







1 LSTM复习
机器学习笔记 RNN初探 & LSTM_UQI-LIUWJ的博客-CSDN博客
机器学习笔记:GRU_UQI-LIUWJ的博客-CSDN博客_gru 机器学习
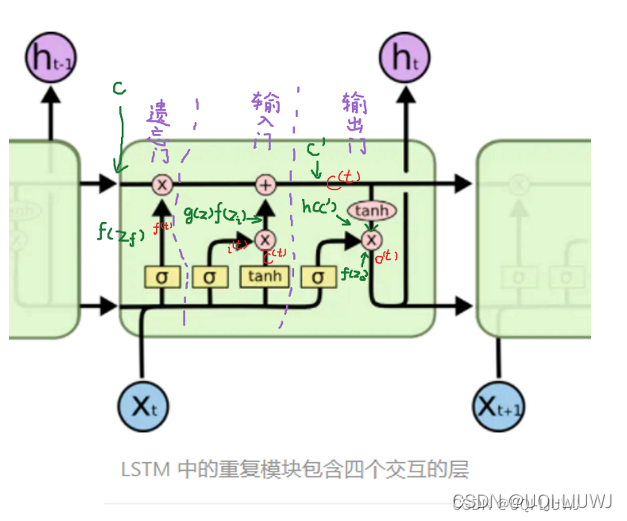

2 PeepholeLSTM
有的地方也叫做FC-LSTM?
就是计算输入门、遗忘门和输出门 的时候,我们不仅仅考虑h和x,还将C考虑进来
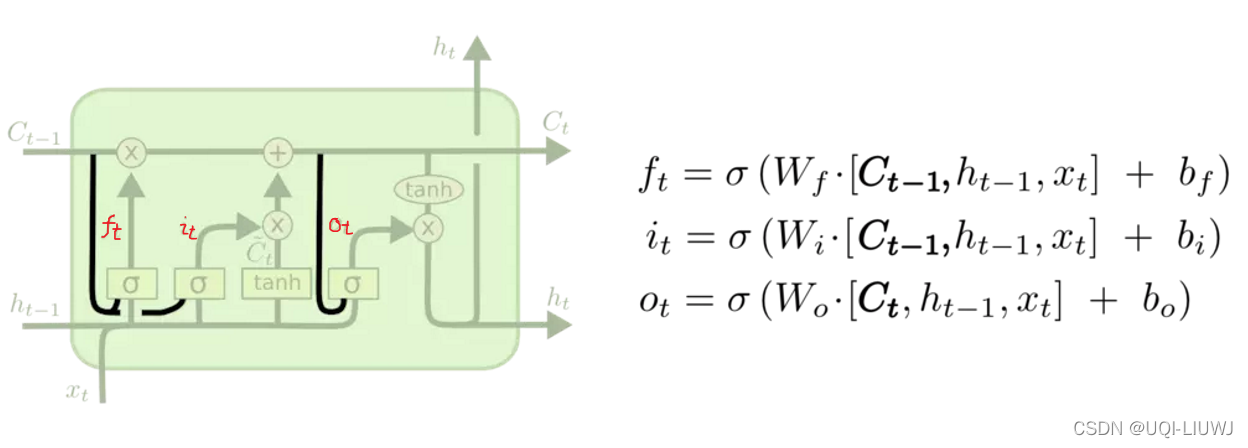
其他的三项不变
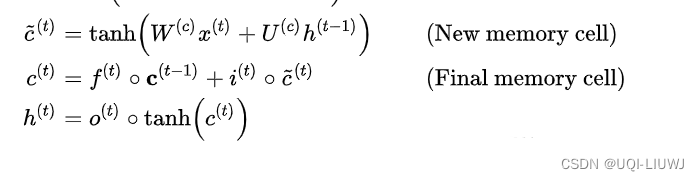
3 coupled LSTM
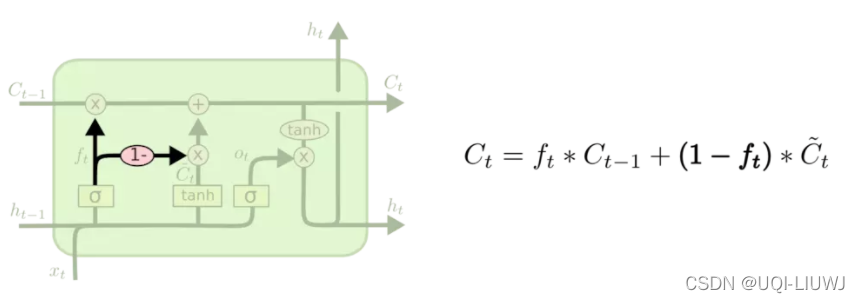
输入门和遗忘门二合一
4 Conv LSTM
为了构建时空序列预测模型,同时掌握时间和空间信息,所以将LSTM中的全连接权重改为卷积
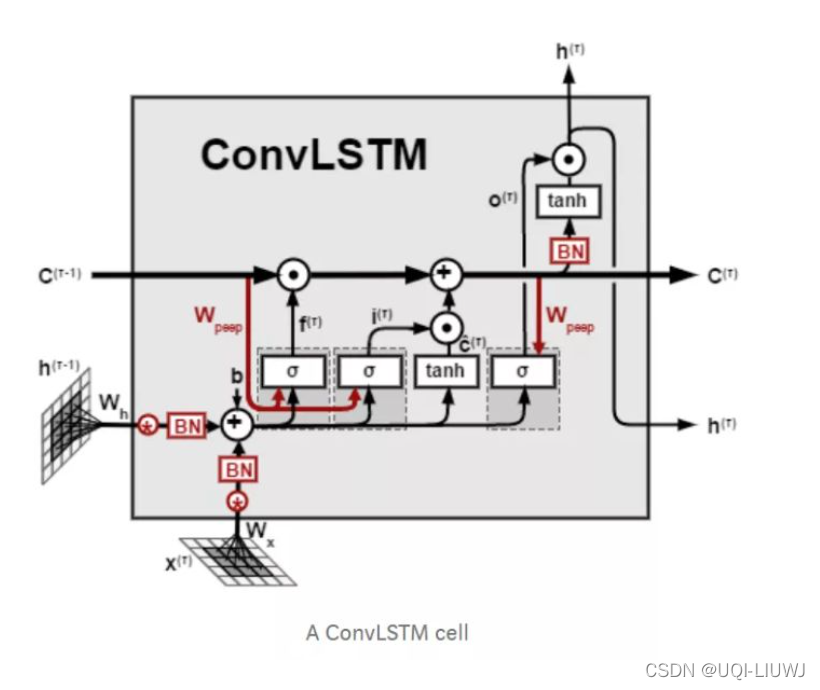
可以看到conv LSTM中也使用了peephole LSTM的结构——cell部分也用于遗忘门和输入门的计算
于是我们有如下的计算流程(这里我之前理解错了,谢谢评论区批评指正!)
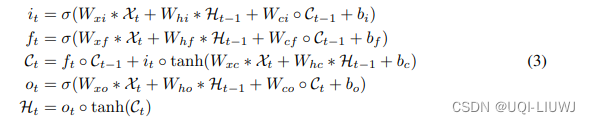
在这里*表示 卷积操作 ●表示哈达玛积
对于conv-LSTM,输入是![]() ,w是时间窗口,a,b是 grid的尺寸;k是特征数量
,w是时间窗口,a,b是 grid的尺寸;k是特征数量
另一种convLSTM的理解方法是,我们普通的LSTM可以看成最后两个维度都是1 的ConvLSTM,其中卷积核大小为1×1
4.1 ConvLSTM VS CNN+LSTM
对于时间序列预测问题而言,一般来说不存在conLSTM的结构,因为对于convlstm来说,输入是矩阵形式的,即每一个时间步都是一个矩阵输入(例如视频分类问题),而典型的时间序列预测的每一个时间步输入是一个向量(多变量时间序列预测)或一个标量(单变量时间序列预测)。
因此在时间序列预测中,一般是使用conv1d+lstm的方式来做,例如输入是一个长度为10的sequence,经过conv1d(padding)之后仍旧是长度为10的sequence,然后这个sequence再送入LSTM,cnn作为滤波器存在,cnn和lstm的网络结构是完全独立的;
cnn+lstm是无法直接处理视频问题的,因为视频的每一个时间步是一张图像,不考虑多通道问题则至少是一个矩阵,而LSTM中,输入部分和上一个时间步的hidden state的传入部分一般来说是向量。
4.2 图示ConvLSTM
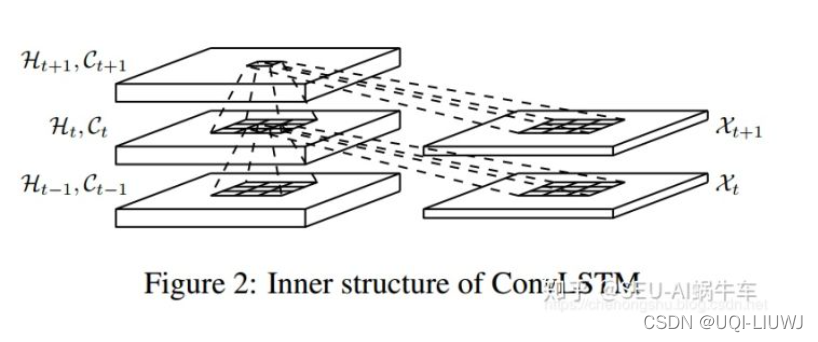
换言之,我们可以理解为,H,C以及sequence的每个元素X都是三维的tensor,每次我们都是用卷积操作来生成下一个sequence的H和C
5 ConvGRU
和Conv-LSTM类似,也是*表示 卷积操作 ●表示哈达玛积
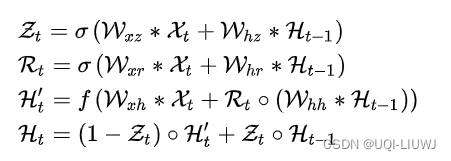
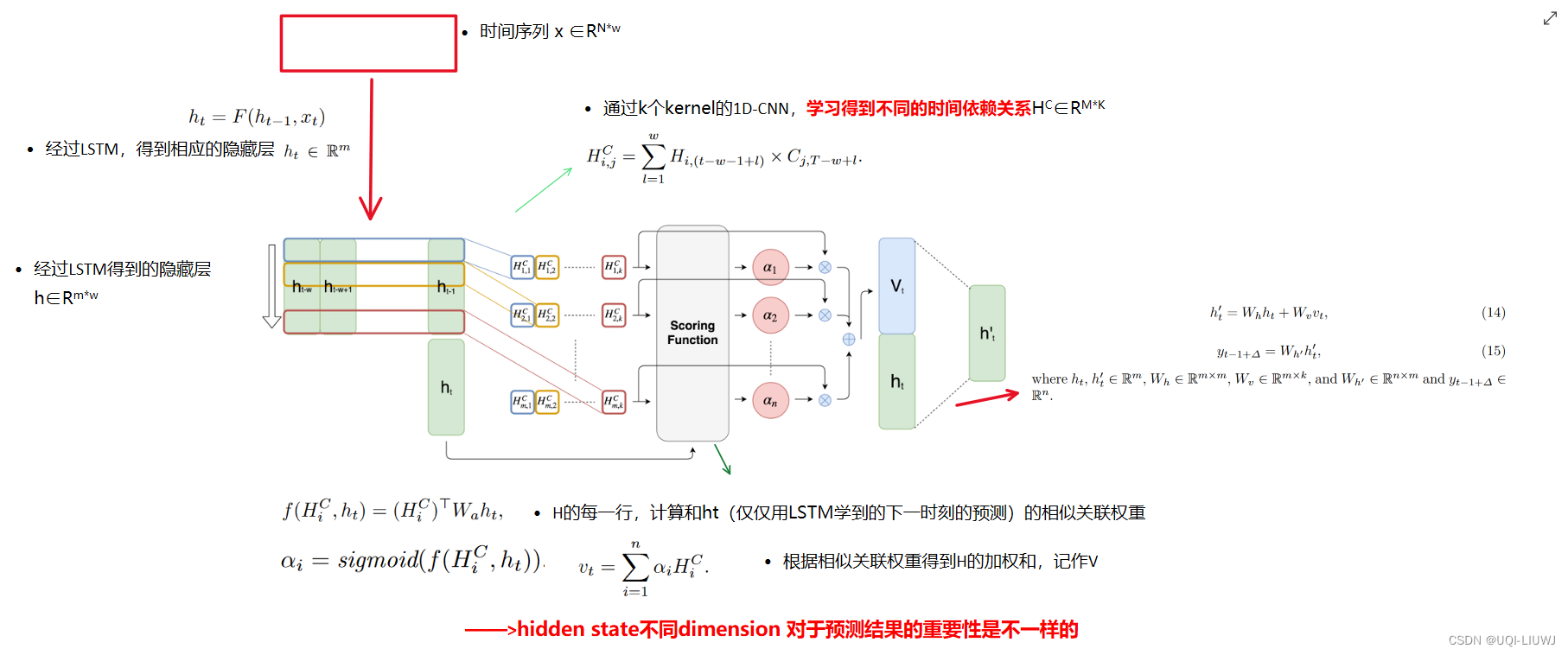
6 TPA-LSTM
- 在LSTM的基础上,强调了hidden state的不同dimension对某个dimension预测的重要性是不一样的
- 比如下图,原油(crude oil)和Gasoline之间的关联度很大,和Lumber关联度很小

- 而传统LSTM/时间维度的attention并没有考虑到这个channel之间的重要性
- ——>通过引入channel-wise attention,提高LSTM的预测精度
- 比如下图,原油(crude oil)和Gasoline之间的关联度很大,和Lumber关联度很小
参考文献
【串讲总结】RNN、LSTM、GRU、ConvLSTM、ConvGRU、ST-LSTM - 知乎 (zhihu.com)


















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











