







1 VAE 介绍
- 在机器学习笔记:auto encoder_UQI-LIUWJ的博客-CSDN博客 中,我们知道了auto-encoder。但是auto-encoder有一个不足之处,就是因为auto-encoder不是一个概率模型,所以没法从学习的模型中生成新的数据,或者说我们train了一个模型,得到的输出是固定不变的。
- 传统的auto-encoder的另一个问题是自编码器学习到的潜在空间不是连续的,所以空间中的点含义没有平滑的过度,即使一个小的扰动点也会导致垃圾输出。
- 如果使用auto-encoder作为生成模型的话,会存在如下问题:
- 不知道如何从一个不规则的、无界的空间中采样
- 学习空间是不连续的
- 一些类可能在潜空间中被过度表示
- 如果使用auto-encoder作为生成模型的话,会存在如下问题:
在这种情况下VAE就诞生了:它引入随机性、约束潜在空间,以达到:
1)从原始数据中学习特征表示向量z
2)可以从模型中生成新的数据
作用(2)是auto-encoder中所不具备的
2 decoder介绍
训练完成后,decoder可以是这样的:
我们知道z的先验概率,decoder又学习了一个从z到x的条件概率,那么我们就可以求得x的概率,然后进行采样即可
更进一步说,decoder需要学习到x|z的均值和方差,这样才可以预测p(x|z)


2.1 decoder 训练
那么,如何训练这个模型呢?基本想法是最大化数据的概率
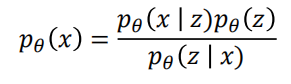
其中
的计算可以由下获得:
是由decoder获得
是由z的先验概率求得(我们这里认为z满足高斯分布)
- 至于
,我们可以由encoder获得



3 encoder 与 decoder
区别于AE,VAE不是将输入图像映射到潜在空间中的一个点,而是将其映射到一个分布中,准确地说是多元正态分布
于是我们有:



4 目标函数推导
(贝叶斯法则)
(分子分母同乘)
(log的规则)
而我们知道,x最终的分布和z是无关的。因此有:

于是:
(取期望)

而因为KL散度是大于等于0的,所以我们可以去掉最后一项,这样可以得到一个下界:
分别是encoder学习的效果和decoder学习的效果
5 VAE举例

从 encoder的输出(均值,方差)到decoder的输入的过程,是一个采样的过程;decoder的输出也是一个采样的过程,因此每一次VAE的输出都不一样。这样就可以生成不同的新数据了
6 VAE的流程
6.1 training
我们一步一步再看一遍:







通过最大化的概率,对encoder和decoder的参数进行优化
6.2 generating data



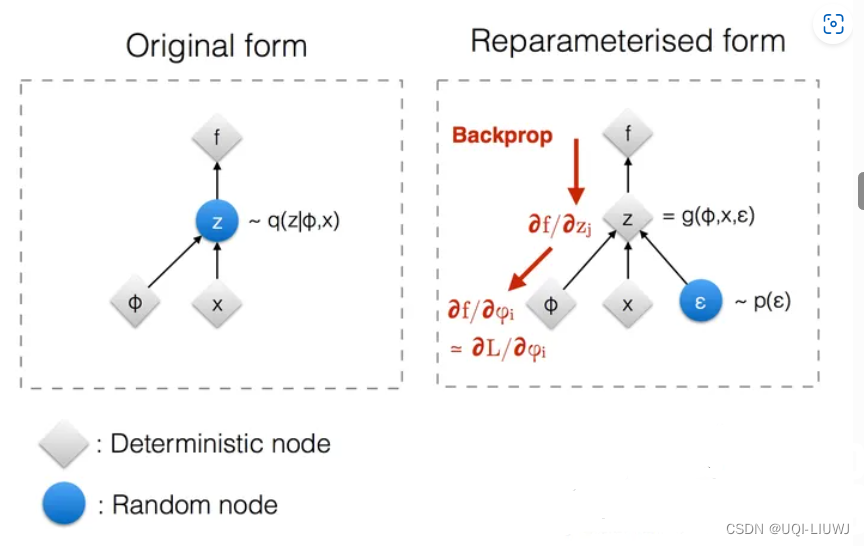
7 Reparameterization Trick
VAE的损失函数中:

- 期望项涉及
生成的样本
- 采样是一个随机的过程,因此我们不能反向传播梯度
- 为了使其可训练,引入了重新参数化(reparameterization)的技巧
- 将随机变量z表示为确定性变量
- ε是一个辅助的独立随机变量
- 将随机变量z表示为确定性变量
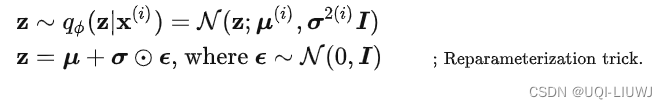
8 为什么VAE可以工作?
- 对于一个相同的图像,每次都会在潜在空间中得到一个稍微不同的点(尽管它们都在均值附近)。这使得 VAE 了解该邻域中的所有点在解码时都应该产生类似的输出。这确保了潜在空间是连续的
9 VAE的作用
9.1 异常检测
- 在异常检测中,VAE被训练来重建正常数据的分布。当输入一个异常数据时,由于它与训练数据的分布不符,VAE重建的效果会较差。
- 我们可以通过测量输入数据和重建数据之间的差异(例如,使用重建误差)来检测异常。
- 差异较大通常表明输入数据是异常的。
9.2 去噪
- VAE也可以用于去噪。在这种情况下,VAE被训练以从带噪声的数据中重建干净的数据。
- 训练过程中,模型学习如何识别并忽略输入数据中的噪声,从而能够生成去噪后的输出。
9.3 生成合成数据
- 一旦训练完成,我们可以通过操纵潜在空间(即模型内部的隐含表示)来生成新的数据实例
- 这种方法常用于生成逼真的图像、音频或其他类型的数据
















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











