







机器学习笔记:局部加权回归 LOESS_UQI-LIUWJ的博客-CSDN博客
1 基本使用方法
statsmodels.nonparametric.smoothers_lowess.lowess(
endog,
exog,
frac=0.6666666666666666,
it=3,
delta=0.0,
xvals=None,
is_sorted=False,
missing='drop',
return_sorted=True)LOWESS (Locally Weighted Scatterplot Smoothing) 局部加权回归
2 参数说明
| endog | 一维ndarray 观测点的y值 |
| exog | 一维ndarray 观测点的x值 |
| frac | 0到1之间的float型数据 估计每个 y 值时使用的数据比例。(用这个范围内的点进行局部加权回归) |
| it | 进行几轮局部加权回归 |
| delta | float型数据 间隔多少进行一次局部参数回归(中间的点使用线性插值) |
| is_sorted | 布尔型数据 如果为 False(默认),则数据将在计算 lowess 之前按 exog 排序。 如果为 True,则假定数据已按 exog 排序。 如果指定了 xvals,那么如果 is_sorted 为 True,则也必须对其进行排序。 |
| missing | 可用选项为“none”、“drop”和“raise”。 如果为“none”,则不进行 nan 检查。 如果“drop”,则任何带有 nan 的观察都将被删除。 如果“raise”,则nan会引发错误。 默认为“drop”。 |
| return_sorted | 布尔型变量 如果为 True(默认),则返回的数组按 exog 排序,并删除了缺失的(nan 或无限)观察。 如果为 False,则返回的数组与输入数组具有相同的长度和相同的观察序列。 |
3 返回值
如果 return_sorted 为 True,则返回的数组是二维的,如果 return_sorted 为 False,则返回的数组是一维的。
如果 return_sorted 为 False,则仅返回估计值,并且观察值将与输入数组的顺序相同。(虽然我实验出来的也是二维)
4 工作原理
假设输入数据有 N 个点。 该算法通过根据 x 值,用 frac*N个 最接近的点 (x_i,y_i) ,并使用加权线性回归估计 y_i 。
(x_j,y_j) 的权值函数是应用于
的三次函数。
如果it > 1,则执行多轮加权局部线性回归,其中权值函数是二次函数。
每次迭代花费的时间与原始拟合大致相同,因此这些迭代很昂贵。
当噪声具有极重的尾部分布时(例如柯西噪声),多轮迭代是很有用的。
对于 具有较少重尾的噪声,例如 自由度>2 的 t 分布,问题较少。
delta 可用于节省计算。 对于每个 x_i,对于比 delta 更近的点,都会跳过回归。
下一个局部加权回归拟合 x_i 的 delta 范围内内的最远点,并且通过在两个回归拟合之间进行线性插值来估计其间的所有点。
对于大数据(N > 5000),明智地选择 delta 可以显着减少计算时间。 一个不错的选择是 delta = 0.01 * range(exog)。
5 使用举例
import numpy as np
import statsmodels.api as sm
lowess=sm.nonparametric.lowess
###数据集
x = np.random.uniform(low = -2*np.pi,
high = 2*np.pi,
size=500)
#[-2Π,2Π]之间的均匀分布,一共500个点
x=np.sort(x)
y = np.sin(x) + np.random.normal(size=len(x))
#sin(x),外加一些噪声
z=lowess(y,x,is_sorted=True)
z1=lowess(y,x,is_sorted=True,frac=1/3)
z2=lowess(y,x,is_sorted=True,it=0)
#进行局部加权回归 拟合
import matplotlib.pyplot as plt
plt.figure(figsize=(13,5))
plt.plot(y)
plt.plot(z[:,-1])
plt.plot(z1[:,-1])
plt.plot(z2[:,-1])
plt.legend(['origin',
'default(frac=2/3,it=3,delta=0)',
'(frac=1/3,it=3,delta=0)',
'(frac=2/3,it=0,delta=0)'])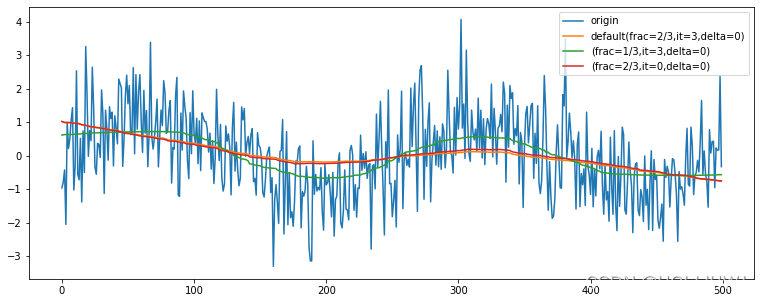
可以发现,frac越大,越平滑
在这种噪声不具有长尾的情况下,迭代几轮影响不大


















 4017
4017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











