.75,fontface="bold")+
theme_minimal() +
xlab("Abundance")+
scale_y_discrete(expand=c(0,0))+
scale_x_continuous(expand=c(0,0))+
theme(axis.text.y = element_blank(), # 物种顺序一致,为了后续拼图,隐藏物种名。
#axis.text.y = element_text(size=16,color="black"),
axis.text.x = element_text(size=14,color="black"),
axis.title.x.bottom = element_text(size=16,color="black"),
axis.ticks.y = element_blank(),
axis.title.y = element_blank(),
#panel.grid = element_blank() # 去除网格线
)
p2 # 柱子高低不一致,显著性标记输出到本地后,需要手动调整一下。
图9|top10差异检验条形图,p2。为了后续拼图没有显示变量名,没有输出到本地。
5. 随机森林+物种丰度差异检验组合图
使用patchwork包将上述两幅图拼在一起。
# 拼图
library(patchwork)
pdf("随机森林丰度组合图.pdf", width = 12,height = 8,family = "Times")
p1+p2+plot_layout(nrow = 1, widths = c(2, 2),
guides = "collect")
dev.off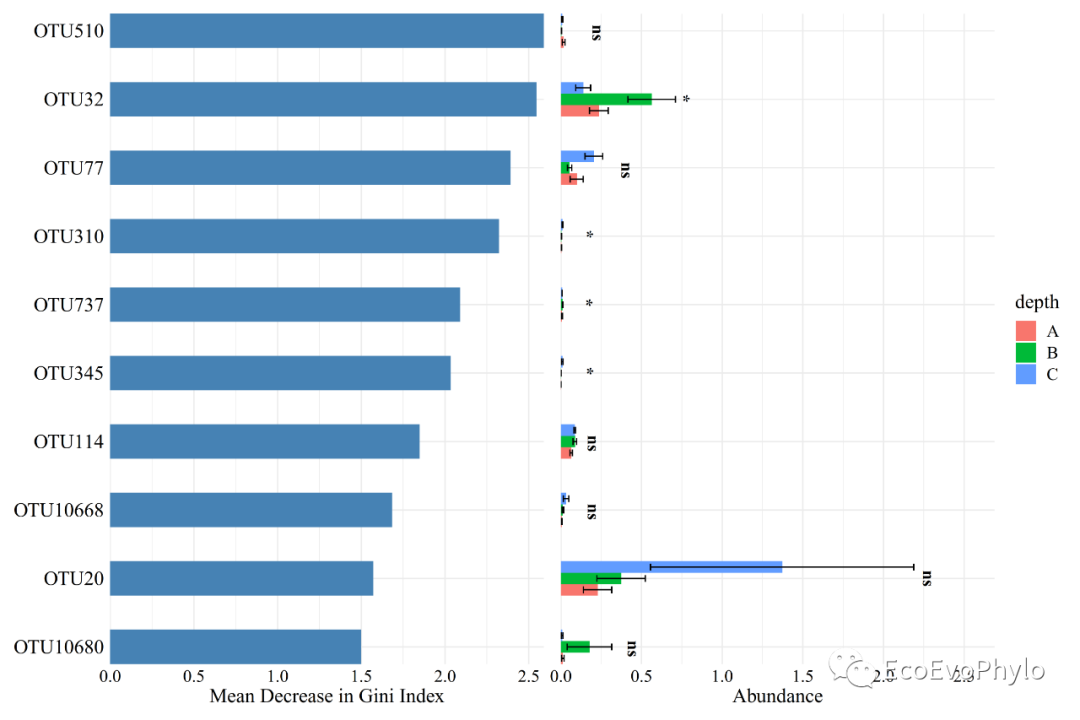
图10|随机森林分类分析+物种丰度组合图,p1+p2。
公众号后台发送“随机森林丰度组合图”或QQ群文件获取原始数据及代码。
参考资料
机器学习-分类随机森林分析(randomForest模型构建、参数调优、特征变量筛选、模型评估和基础理论等)
推荐阅读
R绘图-物种、环境因子相关性网络图(简单图、提取子图、修改图布局参数、物种-环境因子分别成环径向网络图)
R统计绘图-多变量相关性散点矩阵图(GGally::ggpairs())
R统计绘图-PCA分析绘图及结果解读(误差线,多边形,双Y轴图、球形检验、KMO和变量筛选等)
R统计绘图-corrplot热图绘制细节调整2(更改变量可视化顺序、非相关性热图绘制、添加矩形框等)
R统计绘图-环境因子相关性+mantel检验组合图(linkET包介绍1)
机器学习-分类随机森林分析(randomForest模型构建、参数调优、特征变量筛选、模型评估和基础理论等)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











