






 本文探讨了一种利用频谱图和深度学习模型进行动作预测与渲染的技术。动作预测模块采用LatentDiffusionModel,通过频率正则化提高效率;动作渲染模块利用FeatureExtractor和SynthesisNetwork生成未来帧。实验基于大量自然场景视频,展示了光流提取和模型预测的性能。
本文探讨了一种利用频谱图和深度学习模型进行动作预测与渲染的技术。动作预测模块采用LatentDiffusionModel,通过频率正则化提高效率;动作渲染模块利用FeatureExtractor和SynthesisNetwork生成未来帧。实验基于大量自然场景视频,展示了光流提取和模型预测的性能。
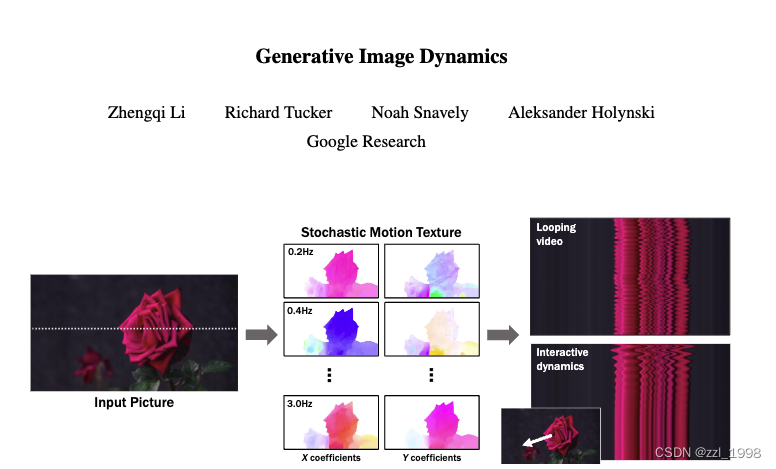
- 动作位移场
:描述图像中任意像素
,从首帧到第
帧的位移变化;
- 动作纹理
:用K个频率,表征任意像素
- 动作位移场:光流;
- 动作纹理:光流的频谱图,对像素点在T时间序列下的位移轨迹做FFT得到;
- 任务目标:给定图片,预测其未来T帧的震荡变化
- 给定图片,预测K个频谱图; -> 动作预测模块
- 给定频谱图,通过逆傅立叶变换得到光流;
- 给定光流,渲染未来T帧。 -> 渲染模块
目录
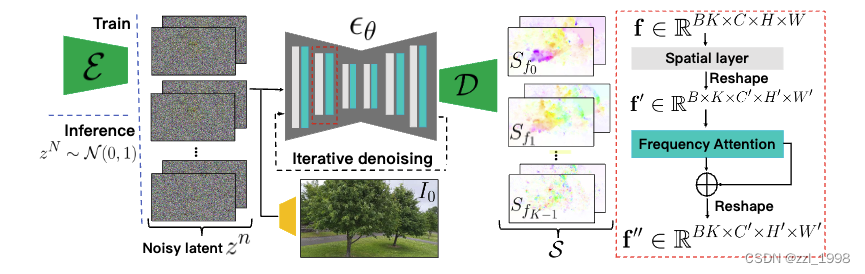
动作预测模块
Latent Diffusion Model:类似Stable Diffusion的VAE结构,降低频谱图分辨率,提高学习效率;
训练过程:以输入图片和频率作为控制信号,学习频谱分布;
频率正则化:考虑到Diffusion的学习值域在[0, 1],因此用傅立叶系数的97%幅值作为正则项;
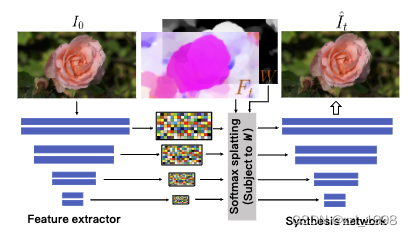
动作渲染模块
- Feature Extractor:基于ResNet-34提取多层图片特征;
- Synthesis Network:类StyleGAN结构
- 根据t时刻光流图warp图片特征;
- warp后的图片特征作为控制信号,生成t时刻渲染图像;
实验
- 准备训练数据:
- 数据:自然震荡视频2631个,包含:树、花、蜡烛等物体;
- 分段:每10帧作为开始帧,每段包含150帧,处理后总共包含130K段;
- 光溜:提取每段首帧到之后149帧的光流;
- 在16张A100上训练6天
- 结果可视化:

- 预测光流可视化

- 消融实验

















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









