







ICLR 2024 (oral) reviewer评分 888
1 intro
1.1 背景——大模型在知识密集任务中的挑战
- 大模型已经展示出在模型参数中编码世界知识的能力
- 然而,它们在知识密集型任务和环境中仍面临各种挑战:
- 容易产生幻觉
- 难以编码长尾事实
- 不能轻松更新新兴知识
- 然而,它们在知识密集型任务和环境中仍面临各种挑战:
1.2 目前的方法
- 现有方法通过检索增强或生成知识提示来解决这些限制
- 检索增强
- 利用检索系统从通用且固定的检索语料库(例如维基百科)中提取相关文档
- 利用非参数源的外部知识来帮助LLM生成
- 生成知识提示方法
- 提示LLMs合并和生成上下文文档,以鼓励具备知识感知的生成
- 检索增强
1.2.1 目前方法的不足
- 虽然目前方法取得了一些成功,但这些现有系统难以反映知识的两个关键属性
- 知识是模块化的:
- 它是一个“群岛”而不是一个单一的“大陆”,包含以多样化的形式、领域、来源、视角等存在的信息。
- 知识的缺乏模块化性使得难以将存储在LLMs中的知识推广到新领域和有针对性的更新
- 知识是协作的
- LLMs应该能够表示和整合来自多方面源头和视角的多样化和不断发展的知识,同时促使各方参与协同贡献
- 知识是模块化的:
1.3 论文的思路
- 提出了KNOWLEDGE CARD
- 通过整合更小但专业化的语言模型,为通用型LLMs赋予模块化和协作源的知识
- 越来越多强大的LLMs API已经发布,但是他们不直接可访问,并且训练或调整成本过高
- ——>KNOWLEDGE CARD专注于增强黑盒LLMs以丰富其知识能力
2 方法
2,1 总体思路
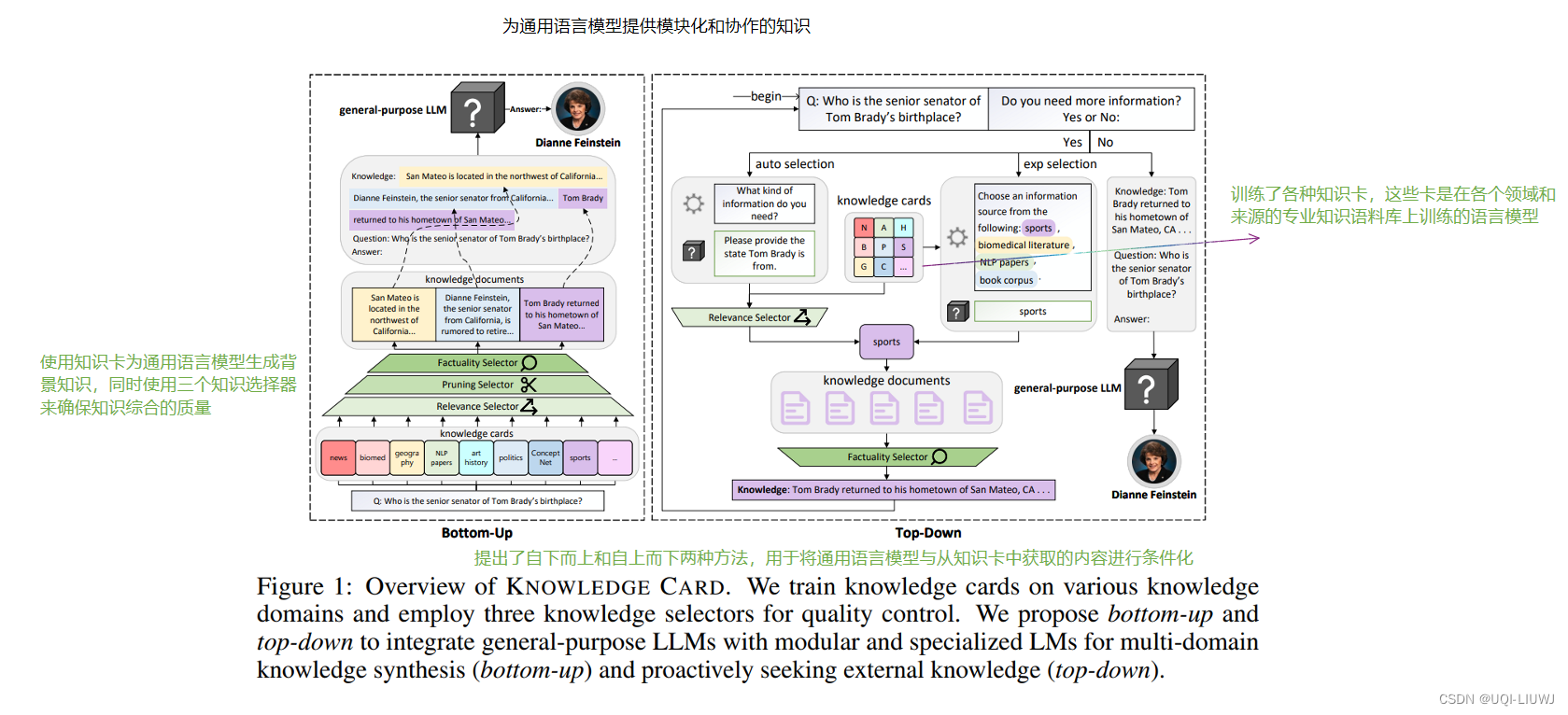
2.2 knowledge card

- 论文认为知识是模块化的,通用语言模型应该与模块化的即插即用知识存储库相结合,允许用户协作添加、删除、编辑或更新信息
- ——>论文创建知识卡片
- 这是一种专门的语言模型LM,比黑盒LLMs小得多
- 它们在来自多个领域和来源的多元化知识语料库上进行训练
-
具体来说,获得了n张知识卡片
,每一张都是从一个现有的语言模型cheakpoint开始,并在特定的知识语料库Di 上进一步训练【causal language modelling,也即自回归训练】
-
给定一个查询q到LLM,这些知识卡片被选择性激活并使用以生成提示回应
-
给定查询q,专门的LM定义了一个映射c(q):q → dq ,其中q被用作提示来生成知识文档dq的延续
-
-
通过这种方式,可以添加、移除或选择性激活不同知识卡片的方式,展示知识的模块化。
2.3 知识选择
- 在整合知识卡片和通用LLMs时,论文确定了三个关键挑战:相关性、简洁性和事实性
- 论文设计了三个相应的选择器来控制这些因素。
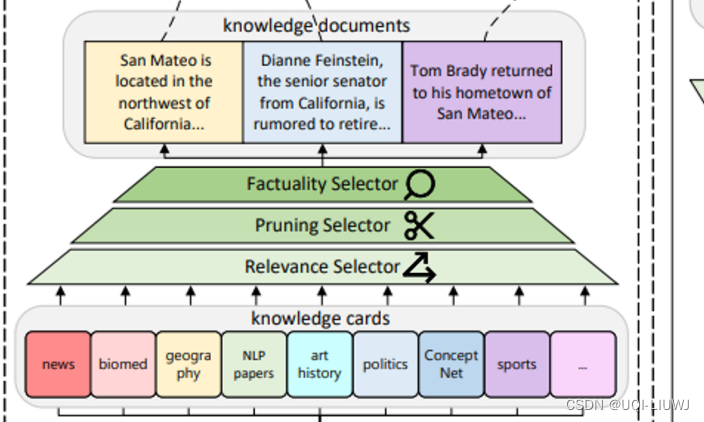
2.3.1 相关性选择 Relevance Selector
- 虽然期望知识卡片能生成与查询q相关且有帮助的背景信息,但LMs有时会偏离查询。
- 此外,只有少数知识卡片对于给定的查询是相关的。
- ——>论文提议根据相关性来选择和保留知识文档。
- 具体来说,给定一组由m个只是卡片生成的文档
和查询q,论文旨在保留最相关的top-k个文档并丢弃不相关的信息。
- 论文采用了一个单独的基于编码器的LM enc(·)来映射一个令牌序列到特征向量,同时使用余弦相似度sim(·,·)来衡量相关性。
- 形式上,如果 i ∈ top-k(sim(enc(dj), enc(q))),保留di
- 具体来说,给定一组由m个只是卡片生成的文档
2.3.2 简洁性选择 Pruning Selector
- 现有工作大多将一个外部知识片段整合到LLMs中
- 而需要整合多个信息领域的任务,并不完全受现有范例的支持。
- ——>为了有效地整合来自多个渠道生成的文档,论文对知识文档进行修剪【概括总结系统,使用之前的模型】
- 这种修剪方法允许知识文档更好地整合到主LLM版本中,同时保持信息内容的完整性。
2.3.3 贪婪事实性选择
- 语言模型容易出现“幻觉”,知识卡片也不例外。
- 给定一组m个修剪过的知识文档
,它们的原始版本为{ d 1 , . . . , d m } 以及查询q,滤除非事实性的知识并保留ℓ个文档。
- 具体而言,通过两个度量来评估知识文档的事实性
- 摘要的事实性
- 确保修建版本
在事实上捕捉了原始di中的重要要点
- 采用事实性评估模型sum-fact(·,·)作为评分函数【已有模型】
- 确保修建版本
- 事实检查分数
- 通过检索增强的事实检查来评估生成的知识文档是否得到实际世界知识的良好支持
-
对于给定的知识文档d,我们从检索语料库t1,. . .,tk 中检索k个文档,然后利用一个事实检查fact-check(·, ·)模型作为评分函数【已有模型】
-
-
对每个文档的摘要事实性分数和事实检查分数进行平均,以获得sd
-
- 通过检索增强的事实检查来评估生成的知识文档是否得到实际世界知识的良好支持
- 摘要的事实性
- 具体而言,通过两个度量来评估知识文档的事实性
-
贪婪地选择具有最高sd分数的ℓ个知识文档
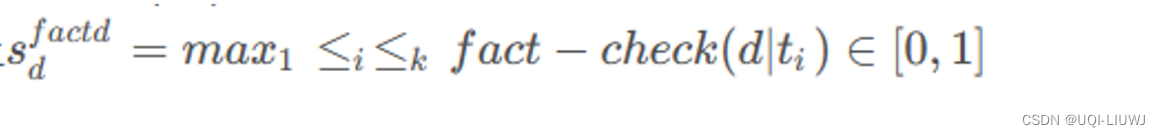
2.3.4 贪婪事实性选择的改进
- 虽然贪婪地选择具有最高sd分数的ℓ个知识文档是直观的,但新知识可能得不到现有事实检查工具的良好支持
- ——>提出了top-k事实性抽样,以在对明显错误的知识文档保持严格的同时提供一定的灵活性
- 首先获得
作为具有前k个事实性分数的知识文档集,其中k > ℓ是一个超参数
- 然后,在所有m个知识文档上定义一个采样概率分布
-
使用概率分布
中采样 ℓ 个知识文档
-
通过这种方式,严格排除了事实性得分非常低的知识文档,同时通过从得分接近顶部的知识中进行采样,增加了灵活性
-
- 首先获得
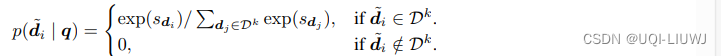
2.4 知识整合
- 提出了两种方法,用于将通用LLM与外部知识源整合。、
- bottom-up方法通过知识选择器来控制知识质量,启用多领域知识综合,
- top-down方法则在不总是需要外部知识的任务和领域中优势明显
2.4.1 自下而上
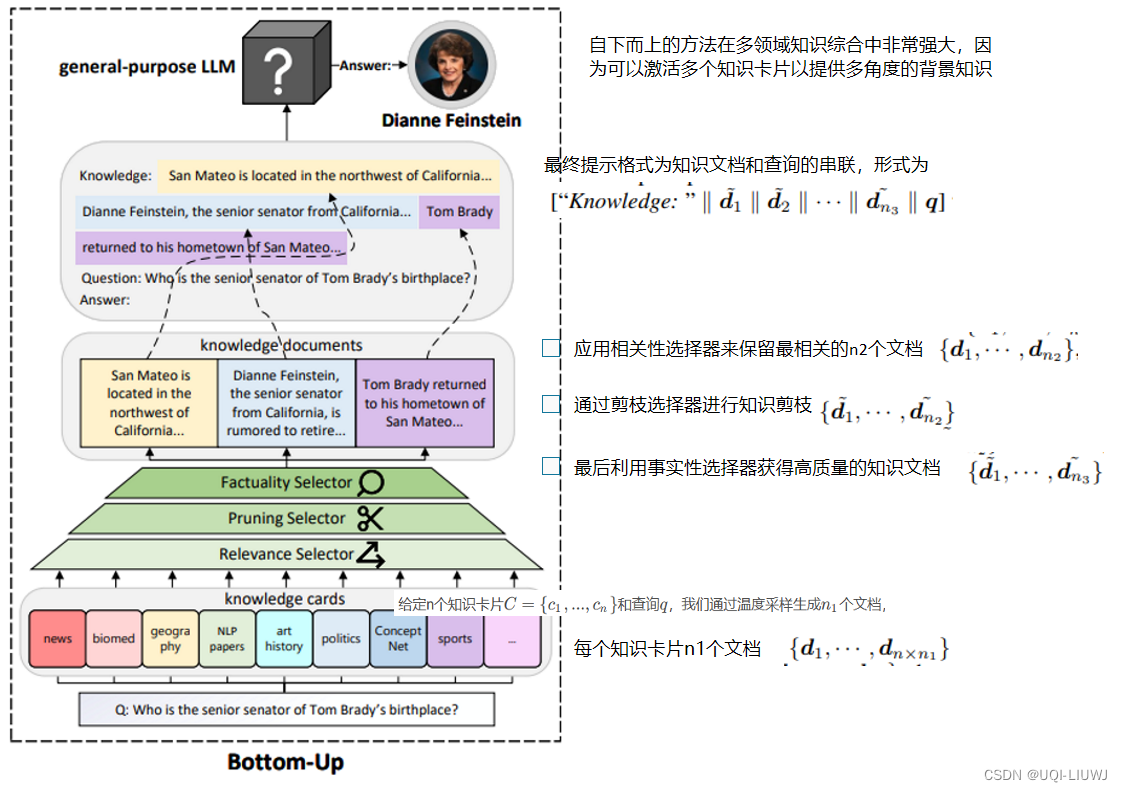
2.4.2 自上而下
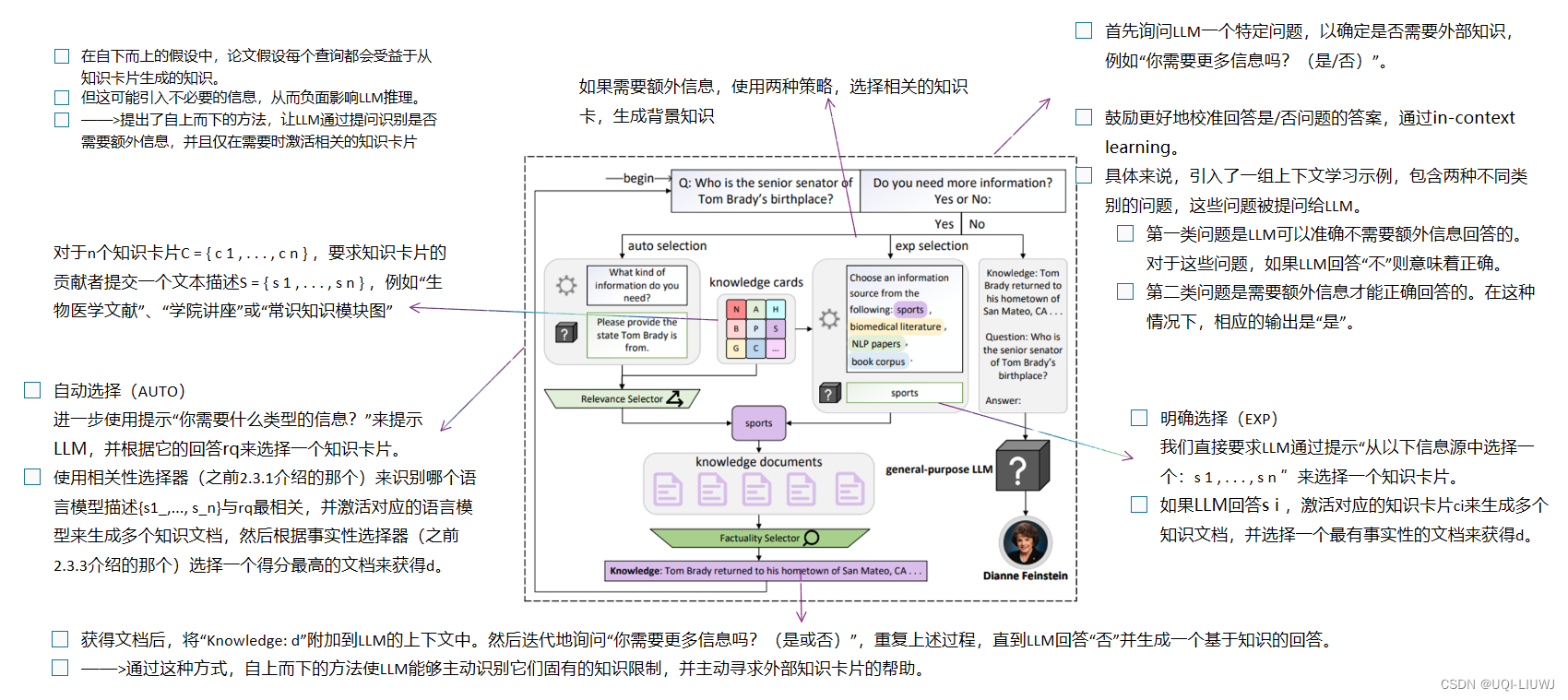
3 实验
3.1 效果比较
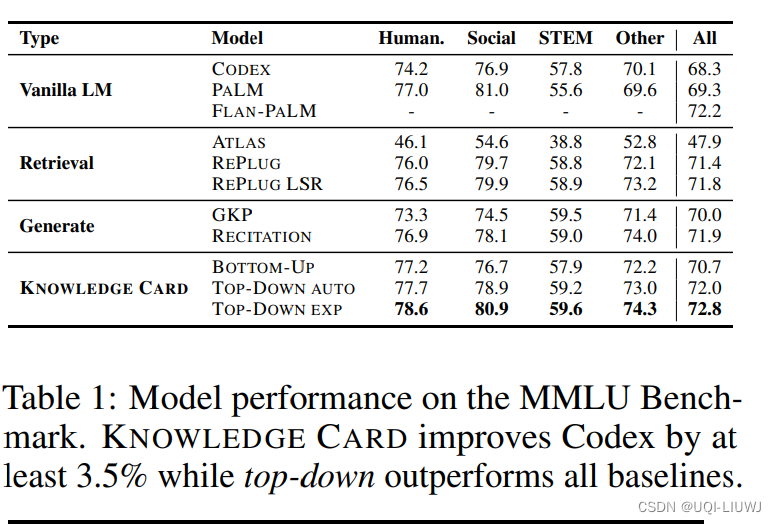
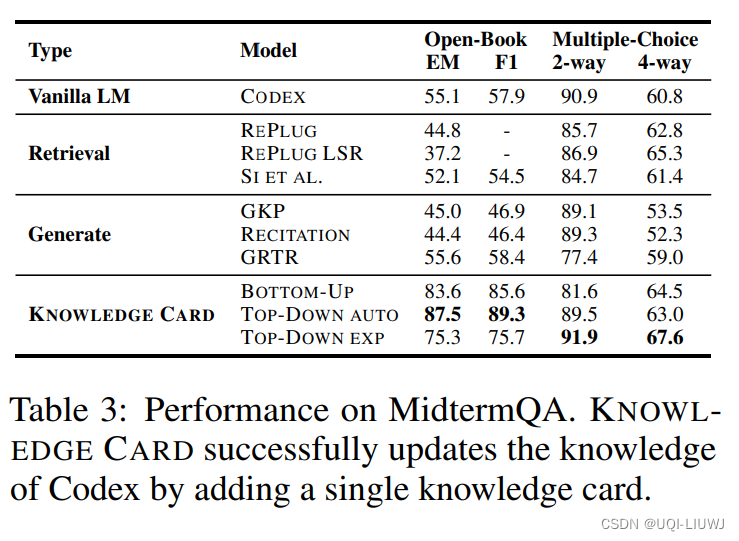
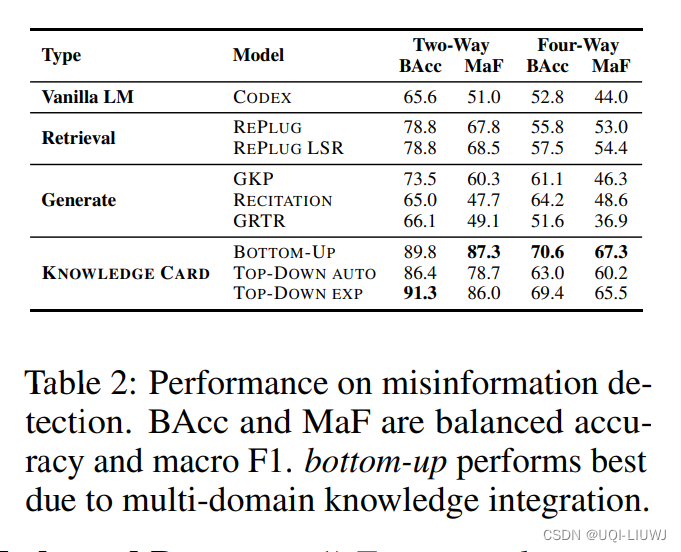
3.2 几种选择器的ablation study

3.3 n1,n2,n3的超参数敏感性
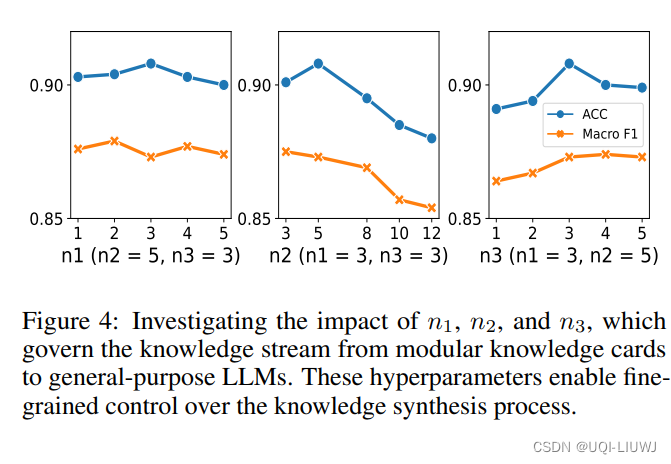
















 910
910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











