







背景
NVIDIA 已通过 NVLINK 证明片间互联能大幅提升算力的可扩展性(增效),而 Intel 和 AMD 正在尝试用 CXL 实现资源池化后对计算中心进行极致的成本管控(降本)。两种路径都将需要硬件层面的能耗、带宽和延迟表现有 1-3 个数量级的提升,硅光子学和互联 Chiplet 两个技术的组合将能成为突破瓶颈的关键。
产品现状
Ayar Labs 是一家用硅光子技术制造互联 Chiplet 的公司,其产品在硬件层面能提供比现有主流技术 1-2 个数量级的提升。其光信号互联芯片的面积带宽密度 (单位是 Gbps/mm2)是主流设备的 20 倍,延迟和能耗却只需要主流设备的 1/30 和 1/3 左右,并且产品在 2022 年已初步实现量产,其产品出色的性能吸引了 Intel 和 NVIDIA 的密切关注、以及多轮投资作为支持。
为什么弃铜缆选光纤?
由于能耗、扩展和迭代成本等问题,芯片和云计算巨头们普遍认为,如果要将计算中心的能力再扩展三个数量级,放弃铜缆网线、转向光纤是一个必然选择。从上世纪 90 年代开始,光纤已经被部署在较长距离的海底光缆和城际光缆中,随着设备体积和性能的优化,目前 3 米以上的通讯距离都已经大规模采用光缆而不是铜线了。
传统铜揽电线和光纤的性能表现差异:
• 能耗:铜缆的能耗通常是是光纤的 5 倍左右,下一代数据中心的高性能铜缆网线每传输 1 bit 的数据需要 20-30 pJ 的电量,而光缆则能做到 1-10 pJ 之间;
• 可拓展性:铜缆的最大互联距离是光纤的 1/100 左右。用铜线传输信息时,会因电阻的影响而受到信号的衰减和畸变。高性能铜缆网线的最大传输距离不超过小几十米,而光缆可以轻松支持 1 公里以上的距离,这显然意味着更强的算力扩展能力;
• 迭代成本:传统的数据中心互联网络每隔 2-3 年就要更换为更高性能的交换机,而谷歌内部自建光缆交换机 Jupiter 则能减少交换机的更新频率,从而每年为 GCP 节省下 30% 的硬件运营成本。
凭借能耗和可扩展性优势,光学元件(Optics)已经在数据中心的 Server-to-Server 互联进行渗透。诸多芯片和云计算巨头也基本转向 Optics 设备来改善服务器集群的能耗比:例如 Meta 的 VP of Infra 就透露 Meta 内部的 AI 训练服务器集群已基本采用 Optics,在 NVIDIA 的设计中,有望在 NVLINK 6.0-7.0 时实现从电信号向光信号的转化。
Chip-to-Chip 互联环节同样存在光学元件替换传统铜线通讯的需求,但对 Optics 的体积和成本提出了更进一步的要求,硅光子学的成熟成功解决了这部分问题,预计会成为 Chip-to-Chip 互联的主流解决方案。
光互联部件的发展
目前主流的光互联部件的形态为可插拔光模组(Pluggable Optics)。传统的可插拔光模组设计中涉及到大量的电和光元件(如下图示例),且部分元件的制作过程中还需要磷化铟和砷化镓等小众材料,实际生产中就会牵涉到不同的供应商,繁多的工艺和材料首先会导致产品成本高企,此外,这些部件之间依然使用电路板上的铜线通讯,所以最终产品从尺寸、性能和成本在短期内难以有较大突破。并且,由于每个部件的市场空间较小、涉及到的产业参与方众多,产品工艺制程的迭代也被拉慢。
Intel 力推的硅光子(Silicon Photonics)技术就是对可插拔光模组(Pluggable Optics)从工艺层面的改良。硅光子学技术简单说就是用硅片来构建光子收发器里的所有组件。不仅从原材料角度对传统设计中的不同元件材料进行替代、整合,制作上也复用了成熟的 CPU 制造工艺,这些都有效降低了光模块(Optical Module)的成本。
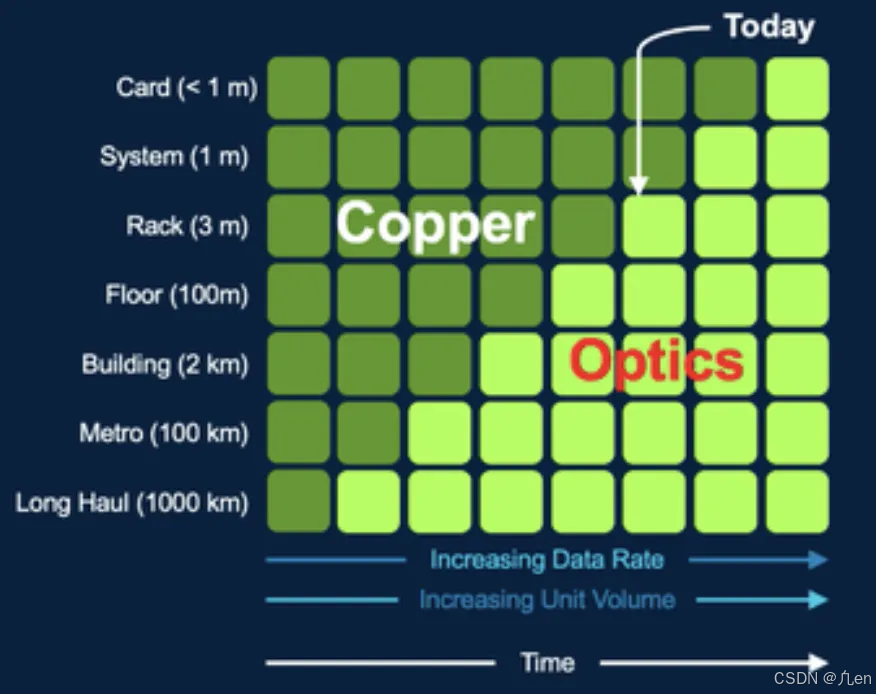
硅光子可插拔光学模组的升级替代不仅在于成本层面,它最大的价值在于满足片间通讯对收发器的密度和性能需求。传统可插拔光学模组解决的是 Floors/Racks/Systems 之间(> 1m)的光互联问题,但片间通讯(Card/Die,< 1m)对光子收发器的密度和性能要求更高,更短距离的互联需要进一步提升光子收发器的密度,从而部署在体积较小的显卡或是加速卡上,硅光子学的成熟让光子收发器的体积压缩从制作上成为可能,随着 Chiplet 技术的萌发,硅光子收发器更是能被直接安装在 Card/Die 旁,硅光子学模块有望在未来几年内渗透到这个计算中心的最后一米。
Chiplet 是近年来芯片设计最重要的技术路径突破,简单来说就是像 Lego 积木一样堆叠芯片,Chiplet 可以让芯片公司根据需求自己设计如何堆叠摆放多个芯片,再交由 TSMC 制造,比如 Apple 的 M1 Ultra 芯片就是依靠 Chiplet 技术将两块 M1 MAX 结合在一起。
在 Apple 和 AMD 前瞻地选择这一技术路径后取得巨大成功后,Chiplet 现在已成为芯片设计行业的主流技术路径。Chiplet 技术的成熟也为 Chip-to-Chip 互联设备提供了合理的产品形态,同时也解决了资源池化对传统架构下芯片到互联设备提出的带宽、延迟和能耗问题。
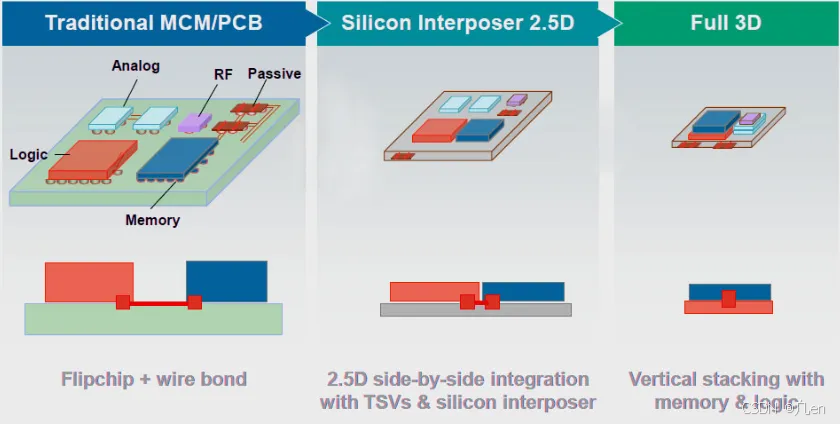
在过去,芯片(CPU、GPU 和内存)之间的通信依靠主板中埋设的铜线进行,芯片数量的增加就意味着需要设计更大的主板以支持更多芯片的互联,尽管在设计层面可以实现,但芯片之间通讯带宽、延迟和能耗已逐渐成为瓶颈。于是,TSMC 和 AMD 等芯片巨头提出以 Silicon Interposer 作为通讯介质, 从而拉近芯片之间的距离(如下方中图),甚至更近一步,允许芯片之间的堆叠(如下方右图),即 Chiplet,从而带来显著的全方位性能提升。Silicon Interposer 就是芯片堆叠过程中的“Lego 卡扣”。
Chiplet 同样也能够被运用到互联设备的设计上,从而提升互联设备的性能上限。 AI 服务器集群的现状:尽管他们的互联设备已从铜缆转向光缆,但是他们担心随着传输性能从 200GB/s 提升到 1200 GB/s 时,耗电量占比将从 10% 提升到 70%,互联设备的耗电量将远超现在最强超算的耗电量,也因此他们打算用 In-package/Co-package Optics(将在后文介绍) 解决这个问题,即将光互联设备缩小后,用 Chiplet 技术紧密地放在计算芯片旁边,从而改善互联性能、能耗和延迟问题。


















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









