







1 autograd
1.1 requires_grad
tensor中会有一个属性requires_grad 来记录之前的操作(为之后计算梯度用)。

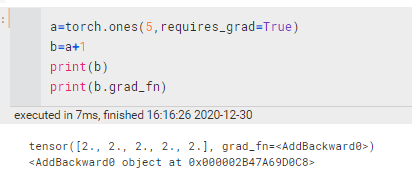
1.1.1 requires_grad具有传递性
如果:x.requires_grad == True,y.requires_grad == False , z=f(x,y)
则, z.requires_grad == True
1.1.2 继承自nn.Module的网络参数requires_grad为True
- 对于继承自 nn.Module 的某一网络 net 或网络层, 默认情况下,net.paramters 的 requires_grad 就是 True 的
- 当
x.requires_grad == False,y = net(x)后, 有y.requires_grad仍然是True
import torch
a=torch.tensor([1.0,2.0,3.0],requires_grad=False)
net=torch.nn.Linear(3,2)
net(a)
#tensor([-0.1099, -0.9108], grad_fn=<AddBackward0>)1.1.3 固定网络中部分参数(不训练之)
for p in sub_module.parameters():
p.requires_grad = False1.2 调整tensor的requires_grad


1.3 with torch.no_grad
在这个环境里面里面生成的式子将无requires_grad

1.4 detach
内容不变,但是requires_grad将变为False
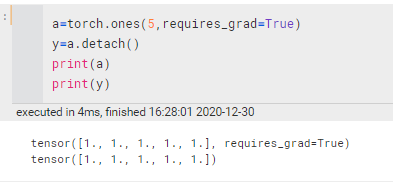
- x' = x.detach 表示创建一个与 x 相同,但requires_grad==False 的variable, (实际上是把x’ 以前的计算图 grad_fn 都消除了),x’ 也就成了叶节点。
- 原先反向传播时,回传到x时还会继续,而现在回到x’处后,就结束了,不继续回传梯度求导了【x‘不在计算图中】
1.5 应用:使得某一些参数不参与后续的training
以pytorch笔记——简易回归问题_UQI-LIUWJ的博客-CSDN博客作为主体框架
在训练之前,我们先看一下hidden和predict的参数值是多少
for i in net.hidden.parameters():
print(i)
'''
Parameter containing:
tensor([[-0.2888],
[-0.2389],
[-0.3877],
[ 0.2515],
[ 0.1307],
[ 0.5521],
[ 0.3613],
[ 0.7599],
[-0.3287],
[-0.1274]], requires_grad=True)
Parameter containing:
tensor([-0.3887, -0.7704, 0.7803, 0.0916, -0.7235, 0.8853, 0.7765, -0.0801,
-0.0436, -0.5459], requires_grad=True)
'''
for i in net.predict.parameters():
print(i)
'''
Parameter containing:
tensor([[-0.2602, -0.1613, 0.1053, -0.1850, 0.2115, 0.2834, -0.1664, -0.2687,
0.1320, 0.2407]], requires_grad=True)
Parameter containing:
tensor([-0.0537], requires_grad=True)
'''然后我们关闭 hidden的参数训练
for i in net.hidden.parameters():
i.requires_grad=False然后同样进行100个epoch的训练,然后看一下 hidden和predict的参数情况
for i in net.hidden.parameters():
print(i)
'''
Parameter containing:
tensor([[-0.2888],
[-0.2389],
[-0.3877],
[ 0.2515],
[ 0.1307],
[ 0.5521],
[ 0.3613],
[ 0.7599],
[-0.3287],
[-0.1274]])
Parameter containing:
tensor([-0.3887, -0.7704, 0.7803, 0.0916, -0.7235, 0.8853, 0.7765, -0.0801,
-0.0436, -0.5459])
'''
for i in net.predict.parameters():
print(i)
'''
Parameter containing:
tensor([[-0.2602, -0.1613, 0.3318, 0.0402, 0.2115, 0.1682, -0.2213, 0.7303,
0.6593, 0.2407]], requires_grad=True)
Parameter containing:
tensor([0.0501], requires_grad=True)
'''可以看到hidden的参数确实没有变化
2 Variable
一般pytorch里面的运算,都是Variable级别的运算

Variable 计算时, 它一步步默默地搭建着一个庞大的系统, 叫做计算图(computational graph)。
这个图是将所有的计算步骤 (节点) 都连接起来。最后进行误差反向传递的时候, 一次性将所有 variable 里面的修改幅度 (梯度) 都计算出来, 而 普通的tensor 就没有这个能力。
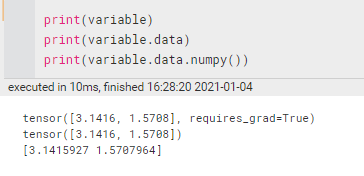
2.1 获取variable里面的数据
直接print(variable)只会输出 Variable 形式的数据, 在很多时候是用不了的(比如想要用 plt 画图), 所以我们要转换一下, 将它变成 tensor 形式,或者ndarray形式等。
3 autograd 流程
- 能获取回传梯度(grad)的只有计算图的叶节点。(注意是获取,而不是求取)。
- 中间节点的梯度在计算求取并回传之后就会被释放掉,没办法获取
- 只有标量才能直接使用 backward(),即
loss.backward(), pytorch 框架中的各种nn.xxLoss(),得出的都是minibatch 中各结果 平均/求和 后的值
3.1 无梯度的叶子节点’
import torch
a = torch.tensor(2.0)
b = torch.tensor(3.0)
c = a*b
c.backward()
a.grad,b.grad
'''
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
'''前项的计算图如下:
每个方框代表一个tensor,其中列出一些属性(还有其他很多属性):

| data | tensor的data |
| grad | 当计算gradient的时候将会存入此函数对应情况下,这个tensor的gradient |
| grad_fn | 指向用于backward的函数的节点 |
| is_leaf | 判断是否是叶节点 |
| requires_grad | 如果是设为 如果为 在上图中,此时由于requires_grad都为False,因此没有backwards的graph. |
3.2 有梯度的叶子节点
a = torch.tensor(2.0,requires_grad=True)
b = torch.tensor(3.0)
c = a*b
c.backward()
a.grad,b.grad
#(tensor(3.), None)前馈流程图如下:

3.2.1 backward 后馈流程图
1) 当我们调用tensor的乘法函数时,同时调用了隐性变量 ctx (context)变量的save_for_backward 函数。这样就把此函数做backward时所需要的从forward函数中获取的相关的一些值存到了ctx中。
ctx起到了缓存相关参数的作用,变成连接forward与backward之间的缓存站。
ctx中的值将会在c 做backwards时传递给对应的Mulbackward 操作.
2) 由于c是通过 c=a*b运算得来的, c的grad_fn中存了做backwards时候对应的函数.且把这个对应的backward 叫做 “MulBackward”
3) 当进行c的backwards的时候,其实也就相当于执行了 c = a*b这个函数分别对 a 与b 做的偏导。
那么理应对应两组backwards的函数,这两组backwards的函数打包存在 MulBackward的 next_functions 中。
next_function为一个 tuple list, AccumulateGrad 将会把相应得到的结果送到 a.grad中和b.grad中
4) 于是在进行 c.backward() 后, c进行关于a以及关于b进行求导。
由于b的requires_grad为False,因此b项不参与backwards运算(所以,next_function中list的第二个tuple即为None)。
c关于a的梯度为3,因此3将传递给AccumulaGrad进一步传给a.grad
因此,经过反向传播之后,a.grad 的结果将为3
3.3 稍微复杂一点的
a = torch.tensor(2.0,requires_grad = True)
b = torch.tensor(3.0,requires_grad = True)
c = a*b
d = torch.tensor(4.0,requires_grad = True)
e = c*d
e.backward()
a.grad,b.grad,d.grad
#(tensor(12.), tensor(8.), tensor(6.))
- e的grad_fn 指向节点 MulBackward, c的grad_fn指向另一个节点 MulBackward
- c 为中间值is_leaf 为False,因此并不包含 grad值,在backward计算中,并不需要再重新获取c.grad的值, backward的运算直接走相应的backward node 即可
- MulBackward 从 ctx.saved_tensor中调用有用信息, e= c+d中 e关于c的梯度通过MulBackward 获取得4. 根据链式规则, 4再和上一阶段的 c关于 a和c关于b的两个梯度值3和2相乘,最终得到了相应的值12 和8
- 因此经过backward之后,a.grad 中存入12, b.grad中存入 8
参考资料:【one way的pytorch学习笔记】(四)autograd的流程机制原理_One Way的博客-CSDN博客
















 3628
3628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











