







1 学习率的大小

2 Adagrad
2.0 motivation
- 对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;
- 对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些
- 怎么样去度量历史更新频率呢?那就是二阶动量

- 参数更新越频繁,二阶动量越大,学习率就越小
2.1 Adagrad结论

2.2 Adagrad推导
g不变
η随着t的增加而减少
σ是之前梯度的均方根



3 Adagrad的优缺点
3.1 优点
可以动态调整学习率,因而相比于SGD来说,可以更少地进行手动对学习率的调参
3.2 缺点
- 如果我们把
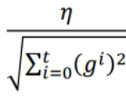 视为学习率的话,那么学习率会很快降到一个很小的值,之后会很慢收敛了。
视为学习率的话,那么学习率会很快降到一个很小的值,之后会很慢收敛了。 - η的值需要认为指定,如果设置的太大的话,就会发生震荡;太小的话全局学习率又会较低
















 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











