







 本文探讨了如何通过退一步提示法提升大语言模型(LLM)的性能,特别是在STEM领域的实验,如MMLU测试。研究发现这种方法在处理抽象问题和推理时存在挑战,尤其是推理错误和数学错误。同时,文章分析了KnowledgeQA和Multi-HopReasoning任务中的表现与优化策略。
本文探讨了如何通过退一步提示法提升大语言模型(LLM)的性能,特别是在STEM领域的实验,如MMLU测试。研究发现这种方法在处理抽象问题和推理时存在挑战,尤其是推理错误和数学错误。同时,文章分析了KnowledgeQA和Multi-HopReasoning任务中的表现与优化策略。
ICLR 2024 reviewer 打分 888
1 论文思路
- 思路很简单,在进行prompt的时候,先后退一步,从更宏观的角度来看问题,让LLM对问题有一个整体的理解;然后再回到detail上,让模型回答更具体的问题
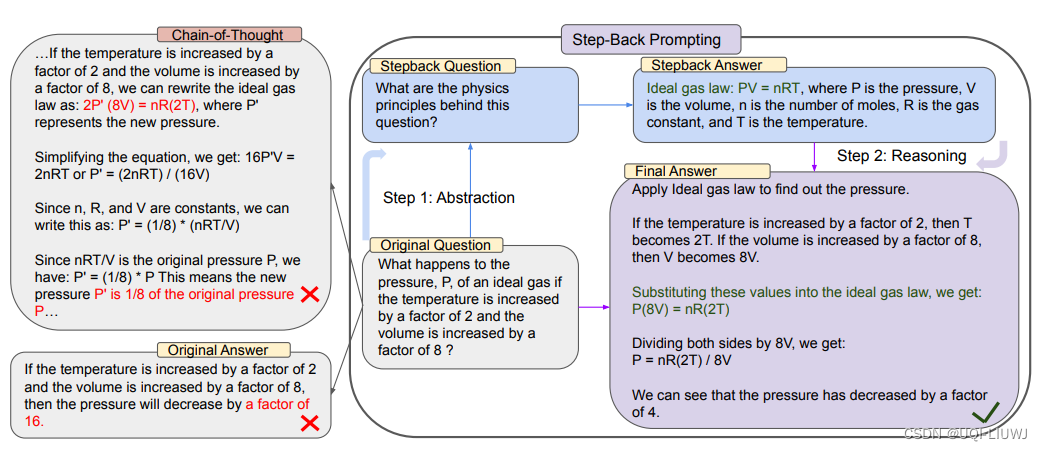
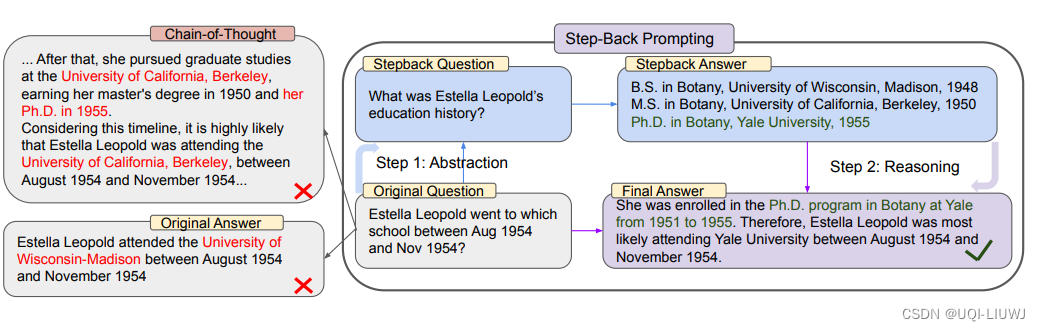
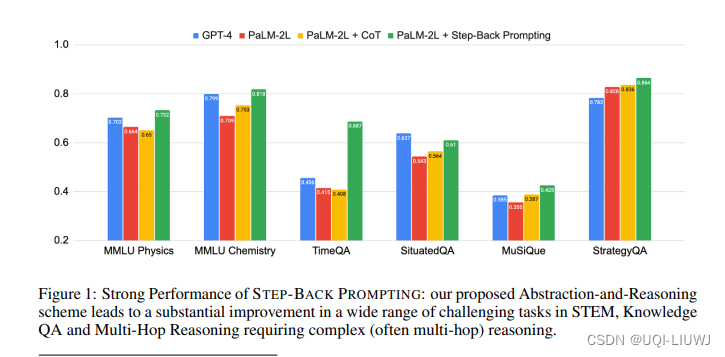
2 实验——STEM
MMLU 高中物理和化学基准测试
2.1 实验效果
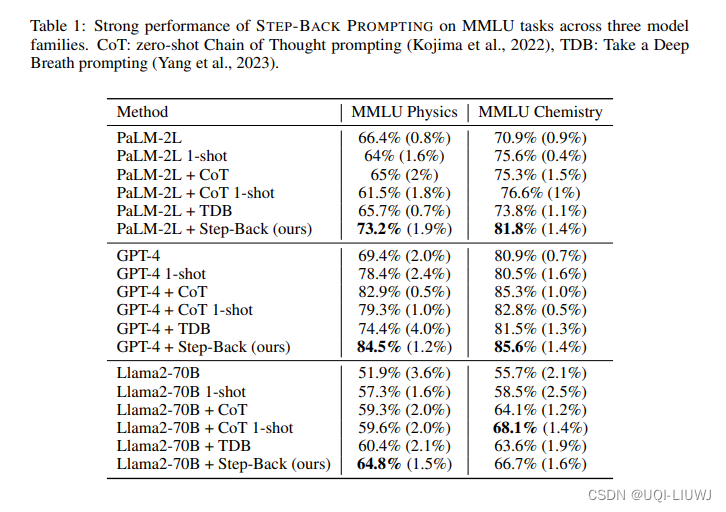
2.2 few-shot 例子数量的影响
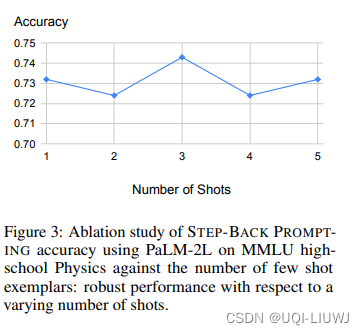
2.3 错误案例分析
- 原则错误:错误发
ICLR 2024 reviewer 打分 888
MMLU 高中物理和化学基准测试

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


























