










比传统机器学习更先进的深度学习神经网络的二分类建模全流程分析教程
深度学习介绍和与传统机器学习的区别
深度学习(Deep Learning)是一种机器学习的分支,基于多层神经网络模型,能够自动从大量数据中学习特征并进行预测。深度学习通过层层的神经元结构提取数据的抽象信息,使其在图像识别、语音处理、自然语言处理等领域取得了显著成果。
深度学习与传统机器学习的区别:
1. 特征提取方式不同:
- 传统机器学习:依赖人工提取特征,通常需要专家对数据进行处理和特征工程,如PCA(主成分分析)或手动设计的特征。
- 深度学习:能够自动从原始数据中学习特征,尤其在复杂任务上可以通过多层神经网络自动捕捉高层次的抽象特征。
2. 模型结构:
- 传统机器学习:模型较为简单,通常是单层或少量层次的模型,如线性回归、支持向量机(SVM)等。
- 深度学习:模型深度较大,通常包括多个隐藏层(深层神经网络),如卷积神经网络(CNN)和循环神经网络(RNN)。
3. 数据依赖性:
- 传统机器学习:在中小规模数据上表现较好,但在海量数据上难以处理。
- 深度学习:依赖大量数据训练,数据越多,模型的表现越好,能够更好地应对海量数据和复杂任务。
4. 计算资源需求:
- 传统机器学习:计算量相对较低,可以在一般计算设备上运行。
- 深度学习:计算需求较高,通常需要高性能的GPU或TPU支持以加速训练。
5. 应用场景:
- 传统机器学习:在一些结构化数据(如表格数据)处理上依然表现优异,适合较简单任务。
- 深度学习:在图像、视频、语音等非结构化数据处理领域表现优越。
总的来说,深度学习适合复杂、海量数据的场景,而传统机器学习在小规模数据集上依然有其优势。
对要进行机器学习或深度学习的数据进行整理和预处理
分析模块位置
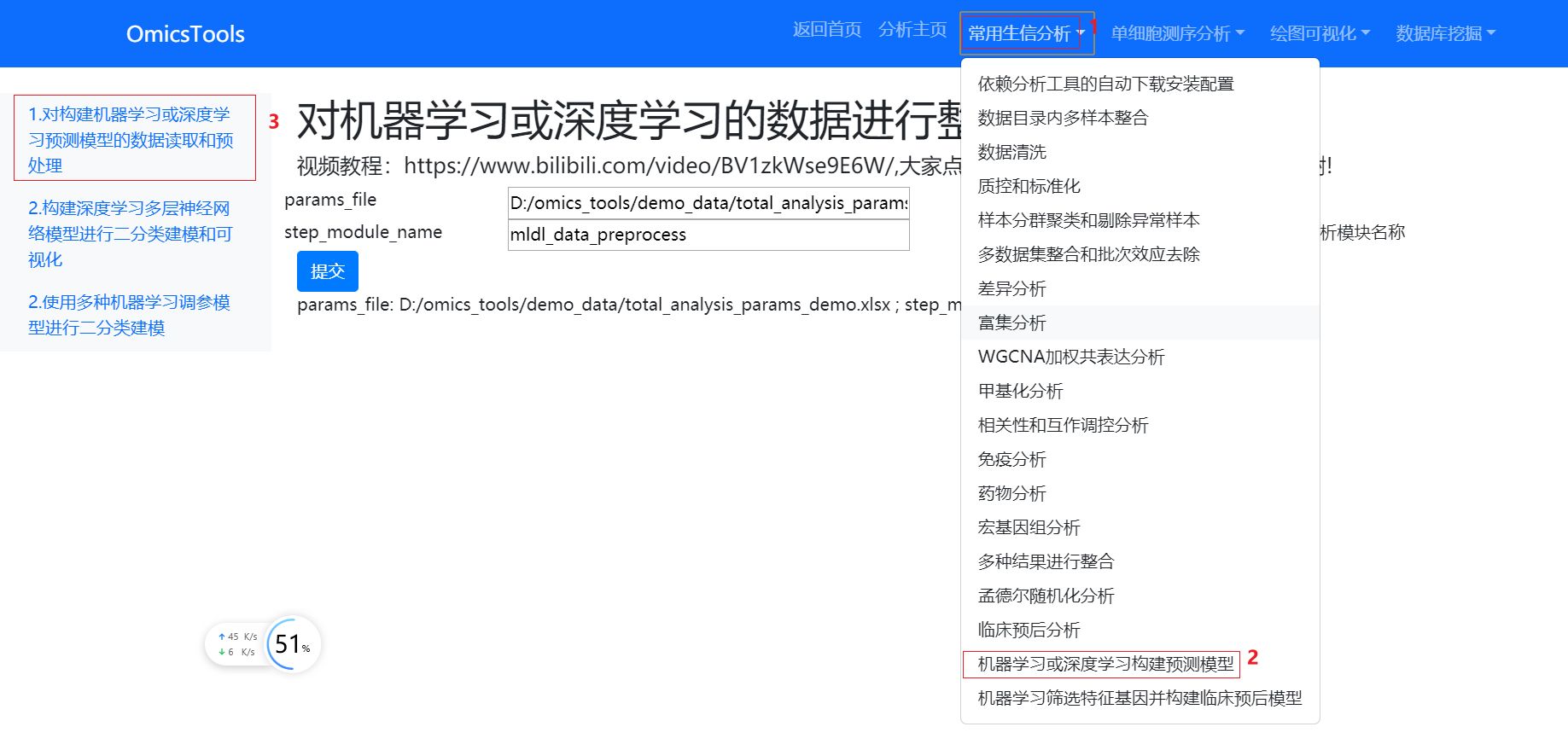
分析模块界面
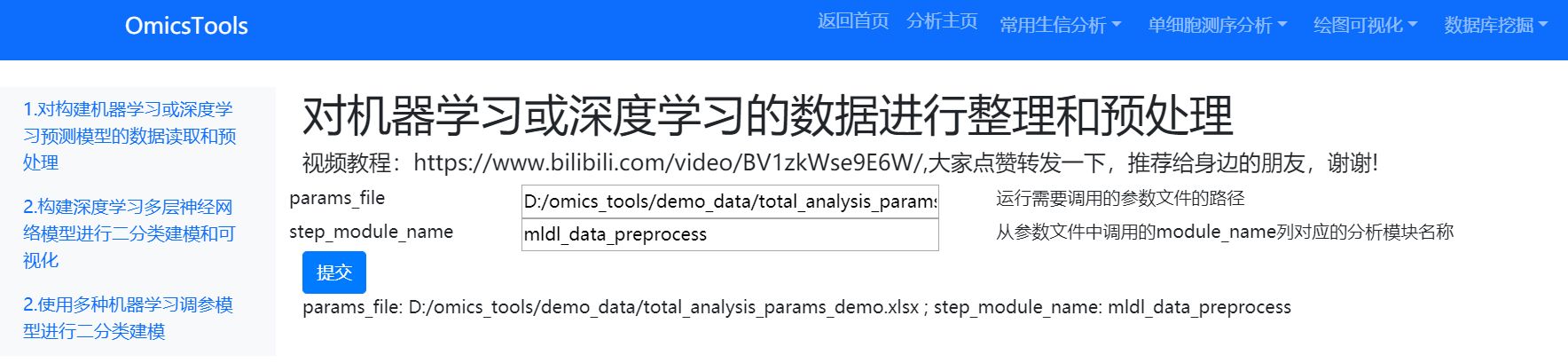
参数文件下载和使用
该模块的parms_file 需要给一个excel表的表格格式的参数文件,该参数文件可以在我的百度网盘中下载。
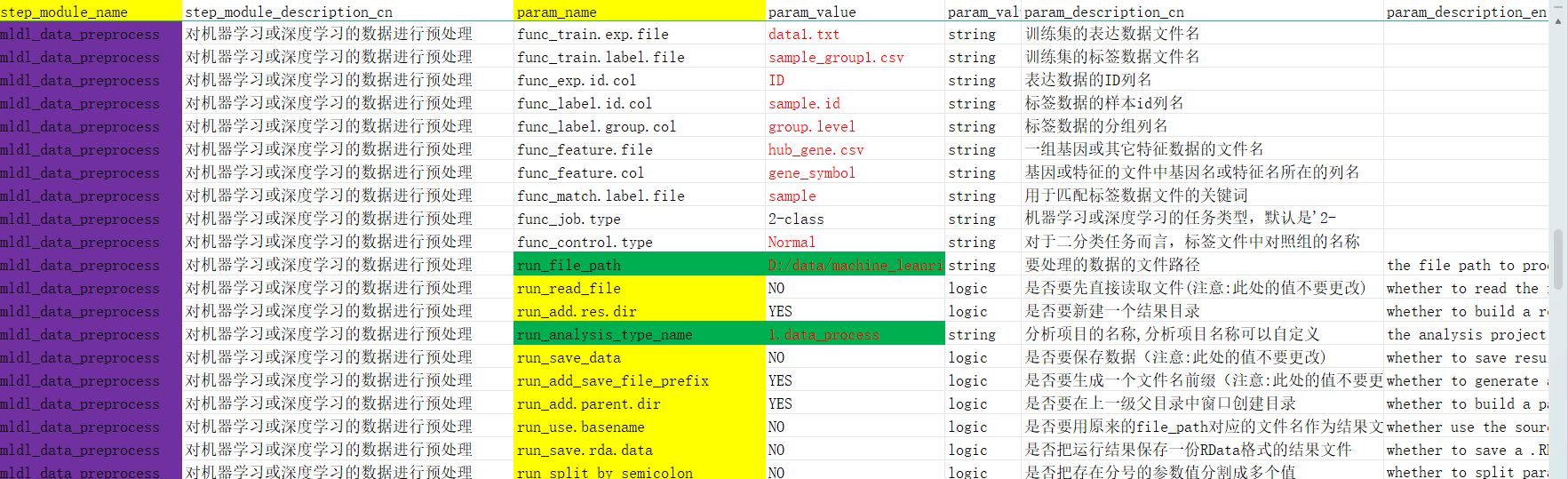
只需要在分析参数的这个xlsx的excel文件中修改一下mldl_data_preprocess分析模块下对应的在param_value列我标红的参数值,改成你自己的训练集和测试集文件所在的列名和文件中的基因id列名和样本id列名,样本分组列名即可,具体可以参考该模块下我的那个详细的教学视频,该视频观看链接已经放在了分析模块的内部了。
用到的训练集和测试集文件
文件目录下的所有文件
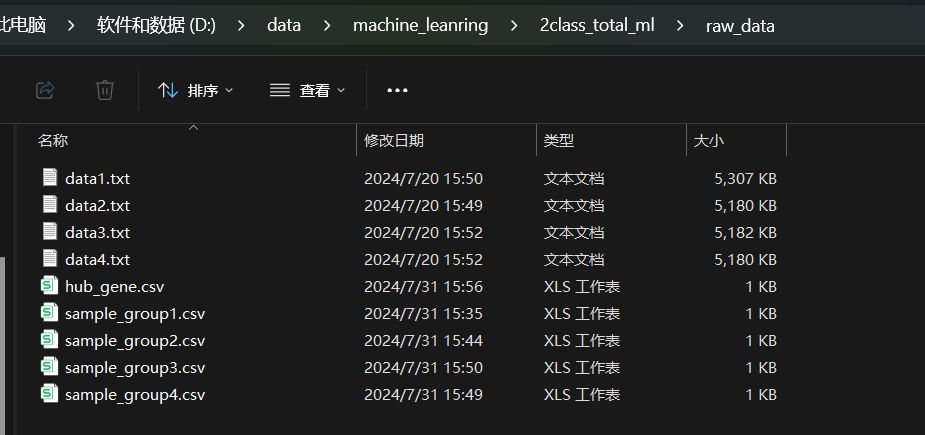
这是分析用到的所有数据文件存放的目录路径,其中:
- data1.txt是训练数据集文件,sample_group1.txt是该data1.txt对应的样本分组分类标签文件
- data2.txt, data3.txt, data4.txt是三个测试数据集文件,sample_group2.csv,sample_group3.csv,sample_group4.csv是这三个测试数据集分别对应的样本分组分类标签文件。当前这里是用了3个测试数据集文件和分类标签文件,大家也可以用更少或更多的测试数据集文件和分类标签文件
- hub_gene.csv 是机器学习或深度学习用到的一组关键基因列表,后面只会从data1.txt, data2.txt, data3.txt, data4.txt这些训练数据集和测试数据集中提取出这一组基因对应的表达数据进行建模和预测。
文件的具体内容
data1.txt, data2.txt, data3.txt, data4.txt这些基因表达数据集的文件内容
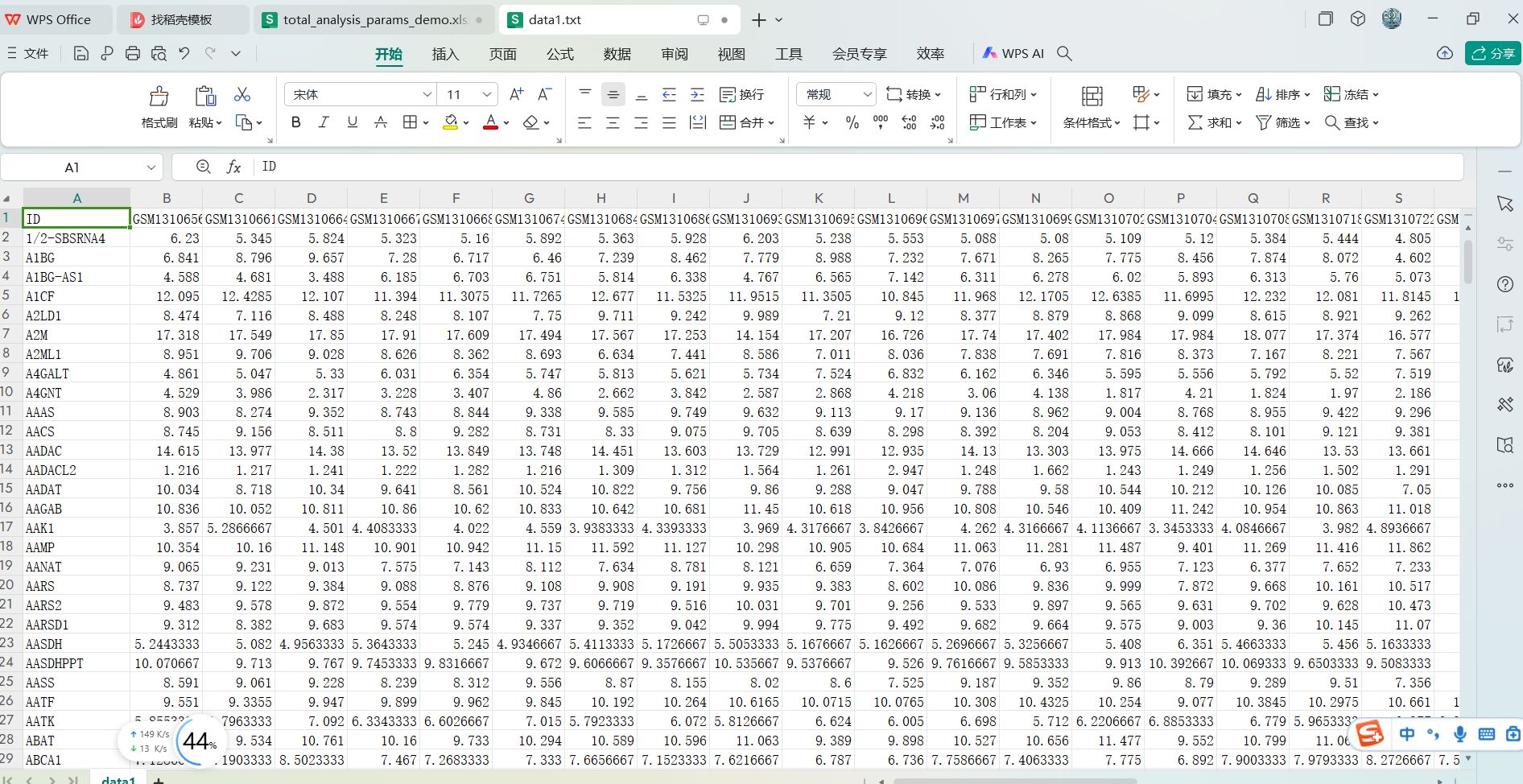
这些文件基本上都是第1列为基因名列,其它列都是样本列的这样的数据格式,即是一个行名为基因名,列名为样本编号的基因表达矩阵。
sample_group1.csv, sample_group2.csv,sample_group3.csv,sample_group4.csv对应的文件内容
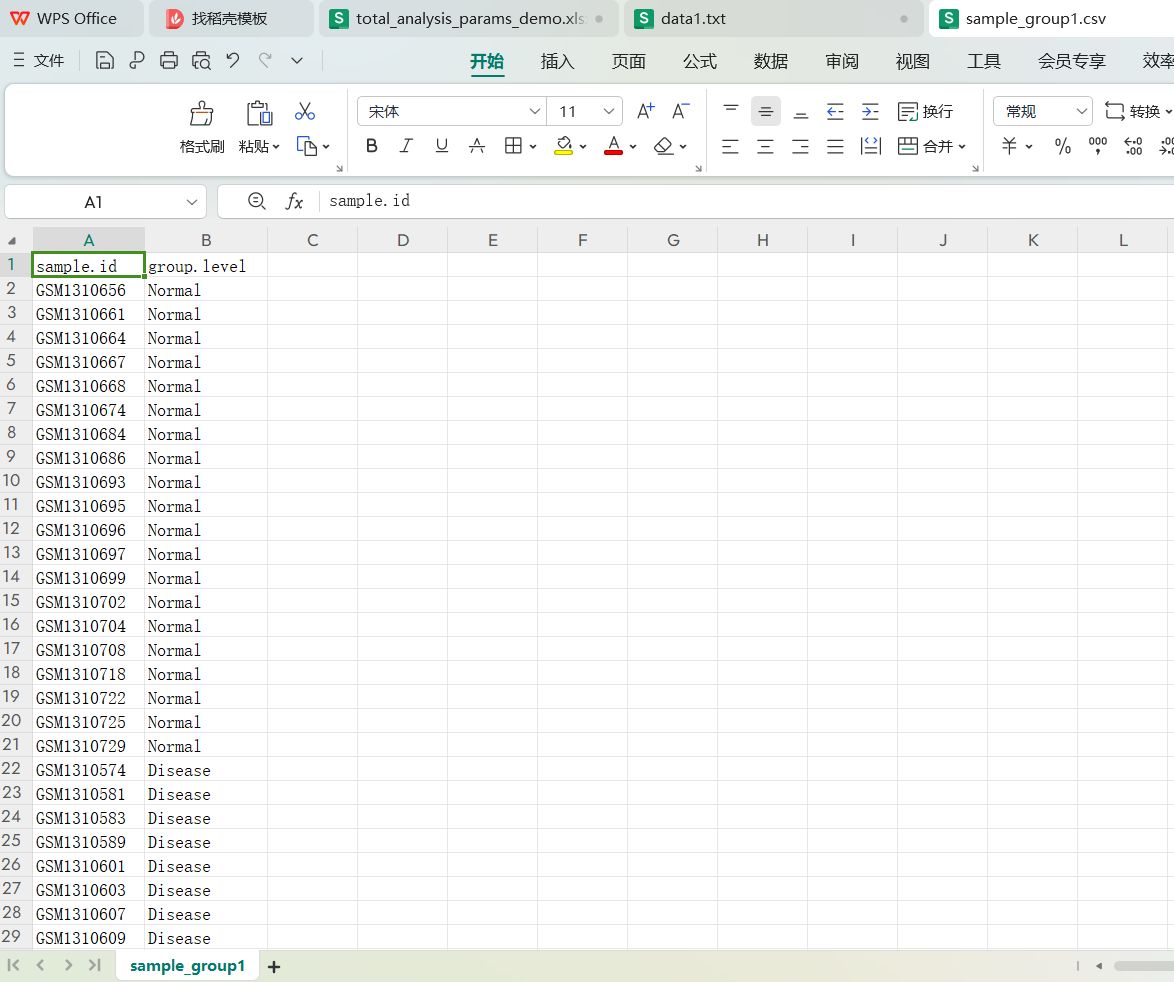
这些分类标签文件都只有两列,列名是sample.id和group.level, sample.id是样本id编号,group.level是样本的分类组名,这里的两个分类是Normal和Disease.
hub_gene.csv对应的文件内容
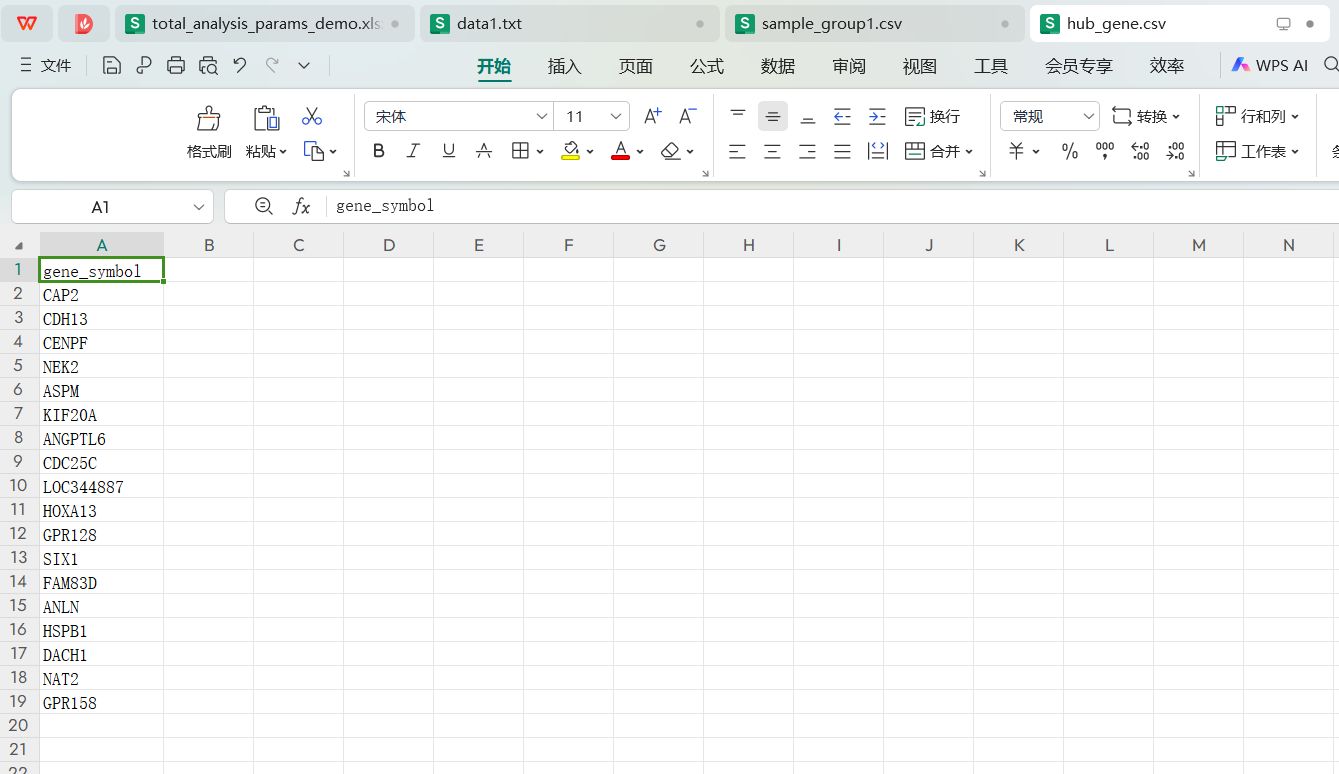
该文件中只有一组基因列表,列名是gene_symbol, 后续在分析中只会用到这一组基因进行数据处理,特征筛选和建模预测。
该分析模块的运行结果
分析界面执行完成的显示信息
运行完成的结果目录
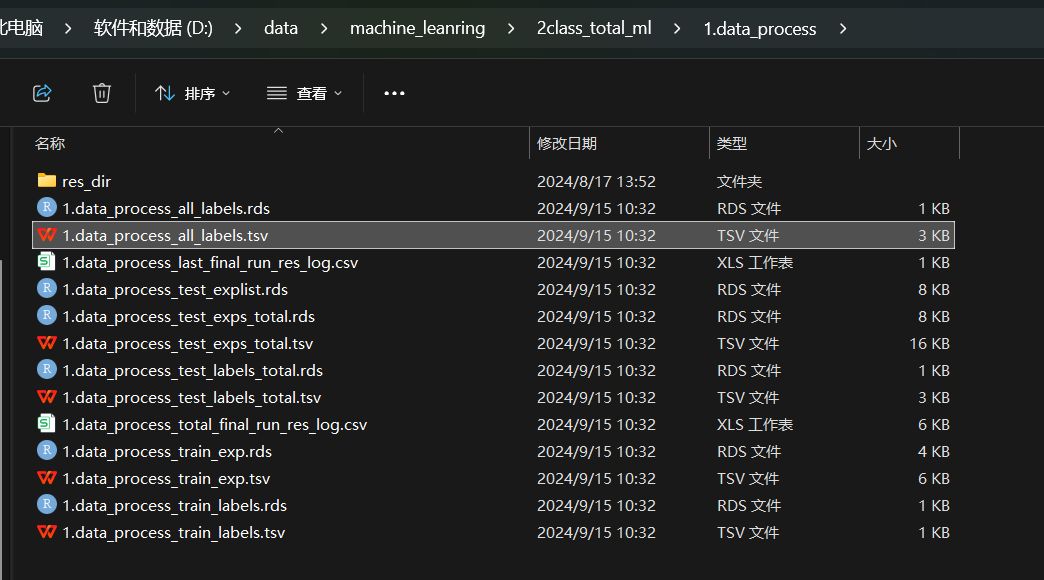
结果文件包括预处理好的测试集和训练集的表达数据集文件和分类标签文件,每个文件都有一份tsv文件和rds文件,tsv文件可以直接用excel打开,rds文件可以用Rstudio打开,二者的内容基本一致。
运行完成的文件内容
表达数据集的处理好的内容如下
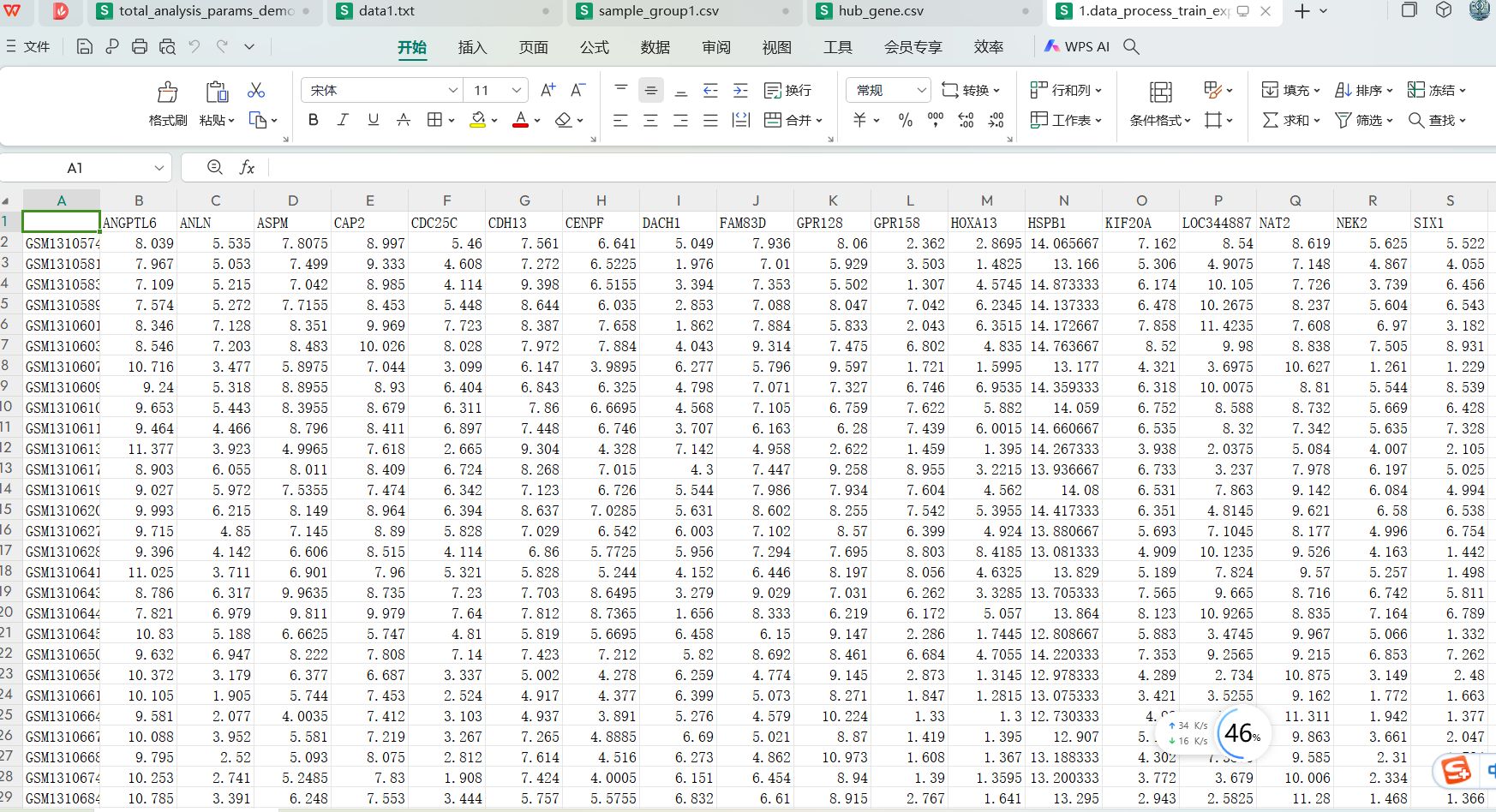
提取除了一组hub gene对应的表达矩阵,行名是样本编号,列名是这一组hub gene对应的表达数据
分组标签处理好的内容如下:
训练集标签文件处理好的内容:训练集标签文件data_process_train_labels.tsv处理好的内容如下:
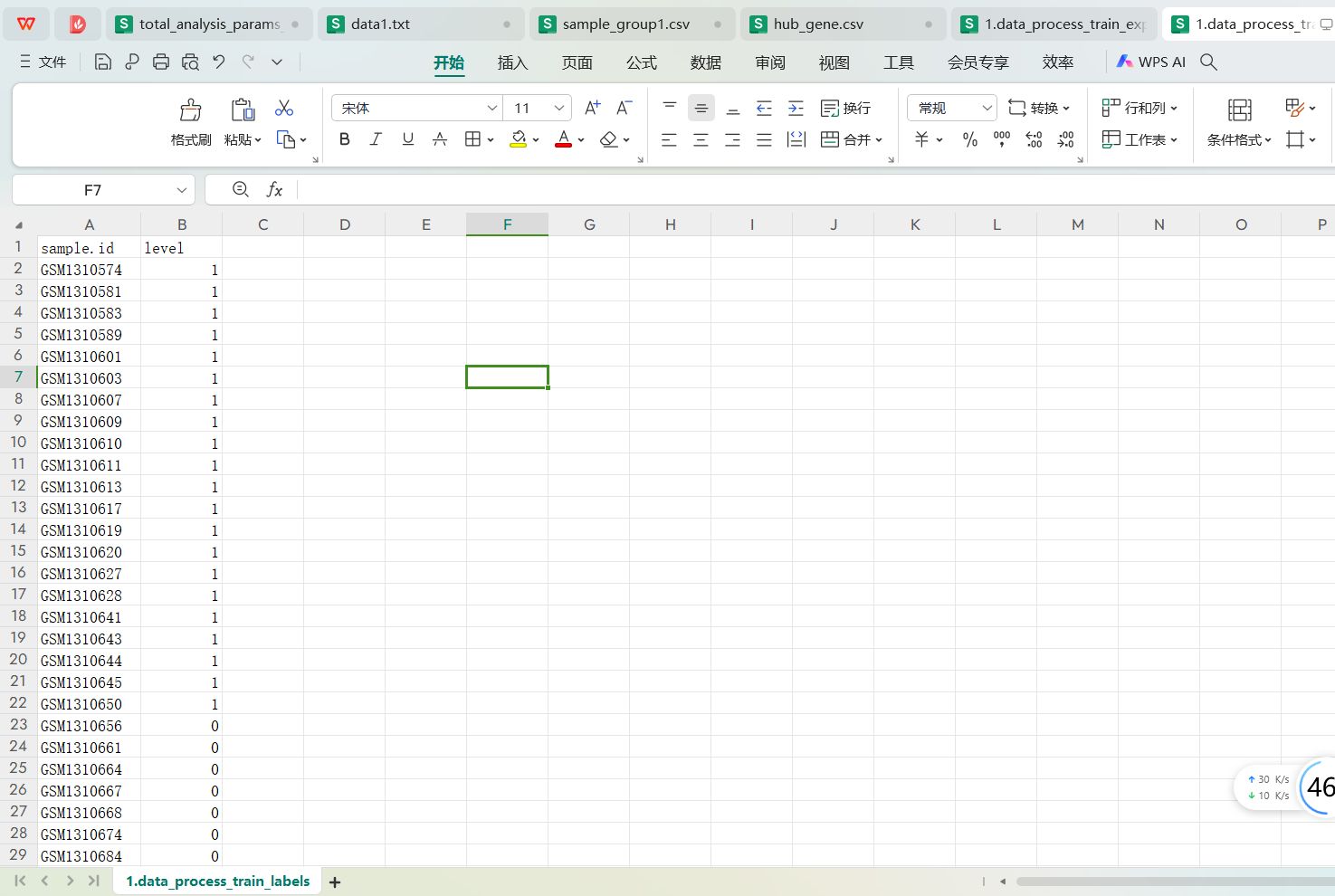
有两列数据,第一列是样本id,第二列是0,1分类标签,把原来的Normal变成了0, 把Disease变成了1
多个测试数据集的分类标签处理文件处理好的内容如下:1.data_process_test_labels_total.tsv文件内容:
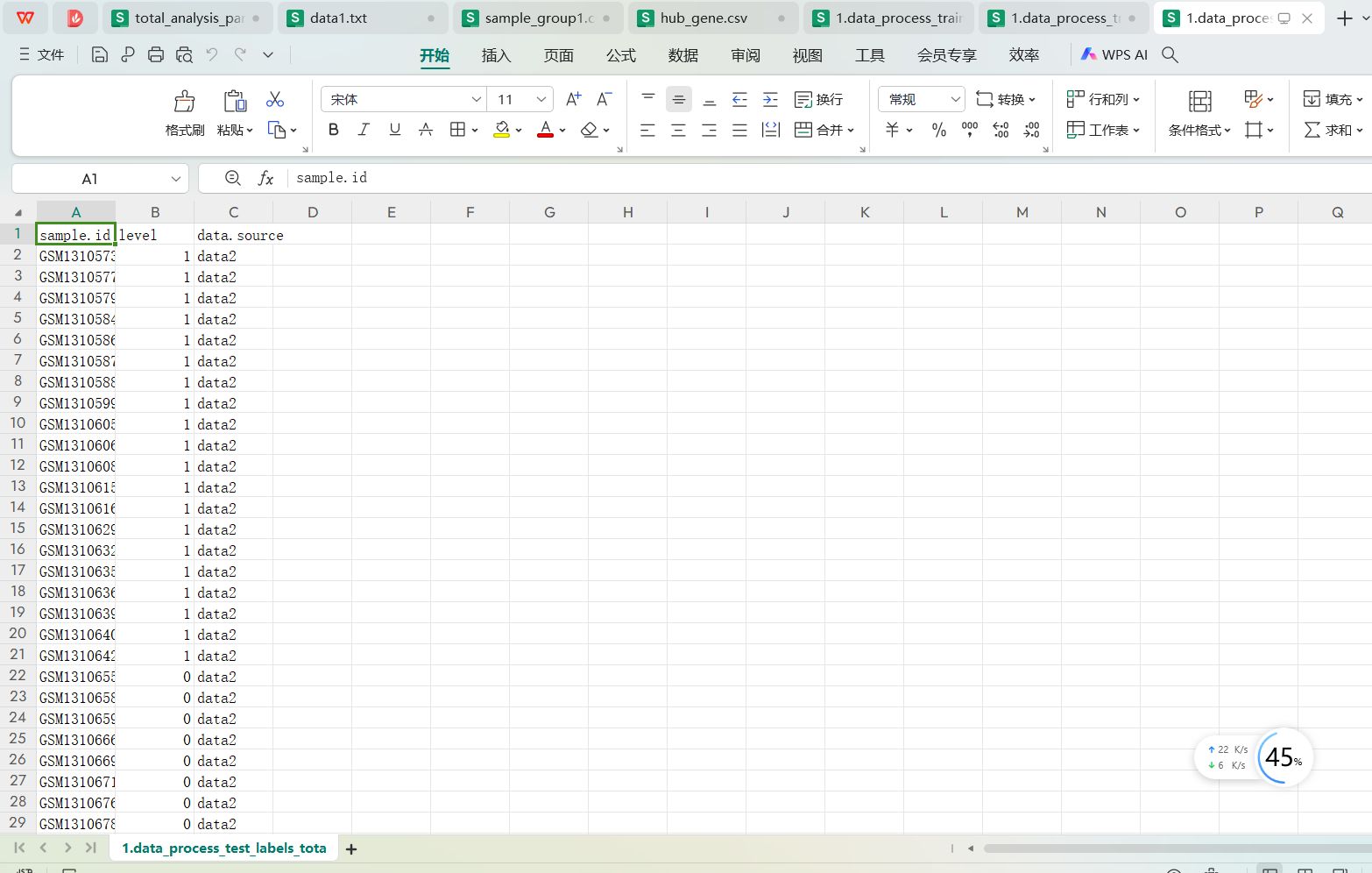
这里有三列数据,第一列是样本id,第二列是0,1分类标签,把原来的Normal变成了0, 把Disease变成了1,第三列是样本对应的数据集来源,因为这里用到了三个测试集,所有data.source列是data2,data3, data4这三个数据集的名称。
构建深度学习多层神经网络模型进行二分类预测
深度学习神经网络的架构示意图
分析模块位置
分析参数文件的位置和内容
分析参数文件位置
分析参数文件在我的电脑本地位置为:D:/omics_tools/demo_data/total_analysis_params_demo_test.xlsx
在百度网盘的位置为:
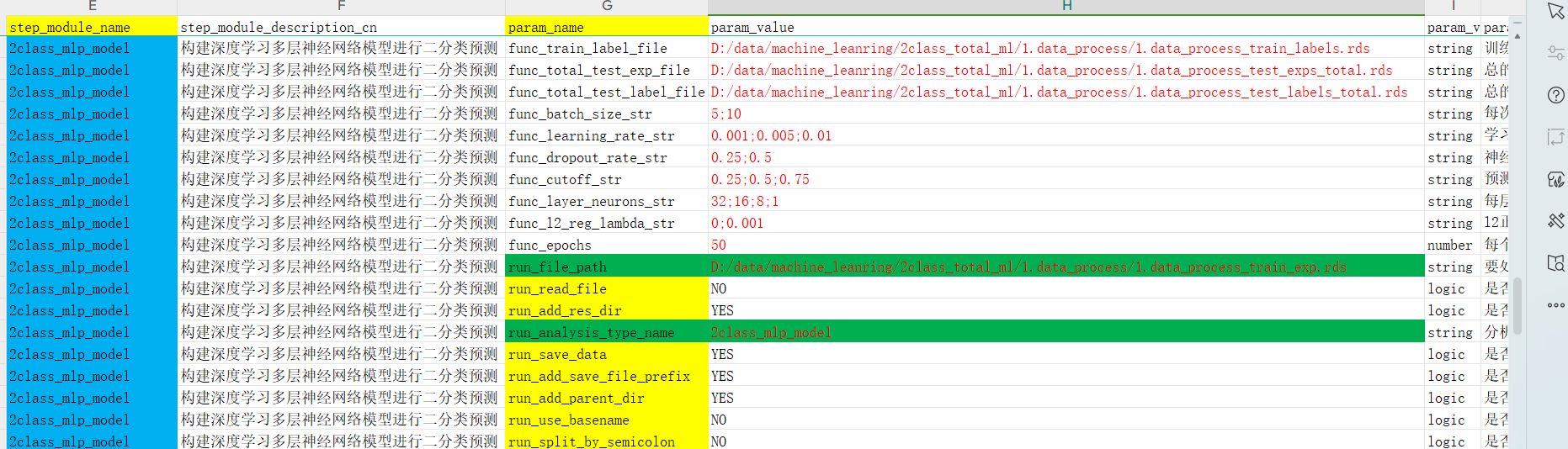
参数文件内容
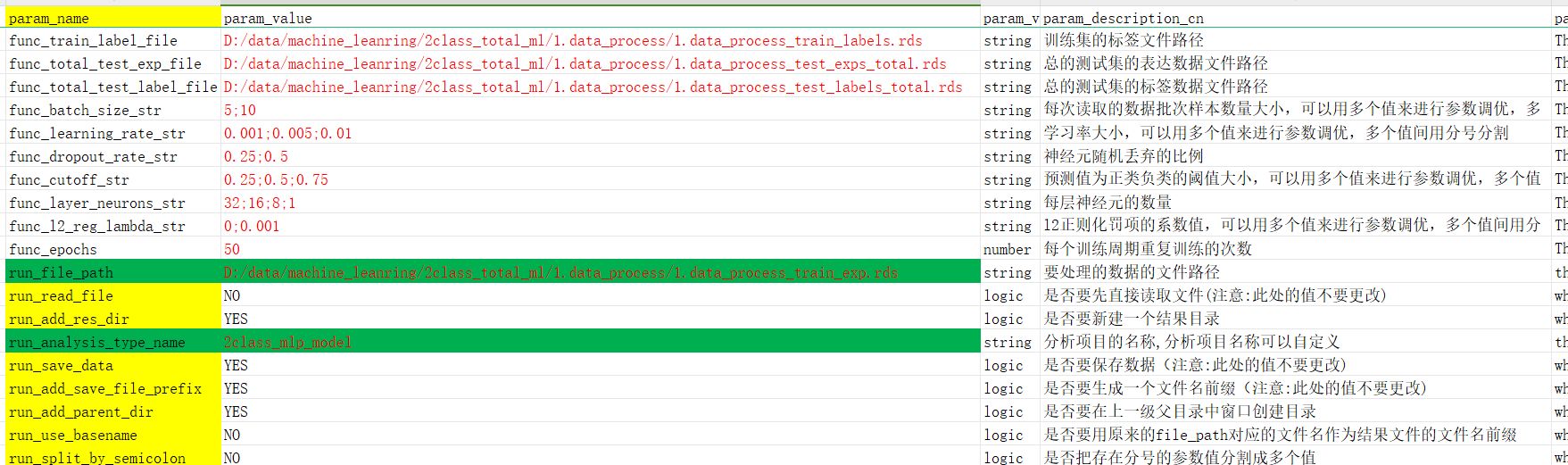
参数文件修改讲解
在这个分析模块里面,只需要修改我标红的参数值即可,没有标红的参数值用默认的就行,不需要修改。
分析的需要数据文件修改
func_train_label_file
D:/data/machine_leanring/2class_total_ml/1.data_process/1.data_process_train_labels.rds
func_total_test_exp_file
D:/data/machine_leanring/2class_total_ml/1.data_process/1.data_process_test_exps_total.rds
func_total_test_label_file
D:/data/machine_leanring/2class_total_ml/1.data_process/1.data_process_test_labels_total.rds
run_file_path
D:/data/machine_leanring/2class_total_ml/1.data_process/1.data_process_train_exp.rds
这四个数据文件路径都在上一步数据预处理的结果目录下。
神经网络设计训练调优需要修改的参数
神经网络训练的batch_size修改
batch_size参数值填写介绍batch_size是func_batch_size_str对应的参数值,默认用了5和10两个batch_size,可以多用几个batch_size进行训练,最后选取最好的结果,多个batch_size之间用分号;隔开。
func_batch_size_str
5;10
Batch size 是指在一次前向传播和反向传播中传递给神经网络的样本数量。简单来说,batch size 决定了每次模型权重更新时所使用的样本数量。Batch size 的选择对模型训练效率、收敛速度和内存占用都有影响。
常见的 Batch Size 设置:1. 小 Batch size(例如 1、8、16):
- 优点:每次更新都基于较少的样本,模型权重更新频繁,有助于更快地跳出局部最优解。适合较小数据集和内存有限的情况。
- 缺点:梯度波动较大,收敛速度可能会较慢,且训练可能会不稳定。
2. 大 Batch size(例如 64、128、256):
- 优点:梯度较为平滑,收敛更加稳定,训练效率高。
- 缺点:需要更多内存资源,并且可能陷入局部最优解,不利于模型泛化。
3. 中等 Batch size(例如 32、64):
- 综合了小和大 Batch size 的优缺点,通常是一个较为稳健的选择,尤其是对于中等规模的数据集。
很多GEO的数据集可能只有几十个样本,这里以40个样本的训练为例
由于你只有 40个样本,建议选择较小或中等的 batch size。具体设置可以参考以下几点:
1. Batch size = 8 或 16:
- 在40个样本中,8或16的batch size可以是一个比较好的选择。这样可以保持梯度更新的频率适中,同时不会造成过大内存开销。
- Batch size = 8:40个样本将分为5个batch。
- Batch size = 16:40个样本分为2-3个batch,更新频率较低,但模型每次迭代使用更多样本来计算梯度。
2. 小 batch size(如4):
- 如果你的模型较为复杂,或者计算资源有限,你可以将 batch size 设置得更小,如 4。这样,模型会在每次更新时处理更少的样本,更新更频繁。
3. 特殊情况:Batch size = 1 或 40:
- Batch size = 1:称为逐样本更新,虽然每次更新频繁,但容易导致梯度波动较大,可能使训练不稳定。
- Batch size = 40:一次性使用全部样本,相当于“批量梯度下降”,训练稳定但梯度更新慢,可能导致模型需要更多迭代才能收敛。
对于你的40个样本,建议你可以从 batch size = 8 或 16 开始尝试,兼顾更新频率和计算效率。如果训练不稳定或者过拟合现象严重,可以进一步调整 batch size 或结合其他正则化手段。
学习率设置
参数值填写介绍学习率(Learning Rate) 是神经网络训练过程中最重要的超参数之一,它决定了模型在每次梯度更新时权重的调整幅度。合适的学习率可以加快模型的收敛速度,而不合适的学习率可能导致模型无法有效学习或收敛到次优解。
学习率是func_learning_rate_str对应的值,我默认是填了0.001;0.005;0.01这几个值
func_learning_rate_str
0.001;0.005;0.01
如何设置合适的学习率学习率的影响:
1. 学习率过大:
- 优点:训练速度快。
- 缺点:模型可能会跳过全局最优解,梯度更新幅度过大,导致损失函数波动剧烈,无法收敛,甚至发散。
2. 学习率过小:
- 优点:更精确地找到全局最优解。
- 缺点:训练速度非常慢,模型需要更多迭代次数才能收敛,可能陷入局部最优解,训练时间较长。
- 一般而言,常用的初始学习率通常介于 0.001 到 0.1 之间。
- 选择几个不同的学习率,比如 0.1、0.01、0.001、0.0001,然后在训练中测试每个学习率的效果,选择最优的学习率。
神经元丢弃比例dropout设置
参数值填写介绍dropout神经元丢弃比例在分析参数中是func_dropout_rate_str对应的参数值,默认使用了0.25;0.5这两个值,多个值间用分号;隔开,在训练后会从所有参数训练的结果中选出最好的结果。
func_dropout_rate_str
0.25;0.5
Dropout 是一种防止神经网络过拟合的正则化技术,特别在深度神经网络中应用广泛。它的基本原理是:在每一次训练过程中,随机丢弃(即"关闭")一部分神经元,避免神经元之间过度依赖特定的激活模式,从而提高模型的泛化能力。
Dropout的工作原理:- 在前向传播时,对于每一层的神经元,以一定的概率 p 随机将一部分神经元“关闭”,即将它们的输出设为0,而其他神经元继续工作。
- 在反向传播时,仅对未关闭的神经元进行梯度更新。
- 在测试阶段,所有神经元都保持激活,但它们的输出会乘以 1 - p 来补偿训练过程中丢弃的神经元数量。
Dropout 的值通常表示被丢弃神经元的比例,范围是 0 到 1。常见的设置是选择一个适当的丢弃比例,以找到训练和泛化性能之间的平衡。
1. 较低的 Dropout 值(0.1-0.3):
- Dropout 值设置较低时,只丢弃较少的神经元,神经网络的表达能力保持较强,但过拟合的可能性依然存在。
- 适用于较简单的模型,或者较小的训练数据集。
2. 适中的 Dropout 值(0.4-0.5):
- 这是较常见的 Dropout 设置。通常 0.5 是一个推荐的起点,这意味着在训练过程中,随机丢弃 50% 的神经元。这个值能有效防止神经元过度拟合训练数据,并且保留了足够的表达能力。
- 适用于中等规模的数据集和较为复杂的网络结构。
3. 较高的 Dropout 值(0.6-0.8):
- 设置较高的 Dropout 值(比如 0.6-0.8)会丢弃更多的神经元,这种设置可以防止模型严重过拟合,但也可能导致模型训练不稳定或收敛缓慢。
- 适用于非常复杂的神经网络或训练数据量较大的情况,但需要谨慎使用。
1. 模型的复杂性:
- 对于简单模型(例如只有几层的浅层网络),可以使用较低的 Dropout 值(如 0.1-0.3),因为模型本身不容易过拟合。
- 对于深层神经网络(例如有多层隐藏层),推荐使用 0.5 左右的 Dropout 值。
2. 数据集的规模:
- 如果数据集较大,模型容易学到更多的有用特征,因此可以适当减少 Dropout(如 0.3-0.5),以便充分利用数据。
- 如果数据集较小,则需要更强的正则化来防止过拟合,因此可以适当增加 Dropout(如 0.5-0.7)。
二分类的分类阈值cutoff选择
参数值填写介绍func_cutoff_str
0.25;0.5;0.75
这里的二分类cutoff阈值是func_cutoff_str对应的值,默认用了0.25;0.5;0.75这三个值,多个值间用分号;隔开。
神经网络模型预测的结果是一个0-1的概率值,我们需要对预测的概率值设置一个分类的阈值,大于这个阈值cutoff就归为分类标签1,小于这个阈值就归为分类标签0.
这里每层神经元的激活函数都用的Relu激活函数
神经网络的层数和每层的神经元数量选择
参数值填写介绍func_layer_neurons_str
32;16;8;1
这里神经网络的层数和每层数量是func_layer_neurons_str对应的值,默认值是32;16;8;1表示神经网络一共有四层,第一个隐藏层层有32个神经元,第二个隐藏层有16个神经元,第三个隐藏层有8个神经元,输出层有1个神经元。
如何选择神经元的层数和每层神经元的数量?对于一个包含20多个基因表达数据和40个样本的神经网络模型,网络的层数和每层神经元数量的选择取决于任务的复杂性(如分类、回归等)以及是否存在过拟合的风险。
以下是一般的建议:
1. 网络层数:
- 由于数据集的规模较小(样本数仅40个),不建议使用过深的神经网络。通常,1到3层的隐含层就足够。
- 层数越多,网络的复杂性越高,但也更容易过拟合。在小样本情况下,可以从1-2层开始尝试。
2. 每层神经元数量:
- 第一层的神经元数量可以设置为与输入特征(基因表达数,20多个)相当或稍多,例如 20-64个。
- 后续层的神经元数量可以逐层递减。例如,第二层可以设置为 32-16个 神经元。
- 为了避免过拟合,可以使用Dropout正则化或者L2正则化。
可以先从简单的结构开始,逐步调整模型复杂度,观察验证集的表现。
l2正则化罚项设置
参数值填写介绍func_l2_reg_lambda_str
0;0.001
这里神经网络的l2正则化罚项是通过func_l2_reg_lambda_str参数来设置,默认的值是0;0.001,多个值之间用分号隔开。
如何设置合适的l2正则化罚项系数?L2正则化(也称为权重衰减)是神经网络中常用的一种正则化技术,用于防止模型过拟合,提高其泛化能力。以下是对L2正则化的详细介绍以及如何设置L2正则化系数的建议。
1. 什么是L2正则化
L2正则化通过在损失函数中添加一个基于模型权重的罚项,限制权重的大小,从而防止模型在训练数据上过度拟合。具体来说,L2正则化会惩罚权重向量的平方和,使得权重趋向于较小的值。

作用
- 防止过拟合:通过限制权重的大小,L2正则化减少了模型对训练数据的过度依赖,从而提升其在未见数据上的表现。
- 提高模型的泛化能力:使模型更加简洁,避免复杂模型在训练数据上表现良好但在测试数据上表现不佳的情况。
- 稳定训练过程:防止权重变得过大,避免数值不稳定的问题。
2. L2正则化系数的设置
正则化系数 ( λ ) 决定了L2罚项在损失函数中的权重,进而影响模型训练过程中的权重更新。选择合适的 (λ ) 对于模型性能至关重要。
影响因素
- 模型复杂度:
- 复杂模型:具有大量参数的深层神经网络可能需要较强的正则化(较大的 ( λ ))。
- 简单模型:参数较少的模型可能只需要较弱的正则化(较小的 ( λ ))。
- 数据集大小:
- 小数据集:更容易过拟合,可能需要较大的 ( λ )。
- 大数据集:过拟合风险较低,可以使用较小的 ( λ )。
- 任务性质:
- 高风险任务:如医疗诊断,可能更倾向于强正则化以确保模型简洁可靠。
- 其他任务:根据具体需求调整 ( λ )。
推荐的 ( lambda ) 范围
- 常见范围:通常在 1e-5 到 1e-2 之间。
- 0.0001 (1e-4):适用于大多数情况,作为初始值。
- 0.001 (1e-3):常用的默认值。
- 0.01 (1e-2):用于需要较强正则化的场景。
定义一组候选的 ( λ ) 值,例如 [0.0001, 0.001, 0.01, 0.1]。
- 训练多个模型,每个模型使用不同的 ( λ ),并在验证集上评估其性能。
- 选择在验证集上表现最好的 ( λ )。
深度学习训练轮数epochs设置
参数值填写介绍func_epochs
50
Epochs(轮次) 是神经网络训练过程中的一个关键概念,它指的是整个训练数据集被完整地送入模型进行一次前向和反向传播的过程。理解和合理设置epochs的数量对于模型的训练效果和性能优化至关重要。
如何设置合适的epochs1. 什么是Epochs
- 定义:
- Epoch(轮次):一次Epoch表示将所有训练样本完整地通过神经网络一次。换句话说,模型在一个Epoch中见到了所有的训练数据一次。
- Batch(批次):由于一次处理整个数据集可能计算量过大,通常将数据集分成若干小批次(Batch),每个Batch包含一定数量的样本。一个Epoch包含多个Batch的训练过程。
- 示意图:
数据集(40个样本)
├─ Batch 1 (16)
├─ Batch 2 (16)
└─ Batch 3 (8)
一个Epoch = Batch 1 + Batch 2 + Batch 3
2. Epochs的重要性
- 模型收敛:
- 随着Epochs的增加,模型逐渐学习和拟合训练数据,损失函数逐步减小,性能指标(如准确率)逐渐提升。
- 避免过拟合和欠拟合:
- 欠拟合:Epochs过少,模型未充分学习,表现为训练损失高、验证损失高。
- 过拟合:Epochs过多,模型在训练数据上表现良好,但在验证或测试数据上表现较差,泛化能力下降。
选择合适的Epochs数量需要综合考虑模型复杂度、数据集大小、训练速度以及避免过拟合等因素。以下是一些常见的方法和建议:
a. 观察损失曲线和性能指标
- 训练过程监控:
- 在训练过程中,实时监控训练损失(Training Loss)和验证损失(Validation Loss)以及其他性能指标(如准确率)。
- 损失曲线分析:
- 训练损失持续下降,验证损失先下降后上升,说明模型开始过拟合,此时应停止训练。
- 训练损失和验证损失均下降,继续训练可能提升性能。
- 训练损失和验证损失趋于平稳,说明模型已基本收敛。
- 初始尝试:
- 对于中小型数据集(如40个样本),可以从 100到500 个Epochs开始尝试。
- 动态调整:
- 根据训练和验证损失的变化趋势,动态调整Epochs的数量。通过交叉验证选择一个使模型在验证集上表现最好的Epochs。
a. 初始Epochs设置
- 建议范围:100 到 500 个Epochs。
- 原因:样本量较小,过多的Epochs可能导致过拟合,因此需要结合Early Stopping等策略动态调整。
- Epochs的选择需要结合数据集规模、模型复杂度和训练过程中的表现。
- 合理设置Epochs可以通过监控损失曲线、使用Early Stopping和学习率调度等策略实现,避免过拟合和欠拟合。
- 实践中,推荐从 100 到 500 个Epochs开始,我的OmicsTools神经网络建模预测模块会结合Early Stopping等方法动态调整,并通过交叉验证和实验记录找到最适合的设置。
分析界面
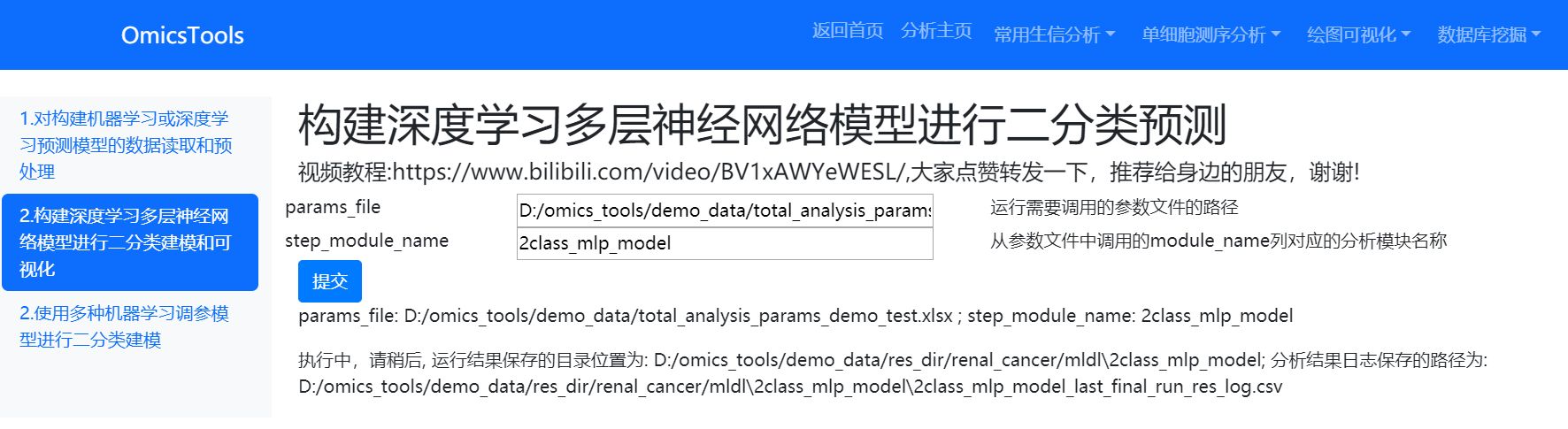
点击提交后,会自动弹出一个终端界面进行深度学习的分析计算:
等计算完成后,该终端界面会自动关闭
运行完成的结果
结果目录和文件
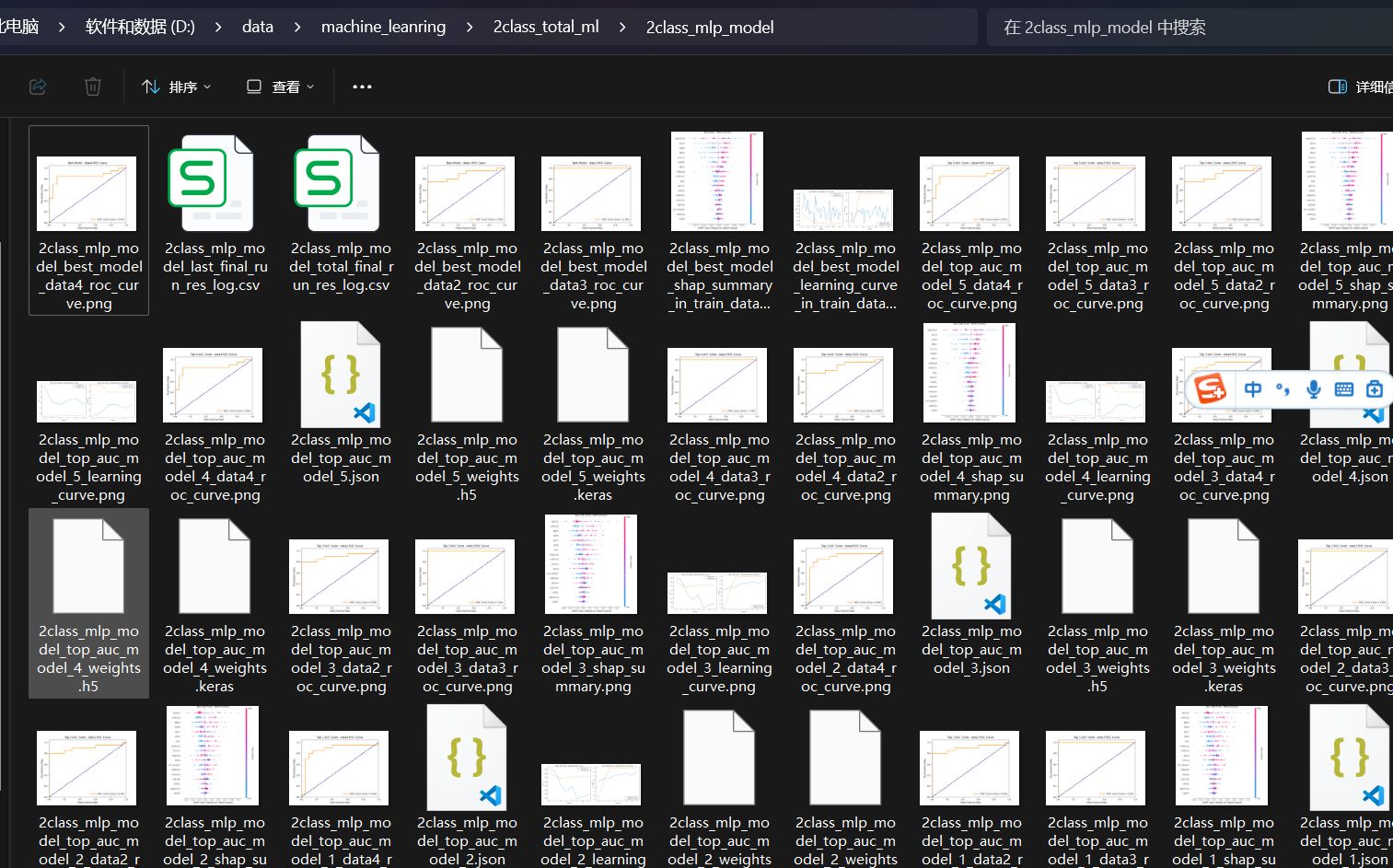
分析结果包括在训练集中的一个最优模型,以及5个在测试集中auc score最高的top5个模型,以及5个在测试集中roc auc值最高的top5 个模型。
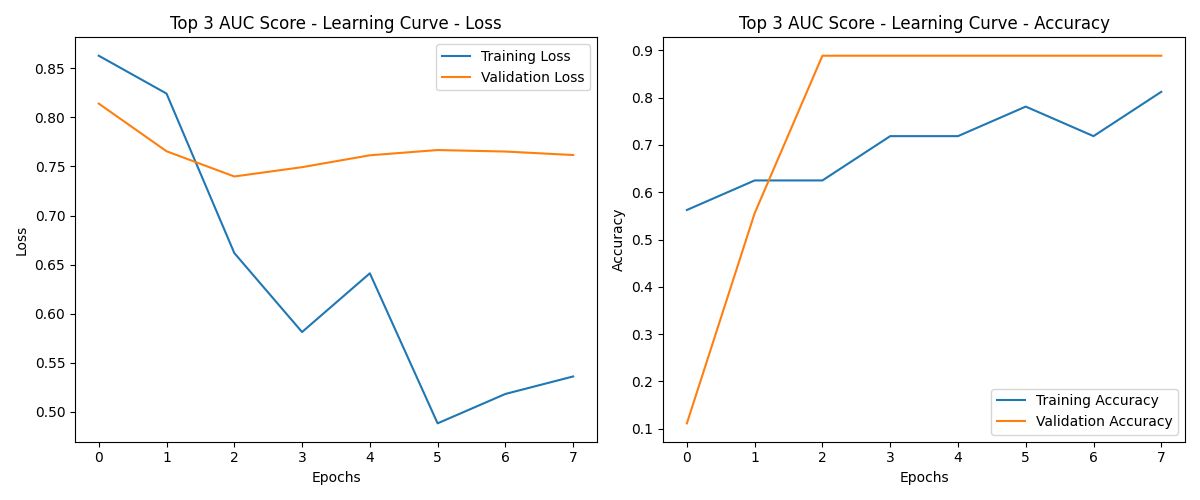
训练过程的损失曲线和性能指标
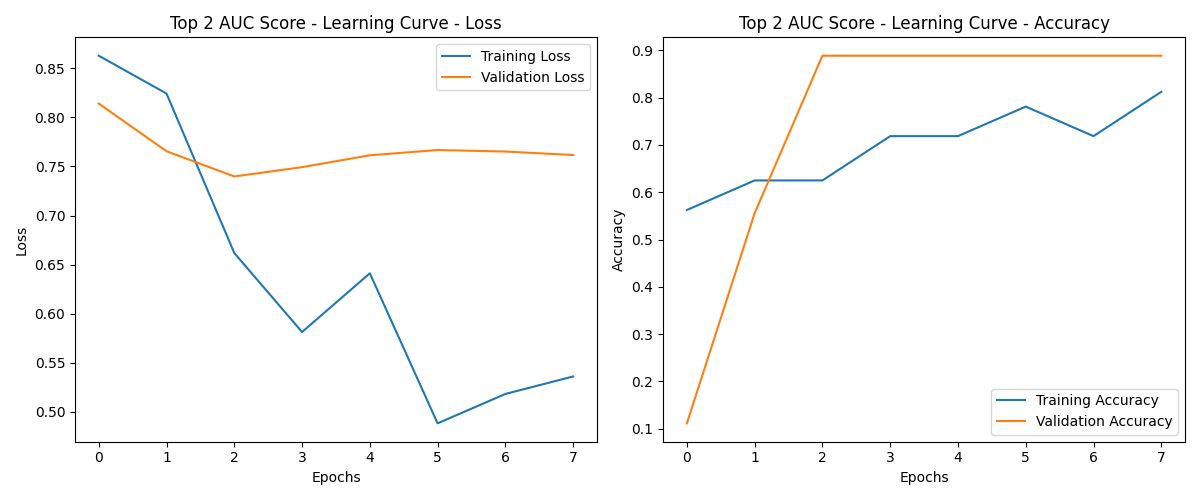
左侧图:损失曲线解读
- Training Loss(蓝线):
- 随着Epochs的增加,训练损失持续下降,说明模型在训练集上逐渐拟合得更好。
- 但是,到第4个Epoch时,训练损失出现了明显的波动,这可能是由于数据集较小或优化器设置导致的。
- Validation Loss(橙线):
- 验证损失在最初几个Epoch下降,但从第2-3个Epoch后开始趋于平稳甚至略有上升。
- 这种现象可能意味着模型开始在训练集上过拟合:虽然训练损失持续降低,但验证损失没有继续降低,反而变得更高,表明模型在验证集上泛化能力变弱。
右侧图:准确率曲线解读
- Training Accuracy(蓝线):
- 随着训练进行,训练集上的准确率逐步上升,说明模型对训练数据的学习效果在增强。
- 在4个Epoch之后,训练准确率趋于较高,但仍然波动,说明训练过程不够稳定。
- Validation Accuracy(橙线):
- 验证集上的准确率在最初迅速上升,在2个Epoch之后几乎稳定在一个很高的值(接近90%)。
- 尽管验证损失有些上升,但验证准确率保持平稳,说明模型的预测在验证集上依旧较为准确,但要留意这种情况可能是由于验证集上较简单的数据模式或者模型对验证集过度拟合。
总结
- 目前模型在训练集上表现较好,但存在轻微的过拟合现象。验证集上的准确率虽然保持较高,但验证损失的上升值得注意。
- 通过引入正则化、Early Stopping 和调整学习率等方法可以进一步提升模型的稳定性和泛化能力。
各种参数组合最好的aucscore值对应的模型
aucscore含义
auc Score 是一种用于衡量分类模型性能的指标,特别适用于 不平衡数据集,即正负样本数量差异较大的情况下。它结合了 精确率(Precision) 和 召回率(Recall),是它们的调和平均数。
主要概念:


适用场景:
- 数据不平衡时:auc Score 在数据不平衡时能提供更好的模型性能评估。当正负样本数量相差悬殊时,单独看准确率(Accuracy)会有误导性,但 auc Score 会平衡考虑模型对正负样本的预测表现。
- 二分类问题:auc Score 常用于二分类问题,例如疾病诊断(正类为有病,负类为健康)。
举个例子:
假设在癌症检测中,模型预测出 100 个样本为阳性(有病),其中 80 个样本实际确实是阳性(True Positives),但也有 20 个是误报(False Positives)。同时,实际中有 100 个病人,而模型只找到了 80 个,剩下 20 个漏检了(False Negatives)。
- Precision = 80 / (80 + 20) = 0.8
- Recall = 80 / (80 + 20) = 0.8
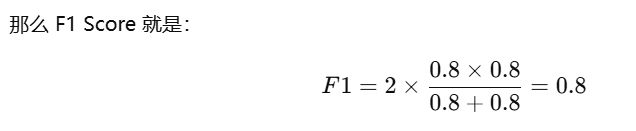
通过 auc Score,我们可以得到一个综合评价,来判断模型在精确性和全面性之间的平衡表现。
汇总的auc score结果文件
运行完成会生成一个2class_mlp_model_all_result_FS.csv文件会生成排序好的每个参数组合对应的data2,data3,data4三个测试集和train训练集以及三个测试集均值的auc score值,用于筛选最好的参数组合下性能最优的模型。我们一般选ave_test aucscore最高的参数组合的模型。
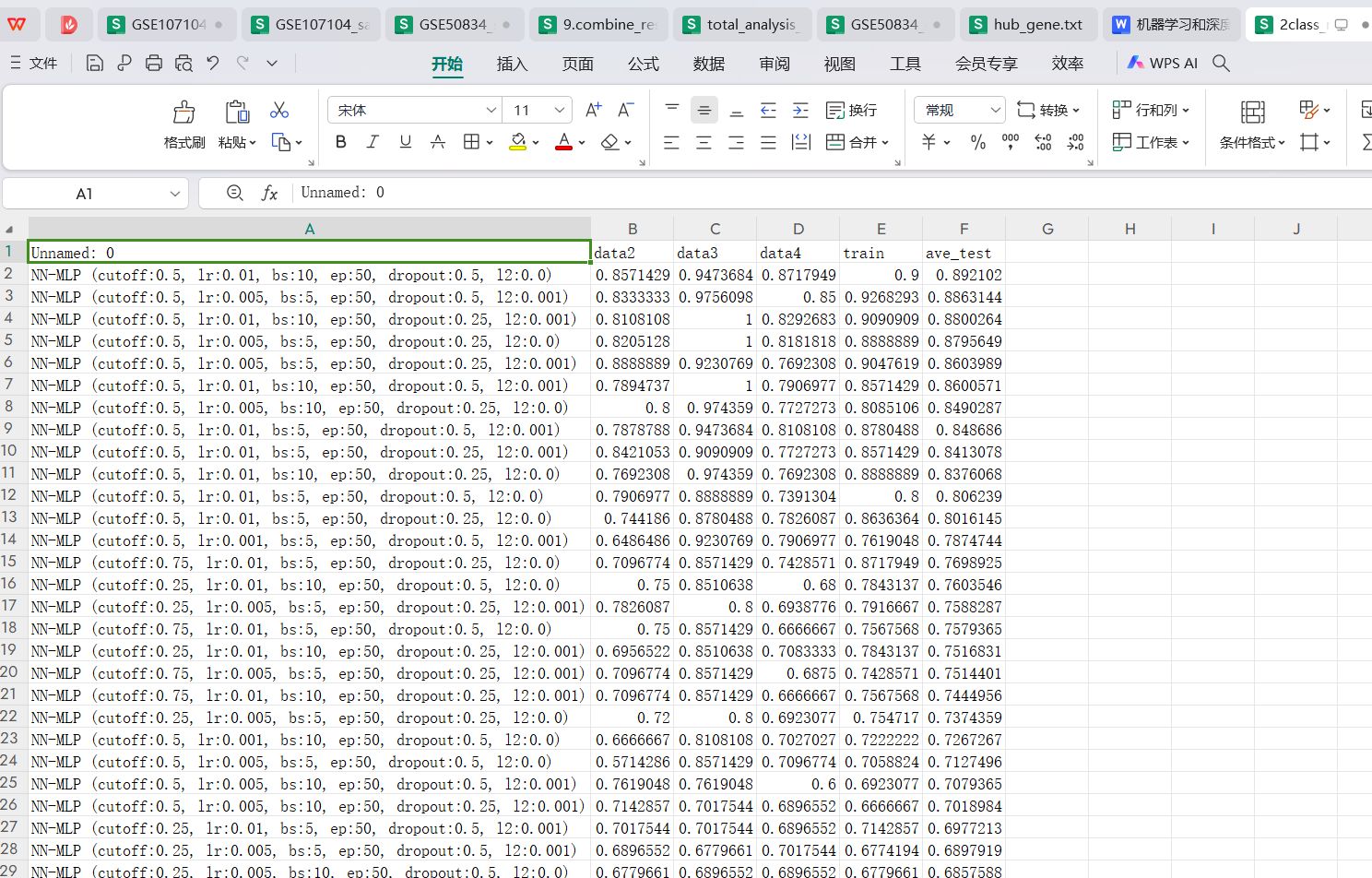
各种参数组合最好的auc值对应的模型
ROC AUC值的含义
ROC AUC 是一种用于评估分类模型性能的指标,特别适合于 二分类问题,通过综合考虑模型的 真阳性率(True Positive Rate, TPR) 和 假阳性率(False Positive Rate, FPR),可以评估模型在不同阈值下的表现。下面详细解释 ROC 曲线和 AUC 的概念。

ROC 曲线通过绘制在不同阈值下的 TPR 和 FPR 值来反映模型的整体性能。理想的模型 ROC 曲线应该靠近左上角,意味着在几乎不增加假阳性的情况下大幅提高真阳性。
3. ROC AUC 的优势
- 阈值无关:与准确率等指标不同,ROC AUC 不依赖特定的分类阈值,而是考察模型在不同阈值下的表现,因而更全面。
- 数据不平衡的鲁棒性:在样本不平衡(正负样本数量差异较大)的情况下,ROC AUC 仍然能很好地评估模型性能,而准确率往往会被误导。
2. AUC (Area Under the ROC Curve)不同范围的值的意义
AUC 是 ROC 曲线下的面积,是一个 数值化的指标,用来衡量模型的分类能力。AUC 值的范围在 0 到 1 之间。
- AUC < 0.5:模型性能低于随机猜测,说明模型存在问题,可能完全反转了正负类的判断。
- AUC = 0.5:随机猜测,模型没有任何区分正负样本的能力。
- 0.7 ≤ AUC < 0.8:模型表现一般,具有一定的分类能力,但可能需要进一步优化。
- 0.8 ≤ AUC < 0.9:模型表现良好,具有较强的区分能力。
- 0.9 ≤ AUC < 1.0:模型表现非常好,几乎能很好地区分正负类。
- AUC = 1:完美分类器,模型在任何阈值下都能完美区分正负样本。
汇总的auc score结果文件
运行完成会生成一个2class_mlp_model_all_result_auc.csv文件会生成排序好的每个参数组合对应的data2,data3,data4三个测试集和train训练集以及三个测试集均值的auc score值,用于筛选最好的参数组合下性能最优的模型。我们一般选ave_test auc最高的参数组合的模型。
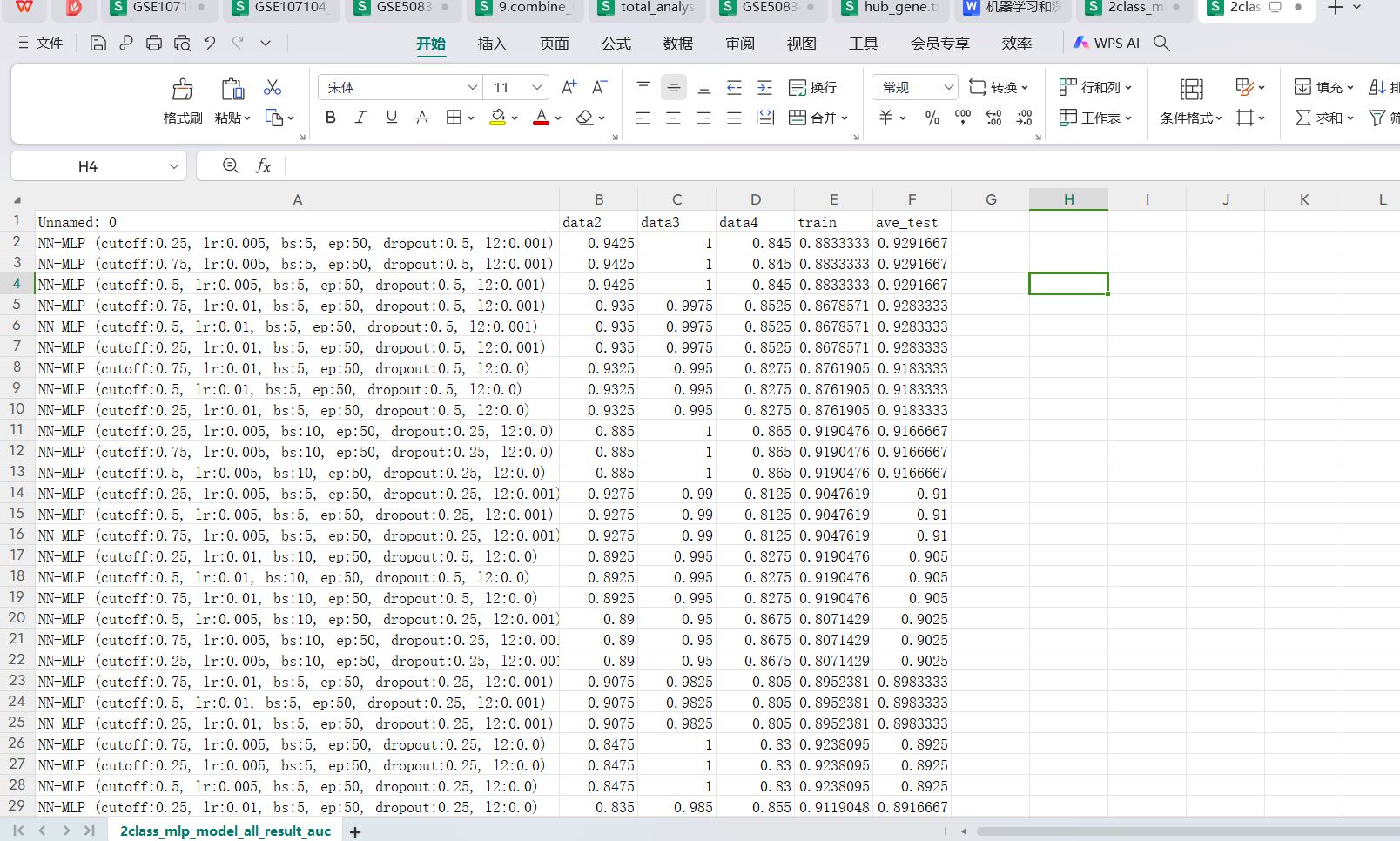
使用最前沿最先进的可解释性shap图来解释top5 排名最高的模型
shap图介绍
SHAP 图 是一种用于解释机器学习模型的工具,特别是黑箱模型(如深度学习或集成方法),帮助我们理解模型是如何做出决策的。SHAP 通过量化每个特征对模型预测的贡献,揭示了各个特征如何影响模型的输出。以下是对 SHAP 的详细解释:
1. 什么是 SHAP?SHAP,全称 SHapley Additive exPlanations,基于 Shapley值,这是合作博弈论中的一种方法,用于衡量每个参与者在合作中的贡献。引入机器学习领域时,每个特征被看作是博弈中的“玩家”,模型预测结果被看作是合作的“收益”。SHAP 值度量了每个特征对预测结果的独立贡献。
2. SHAP 的工作原理SHAP 的基本思想是,计算一个特征在不同组合下对模型输出的边际贡献。具体来说,它计算当某个特征值加入到其他特征组合时,模型输出的变化。这种计算方式可以给出每个特征在模型决策中的平均贡献,从而帮助我们解释模型。
3. 为什么使用 SHAP?- 解释性强:相比其他解释方法,SHAP 值具有良好的理论基础,能提供全球解释和局部解释。每个特征的贡献可以通过 SHAP 图清晰展示出来。
- 公平性:SHAP 值通过考虑所有特征组合,提供了对各个特征影响的公平评价,能够量化每个特征的边际贡献。
- 适用广泛:SHAP 可以应用于许多不同类型的机器学习模型,如回归、分类、深度学习等。
- 显示了所有特征对模型的全局影响。通过将所有样本的 SHAP 值绘制成散点图,可以看到哪些特征对模型预测影响最大。
- 横轴:SHAP 值,表示特征对模型输出的影响方向和大小。
- 颜色:表示特征值的大小,通常红色表示特征值高,蓝色表示特征值低。
- 正负 SHAP 值:正值的 SHAP 值意味着特征推动模型输出为正类(或预测值更高),负值意味着特征推动模型输出为负类(或预测值更低)。
- 全局影响:通过 summary plot,可以看到哪些特征对模型预测的整体影响最大,点的分布越广,特征影响越大。
- 模型解释:帮助数据科学家和工程师理解模型的决策逻辑。
- 模型调试:通过分析 SHAP 图可以发现模型的偏差或过拟合问题。
- 特征重要性分析:帮助识别哪些特征对模型的贡献最大,以便优化特征选择。
SHAP 图是一种非常强大的工具,它提供了对机器学习模型透明和公平的解释。它通过量化每个特征对模型输出的贡献,帮助我们理解模型是如何做出决策的,以及哪些特征对预测结果影响最大。这对于改进模型、发现数据问题、以及在高风险决策场景中(如医学、金融)解释模型尤为重要。
运行完成的结果的shap图展示和结果解读
运行完成后会绘制出F1 score top5 模型的5个shape图,以及auc score top 5的shap图。
可解释性shap图是最前沿最先进的机器学习和深度学习的可解释图形,可能以往太旧的生信分析和机器学习建模论文一般都没有这种图。
以其中的一个shap图为例:
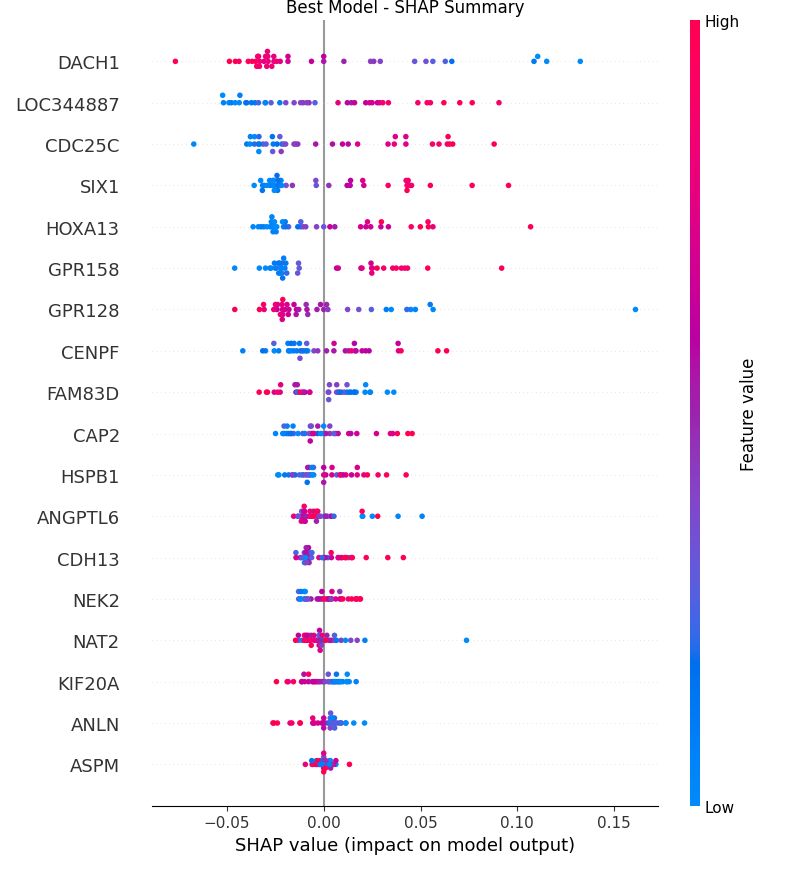
这个图是一个 SHAP Summary Plot,用于解释机器学习模型中特征对模型输出的影响。我们可以从几个方面来解读:
1. 图表概览
- 横轴(SHAP value):代表每个特征对模型预测结果的影响。值越靠右(正方向),说明该特征越倾向于推动模型输出为正类(例如预测患病)。反之,值越靠左(负方向)说明该特征越倾向于推动模型输出为负类(例如预测健康)。
- 纵轴(特征名称):列出了在模型中使用的各个特征。每一行表示一个特征对模型输出的影响。
- 颜色(Feature value):颜色条表示每个点对应特征值的大小。红色表示特征值高,蓝色表示特征值低。例如,红色代表特征值较高,而蓝色则表示特征值较低。
2. 解读
- 影响力的大小:每一行中的点在横轴上的分布反映了该特征对模型预测的影响。横坐标上的散点越分散,说明该特征对模型预测的影响越大。例如,`DACH1` 特征的 SHAP 值分布较宽,表示它对模型预测的贡献很大。而像 `ASPM` 这样的特征分布较窄,说明它的贡献较小。
- 特征值与影响的关系:
- 如果高特征值(红色点)主要分布在右边(正向),说明该特征值越大,越倾向于推动预测为正类。例如,`DACH1` 和 `ANGPTL6` 的红色点在右边较多,说明这些特征的高值会推动模型输出为正类。
- 如果高特征值(红色点)主要分布在左边(负向),说明该特征值越大,越倾向于推动预测为负类。图中部分特征,如 `CDC25C`,其红色点更多分布在左侧,表示该特征的高值倾向于推动模型输出为负类。
- 零线的含义:零线表示该特征对模型输出的影响为中性,即对正负类预测没有明显倾向。如果大多数点都接近 0,说明该特征对模型的预测影响较小。
3. 结论
从这个 SHAP Summary 图表中可以得出以下结论:
- 主要影响特征:`DACH1`、`CDC25C`、`LOC344887` 等特征对模型的预测影响较大,因为它们的 SHAP 值分布较广,说明这些特征的值变化对预测的影响显著。
- 特征值与预测的关系:
- 一些特征(如 `DACH1`、`ANGPTL6`)的高值(红色点)主要推动模型预测为正类。
- 另一些特征(如 `CDC25C`、`HSPB1`)的高值主要推动模型预测为负类。
通过这个图,你可以看到哪些特征对模型的预测起到了重要作用,并且了解这些特征值的大小如何影响预测结果。这有助于更深入理解模型的决策过程,也可以用于后续特征优化和模型调试。
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











